

Question
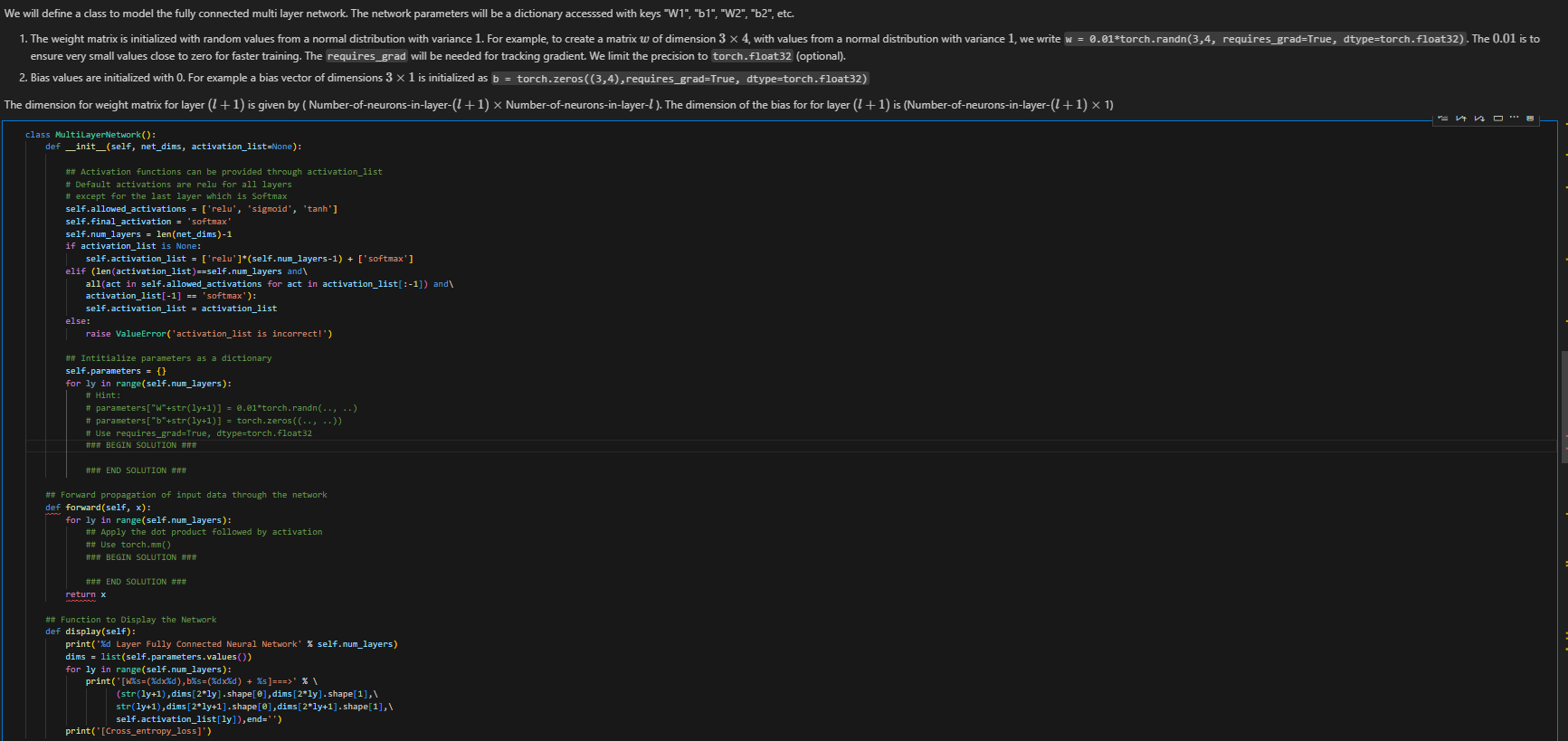
We will define a class to model the fully connected multi layer network. The network parameters will be a dictionary accesssed with keys W1, b1,
We will define a class to model the fully connected multi layer network. The network parameters will be a dictionary accesssed with keys "W1", "b1", "W2", "b2", etc.\ ensure very small values close to zero for faster training. The requires_grad will be needed for tracking gradient. We limit the precision to torch.float 32 (optional).\ Bias values are initialized with 0 . For example a bias vector of dimensions
3\\\\times 1is initialized as , requires_grad=True, dtype=torch.float32)\ class MultiLayerNetwork():\ def_init_(self, net_dims, activation_list=None):\ # Activation functions can be provided through activation_list\ # Default activations are relu for all layers\ # except for the last layer which is Softmax\ self.allowed_activations = ['relu', 'sigmoid', 'tanh']\ self.final_activation = 'softmax'\ self.num_layers
=len(net_dims)-1\ if activation_list is None:\ self.activation_list self.num_layers-1) 'softmax'
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Transact SQL Cookbook Help For Database Programmers
Authors: Ales Spetic, Jonathan Gennick
1st Edition
1565927567, 978-1565927568