

Question: using MNIST data set, I have 1000 train samples, 1984 test samples, x_train shape: (1000, 784) and y_train shape: (1000,) now how I will reshape
using MNIST data set, I have
1000 train samples, 1984 test samples, x_train shape: (1000, 784) and y_train shape: (1000,)
now how I will reshape the weight vector (w) and plot resulting "weight image" by using LDA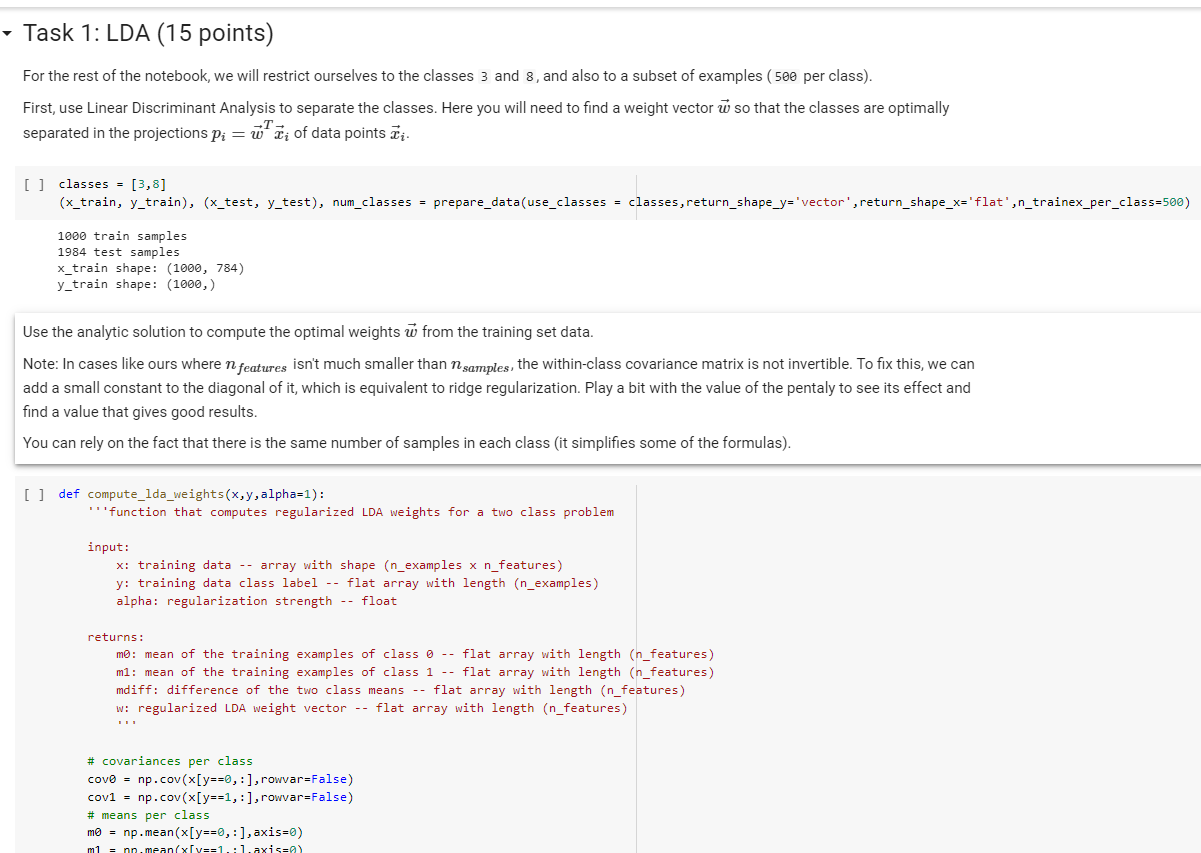
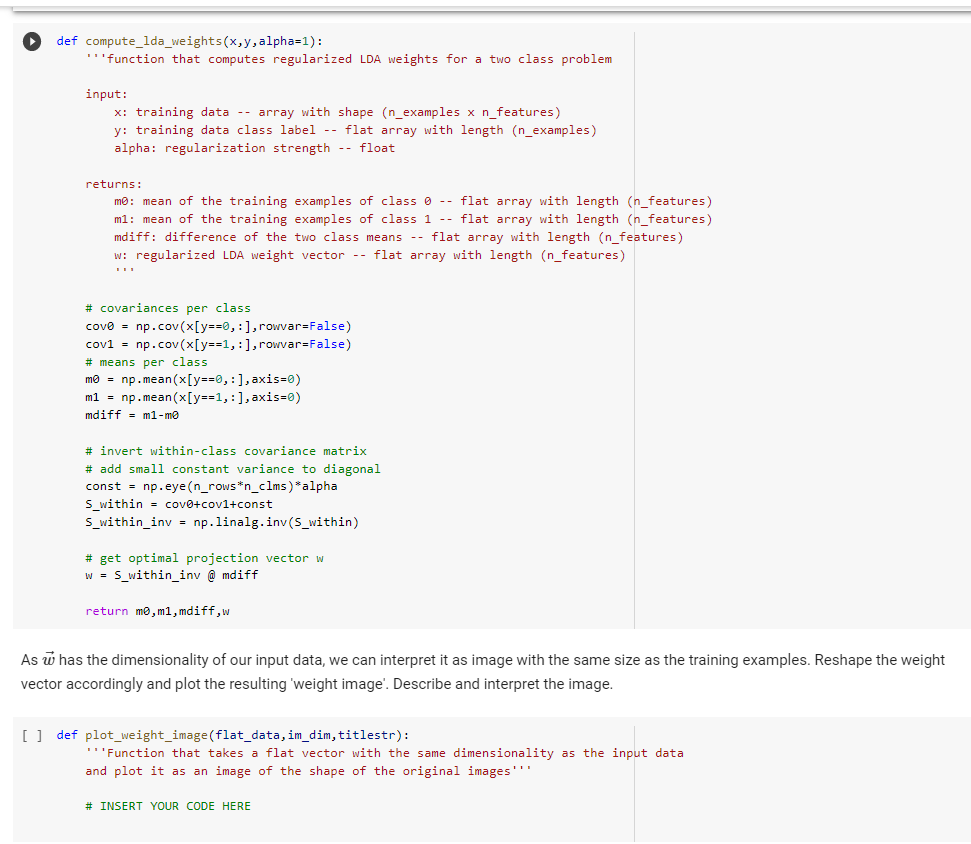
- Task 1: LDA (15 points) For the rest of the notebook, we will restrict ourselves to the classes 3 and 8, and also to a subset of examples (500 per class). First, use Linear Discriminant Analysis to separate the classes. Here you will need to find a weight vector so that the classes are optimally separated in the projections Pi = i of data points Ti. [] classes = [3,8] (x_train, y_train), (x_test, y_test), num_classes = prepare_data(use_classes = classes, return_shape_y='vector', return_shape_x='flat',n_trainex_per_class=500) 1000 train samples 1984 test samples x_train shape: (1000, 784) y_train shape: (1000,) Use the analytic solution to compute the optimal weights from the training set data. Note: In cases like ours where n features isn't much smaller than N samples, the within-class covariance matrix is not invertible. To fix this, we can add a small constant to the diagonal of it, which is equivalent to ridge regularization. Play a bit with the value of the pentaly to see its effect and find a value that gives good results. You can rely on the fact that there is the same number of samples in each class (it simplifies some of the formulas). [] def compute_lda_weights(x,y,alpha=1): "'function that computes regularized LDA weights for a two class problem input: x: training data -- array with shape (n_examples x n_features) y: training data class label -- flat array with length (n_examples) alpha: regularization strength -- float returns: mo: mean of the training examples of class 0 -- flat array with length (n_features) ml: