

Question: Consider a naive Bayes classifier with two features, shown below. We have prior information that the probability model can be parameterized by and p,
Consider a naive Bayes classifier with two features, shown below. We have prior information that the probability model can be parameterized by λ and p, as shown below:
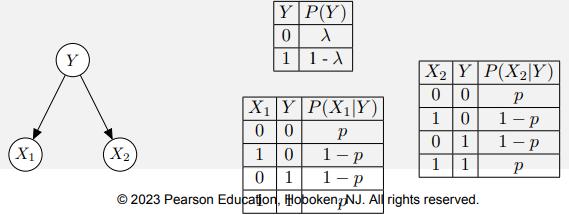
We have a training set that contains all of the following:
• n000 examples with X1 = 0, X2 = 0, Y = 0
• n010 examples with X1 = 0, X2 = 1, Y = 0
• n100 examples with X1 = 1, X2 = 0, Y = 0
• n110 examples with X1 = 1, X2 = 1, Y = 0
• n001 examples with X1 = 0, X2 = 0, Y = 1
• n011 examples with X1 = 0, X2 = 1, Y = 1
• n101 examples with X1 = 1, X2 = 0, Y = 1
• n111 examples with X1 = 1, X2 = 1, Y = 1
a. Solve for the maximum likelihood estimate (MLE) of the parameter p with respect to n000, n100, n010, n110, n001, n101, n011, and n111.
b. For each of the following values of λ, p, X1, and X2, classify the value of Y
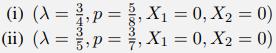
c. Now let’s consider a new model M2, which has the same Bayes’ Net structure as M1, but where we have a p1 value for P(X1 = 0 | Y = 0) = P(X1 = 1 | Y = 1) = p1 and a separate p2 value for P(X2 = 0 | Y = 0) = P(X2 = 1 | Y = 1) = p2, and we don’t constrain p1 = p2. Let LM1 be the likelihood of the training data under model M1 with the maximum likelihood parameters for M1. Let LM2 be the likelihood of the training data under model M2 with the maximum likelihood parameters for M2. Are we guaranteed to have LM1 ≤ LM2?
(X Y Y 0 P(Y) X 11-A X P(XY) 1-P 1-P 2023 Pearson Education, Hoboken, NJ. All rights reserved. XY P(XY) 0 0 P 1 0 1-p 0 1 1 1 X Y 0 0 1 0 0 1 1 - P P
Step by Step Solution
3.43 Rating (156 Votes )
There are 3 Steps involved in it
a We first write down the likelihood of the training data T Y X 1 X 2 We then take the logarithm o... View full answer

Get step-by-step solutions from verified subject matter experts