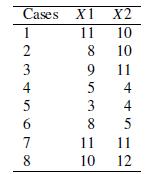
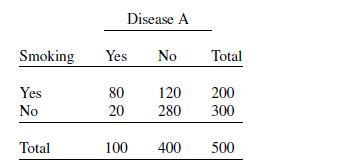
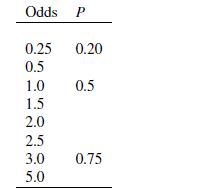
Practical Multivariate Analysis 5th Edition Abdelmonem Afifi, Susanne May, Virginia A. Clark - Solutions
Discover comprehensive resources for "Practical Multivariate Analysis 5th Edition" by Abdelmonem Afifi, Susanne May, and Virginia A. Clark. Access the online answers key and detailed solutions PDF to enhance your understanding of the textbook. Benefit from the solution manual and solved problems for a clear grasp of complex concepts. Explore the test bank for practice with chapter solutions and step-by-step answers. Our instructor manual offers invaluable insights, while the questions and answers section ensures thorough preparation. Enjoy free download options to facilitate your learning journey with this essential academic resource.