

Question: For this exercise, you will replicate (on a smaller scale) the box-office prediction modeling explained in Application Case 5.6. Download the training data set from
For this exercise, you will replicate (on a smaller scale) the box-office prediction modeling explained in Application Case 5.6. Download the training data set from Online File W5.2, MovieTrain.xlsx, which is in Microsoft Excel format. Use the data description given in Application Case 5.6 to understand the domain and the problem you are trying to solve. Pick and choose your independent variables. Develop at least three classification models (e.g., decision tree, logistic regression, neural networks). Compare the accuracy results using 10-fold cross-validation and percentage split techniques, use confusion matrices, and comment on the outcome. Test the models you have developed on the test set (see Online File W5.3, MovieTest.xlsx). Analyze the results with different models and come up with the best classification model, supporting it with your results.
Data from Case 5.6
Predicting box-office receipts (i.e., financial success) of a particular motion picture is an interesting and challenging problem. According to some domain experts, the movie industry is the "land of hunches and wild guesses" due to the difficulty associated with forecasting product demand, making the movie business in Hollywood a risky endeavor.
In support of such observations, Jack Valenti (the longtime president and CEO of the Motion Picture Association of America) once mentioned that "…no one can tell you how a movie is going to do in the marketplace…not until the film opens in darkened theatre and sparks fly up between the screen and the audience." Entertainment industry trade journals and magazines have been full of examples, statements, and experiences that support such a claim.
Like many other researchers who have attempted to shed light on this challenging real-world problem, Ramesh Sharda and Dursun Delen have been exploring the use of data mining to predict the financial performance of a motion picture at the box office before it even enters production (while the movie is nothing more than a conceptual idea). In their highly publicized prediction models, they convert the forecasting (or regression) problem into a classification problem;
that is, rather than forecasting the point estimate of box-office receipts, they classify a movie based on its box-office receipts in one of nine categories, ranging from "flop" to "blockbuster," making the problem a multinomial classification problem. Table 5.4 illustrates the definition of the nine classes in terms of the range of box-office receipts.
Data
Data was collected from variety of movie-related databases (e.g., ShowBiz, IMDb, IMSDb, AllMovie, etc.) and consolidated into a single data set. The data set for the most recently developed models contained 2,632 movies released between 1998 and 2006. A summary of the independent variables along with their specifications is provided in Table 5.5. For more descriptive details and justification for inclusion of these independent variables, the reader is referred to Sharda and Delen (2007).
Methodology
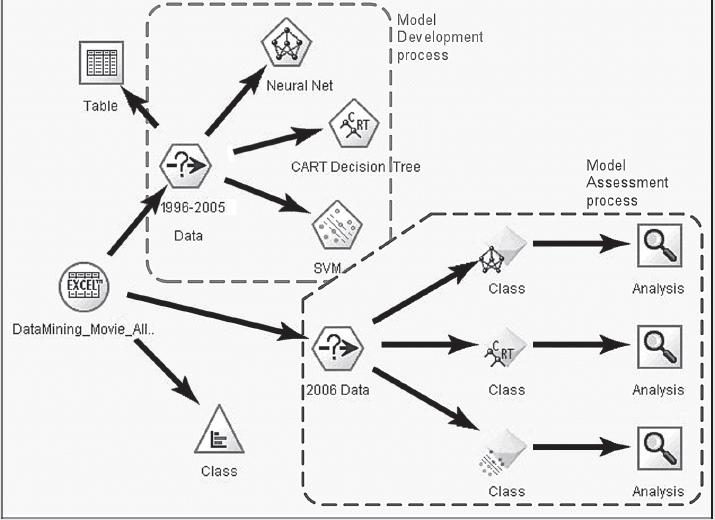
Using a variety of data mining methods, including neural networks, decision trees, support vector machines, and three types of ensembles, Sharda and Delen developed the prediction models. The data from 1998 to 2005 were used as training data to build the prediction models, and the data from 2006 was used as the test data to assess and compare the models' prediction accuracy. Figure 5.15 shows a screenshot of IBM SPSS Modeler (formerly Clementine data mining tool) depicting the process map employed for the prediction problem. The upper-left side of the process map shows the model development process, and the lower-right corner of the process map shows the model assessment (i.e., testing or scoring) process (more details on IBM SPSS Modeler tool and its usage can be found on the book's Web site).