mean of the training examples of class 1 -- flat array with length (n_features) mdiff: difference of the two class means -- flat array with length (n_features) w: regularized LDA weight vector -- flat array with length (n_features) # covariances per class Covo = np.cov(x[y==0, :], rowvar=False) covi = np.cov(x[y==1,:], rowvar=False) # means per class mo = np.mean(x[y==0,- ), axis=0) m1 = nn, mean/xy==1:1.axis=2) def compute_lda_weights(x,y,alpha=1): "'function that computes regularized LDA weights for a two class problem input: x: training data -- array with shape (n_examples x n_features) y: training data class label -- flat array with length (n_examples) alpha: regularization strength -- float returns: mo: mean of the training examples of class 0 -- flat array with length (n_features) ml: mean of the training examples of class 1 -- flat array with length (n_features) mdiff: difference of the two class means -- flat array with length (n_features) w: regularized LDA weight vector -- flat array with length (n_features) # covariances per class covo = np.cov(x[y==0, :), rowvar=False) cov1 = np.cov(x[y==1,:], rowvar=False) # means per class mo = np.mean(x[y==0, :], axis=0) m1 = np.mean(x[y==1, :), axis=0) mdiff = m1-mo # invert within-class covariance matrix # add small constant variance to diagonal const = np.eye (n_rows*n_clms)*alpha S_within = cov@+cov1+const S_within_inv = np.linalg. inv(S_within) # get optimal projection vector w W = S_within_inv @ mdiff return mo,m1, mdiff,w As w has the dimensionality of our input data, we can interpret it as image with the same size as the training examples. Reshape the weight vector accordingly and plot the resulting 'weight image'. Describe and interpret the image. [] def plot_weight_image(flat_data, im_dim, titlestr): Function that takes a flat vector with the same dimensionality as the input data and plot it as an image of the shape of the original images" # INSERT YOUR CODE HERE
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts