

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Write a similar code using JAVA or Python. Write a similar code using JAVA or Python. The state diagram in Figure 4.1 describes the patterns
Write a similar code using JAVA or Python.
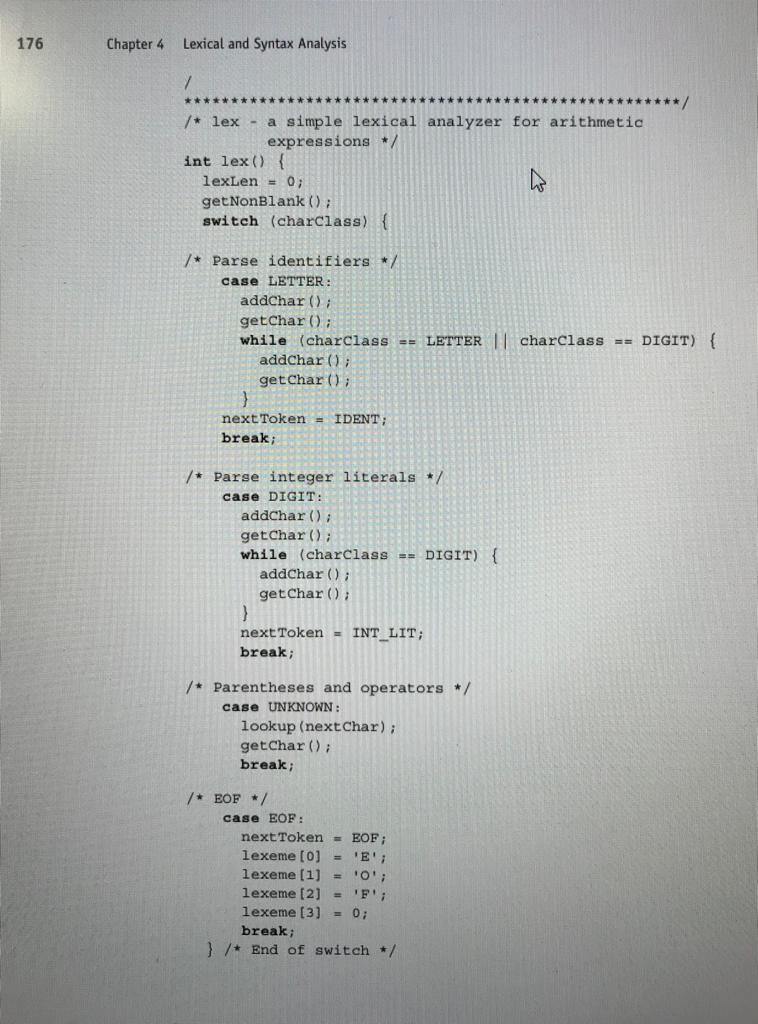

Write a similar code using JAVA or Python.
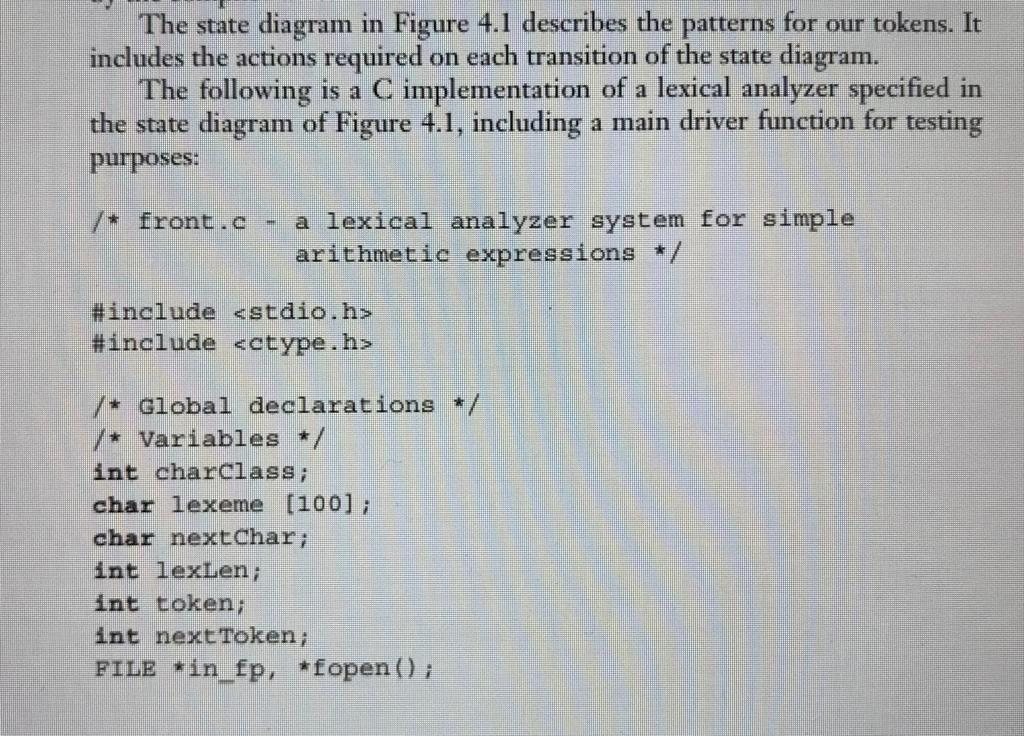
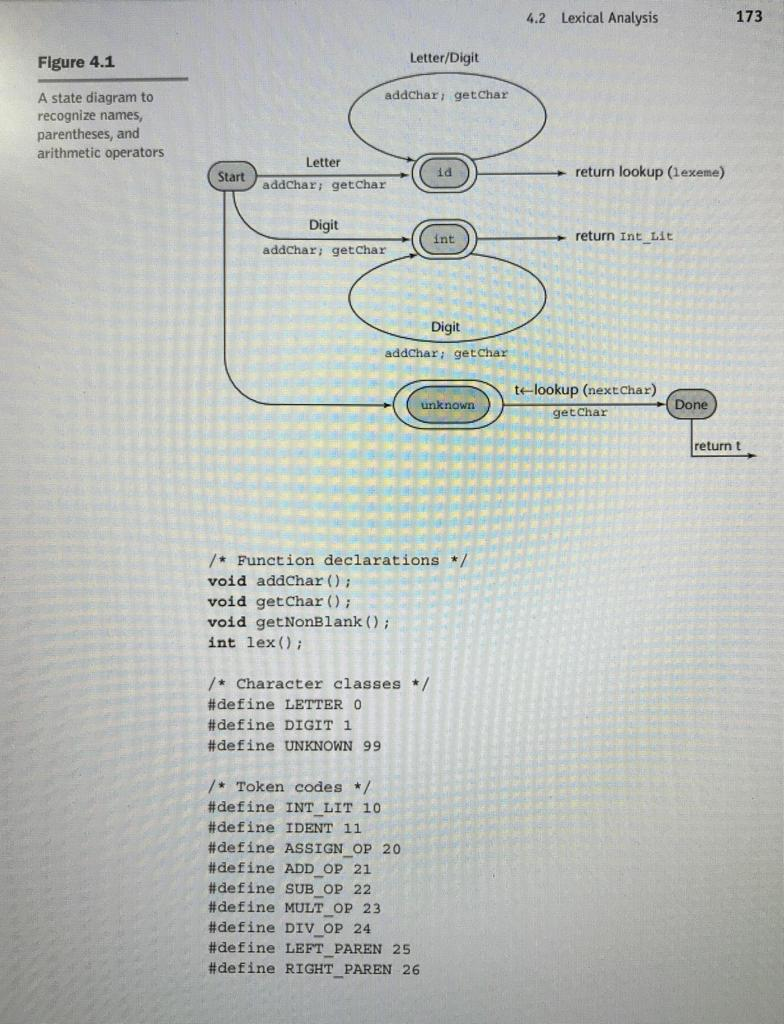
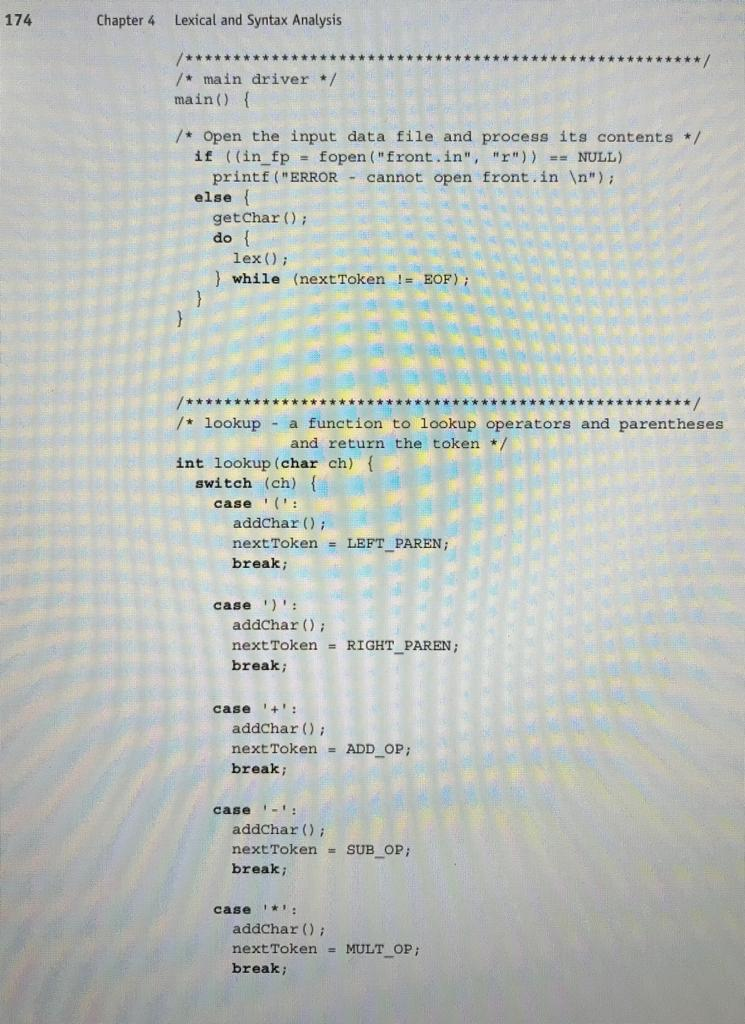
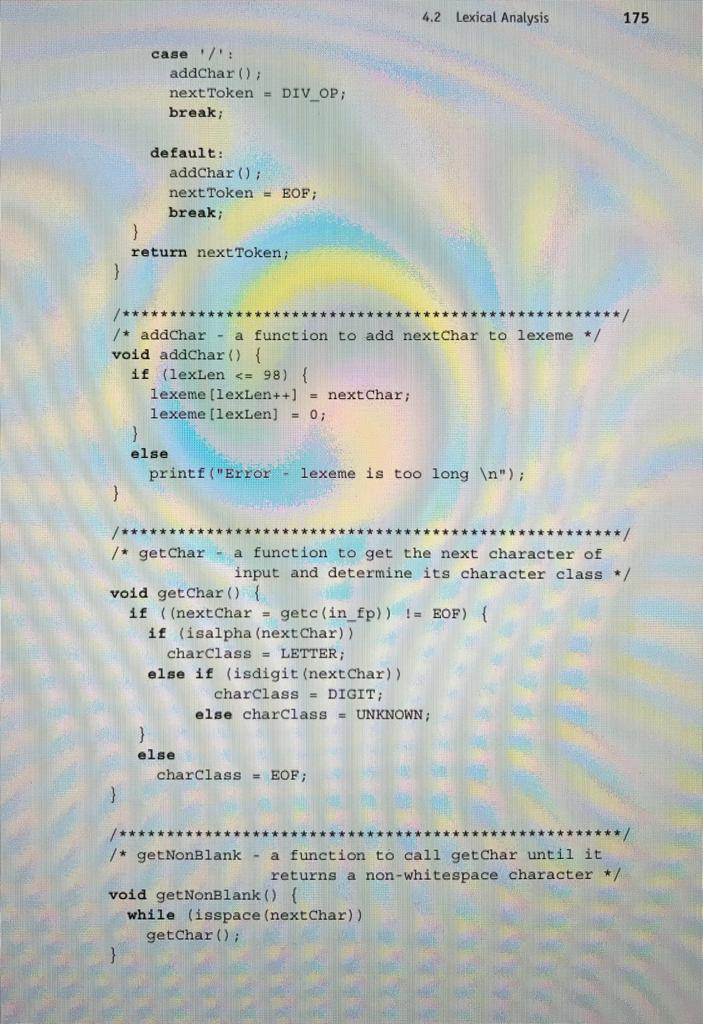
The state diagram in Figure 4.1 describes the patterns for our tokens. It includes the actions required on each transition of the state diagram. The following is a C implementation of a lexical analyzer specified in the state diagram of Figure 4.1, including a main driver function for testing purposes /* front .c a lexical analyzer system for simple arithmetic expressions */ # include #includeStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Mastering Postgre Sql 15 Advanced Techniques To Build And Manage Scalable Reliable And Fault Tolerant Database Applications
Authors: Hans-Jurgen Schonig
5th Edition
1803248343, 978-1803248349