Results
Table 5.6 provides the prediction results of all three data mining methods as well as the results of the three different ensembles. The first performance measure is the percent correct classification rate, which is called bingo. Also reported in the table is the 1-Away correct classification rate (i.e., within one category). The results indicate that SVM performed the best among the individual prediction models, followed by ANN; the worst of the three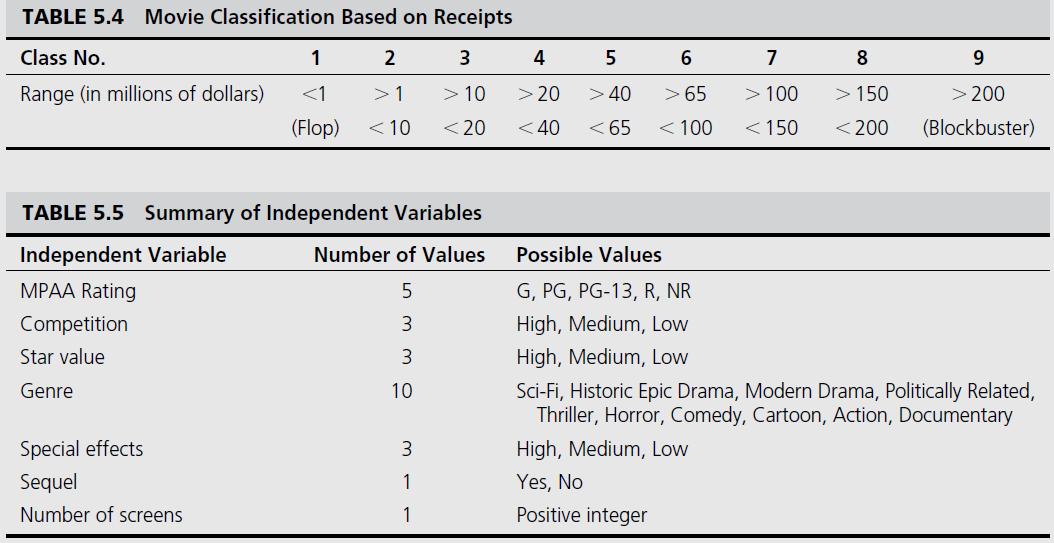
was the CART decision tree algorithm. In general, the ensemble models performed better than the individual predictions models, of which the fusion algorithm performed the best. What is probably more important to decision makers, and standing out in the results table, is the significantly low standard deviation obtained from the ensembles compared to the individual models. Conclusion The researchers claim that these prediction results are better than any reported in the published literature for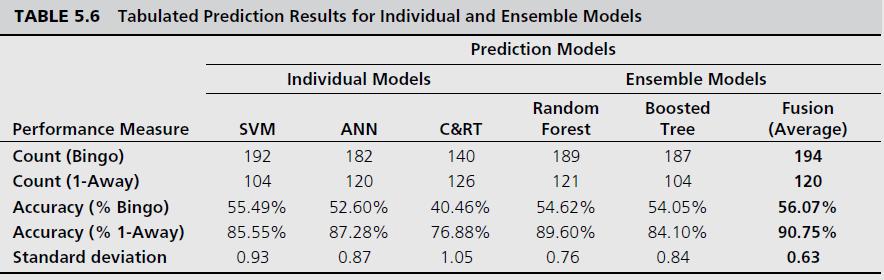
this problem domain. Beyond the attractive accuracy of their prediction results of the box-office receipts, these models could also be used to further analyze (and potentially optimize) the decision variables in order to maximize the financial return. Specifically, the parameters used for modeling could be altered using the already trained prediction models in order to better understand the impact of different parameters on the end results. During this process, which is commonly referred to as sensitivity analysis, the decision maker of a given entertainment firm could find out, with a fairly high accuracy level, how much value a specific actor (or a specific release date, or the addition of more technical effects, etc.) brings to the financial success of a film, making the underlying system an invaluable decision aid.
Questions for Discussion
1. Why is it important for Hollywood professionals to predict the financial success of movies?
2. How can data mining be used to predict the financial success of movies before the start of their production process?
3. How do you think Hollywood performed, and perhaps is still performing, this task without the help of data mining tools and techniques?
Step by Step Solution
3.53 Rating (160 Votes )
There are 3 Steps involved in it
The images provided contain tables and a flowchart from a case study showing the process and results of using data mining techniques to predict the fi... View full answer

Get step-by-step solutions from verified subject matter experts