

Consider a text corpus consisting of N tokens of d distinct words and the number of times
Question:
Consider a text corpus consisting of N tokens of d distinct words and the number of times each distinct word w appears is given by xw. We want to apply a version of Laplace smoothing that estimates a word’s probability as:
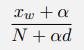
for some constant α (Laplace recommended α = 1, but other values are possible.) In the following problems, assume N is 100,000, d is 10,000 and α is 2.
a. Give both the unsmoothed maximum likelihood probability estimate and the Laplace smoothed estimate of a word that appears 1,000 times in the corpus.
b. Do the same for a word that does not appear at all.
c. You are running a Naive Bayes text classifier with Laplace Smoothing, and you suspect that you are overfitting the data. How would you increase or decrease the parameter α?
d. Could increasing α increase or decrease training set error? Increase or decrease validation set error?
Step by Step Answer:
a Unsmoothed 1000100000 001 Smoothed b Unsmoothed 0 Smoo...View the full answer



Artificial Intelligence A Modern Approach
ISBN: 9780134610993
4th Edition
Authors: Stuart Russell, Peter Norvig
