

For this exercise, you will replicate (on a smaller scale) the box-office prediction modeling explained in Application
Question:
For this exercise, you will replicate (on a smaller scale) the box-office prediction modeling explained in Application Case 4.6. Download the training data set from Online File W4.2, MovieTrain.xlsx, which is in Microsoft Excel format. Use the data description given in Application Case 4.6 to understand the domain and the problem you are trying to solve. Pick and choose your independent variables. Develop at least three classification models (e.g., decision tree, logistic regression, neural networks). Compare the accuracy results using 10-fold cross-validation and percentage split techniques, use confusion matrices, and comment on the outcome. Test the models you have developed on the test set (see Online File W4.3, MovieTest.xlsx). Analyze the results with different models, and find the best classification model, supporting it with your results.
Data from Case 4.6
Predicting box-office receipts (i.e., financial success)of a particular motion picture is an interesting andchallenging problem. According to some domaexperts, the movie industry is the “land of hunchesand wild guesses” due to the difficulty associatedwith forecasting product demand, making the movie business in Hollywood a risky endeavor. In support of such observations, Jack Valenti (the longtime president and CEO of the Motion Picture Association of America) once mentioned that "no one can tell you how a movie is going to do in the marketplace. . . not until the film opens in darkened theatre and sparks fly up between the screen and the audience." Entertainment industry trade journals and magazines have been full of examples, statements, and experiences that support such a claim. Like many other researchers who have attempted to shed light on this challenging real-world problem, Ramesh Sharda and Dursun Delen have been exploring the use of data mining to predict the financial performance of a motion picture at the box office before it even enters production (while the movie is nothing more than a conceptual idea). In their highly publicized prediction models, they convert the forecasting (or regression) problem into a classification problem; that is, rather than forecasting the point estimate of box-office receipts, they classify a movie based on its box-office receipts in one of nine categories, ranging from "flop" to "blockbuster," making the problem a multinomial classification problem. Table 4.3 illustrates the definition of the nine classes in terms of the range of box-office receipts.

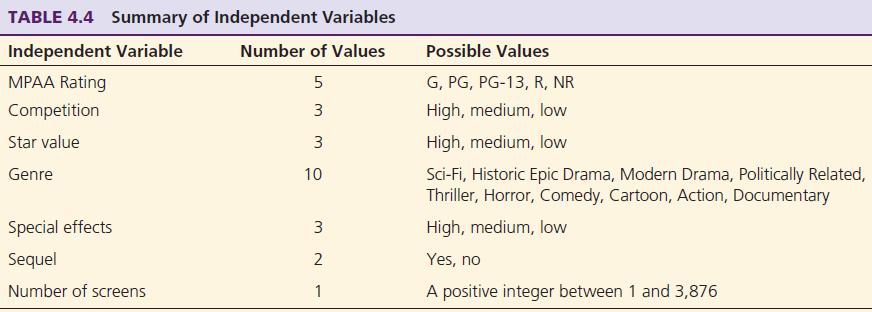
Data Data were collected from a variety of movie-related databases (e.g., ShowBiz, IMDb, IMSDb, AllMovie, BoxofficeMojo) and consolidated into a single data set. The data set for the most recently developed models contained 2,632 movies released between 1998 and 2006. A summary of the independent variables along with their specifications is provided in Table 4.4. For more descriptive details and justification for inclusion of these independent variables, the reader is referred to Sharda and Delen (2006).
Questions for Case
1. Why is it important for many Hollywood professionals to predict the financial success of movies?
2. How can data mining be used for predicting financial success of movies before the start of their production process?
3. How do you think Hollywood performed, and perhaps still is performing, this task without the help of data mining tools and techniques?
Step by Step Answer:
Step 1 Data Understanding and Preparation Download and import the training data MovieTrainxlsx into your chosen data analysis tool Explore the dataset to understand its structure variables and contents Refer to the data description provided in Application Case 46 for insights into the variables Select a target variable for classification In this case its likely the boxoffice performance classes eg flop blockbuster Choose relevant independent variables features from the dataset that you believe could influence boxoffice performance Consider the independent variables listed in Table 44 from the case for guidance Step 2 Data Preprocessing Handle missing data outliers and any data quality issues as needed Encode categorical variables if necessary eg convert textbased genres into numerical values Split the dataset into training and validation sets for model development and evaluation Step 3 Model Development Select at least three classification algorithms to build predictive models Common choices include Decision Trees Logistic Regression Random Forest Support Vector Machines and Neural Networks Train each selected model on the training dataset using appropriate libraries or tools Perform hyperparameter tuning crossvalidation and model evaluation on the training data to optimize model performance Step 4 Model Evaluation Evaluate the models performance using 10fold crossvalidation and percentage split techniques Utilize appropriate evaluation metrics for classification tasks such as accuracy precision recall F1score and confusion matrices Compare the performance of the models and identify the bestperforming one Step 5 Test Set Evaluation Test the bestperforming model on the test dataset MovieTestxlsx Calculate and report the models performance metrics on the test data to assess its generalization capability Step 6 Interpretation and Conclusion Interpret the results and discuss the implications of the chosen model for predicting boxoffice performance Reflect on the importance of predicting financial success in the movie industry and how data mining techniques can enhance this task Answers to Case Questions Why is it important for many Hollywood professionals to predict the financial success of movies Predicting the financial success of movies is crucial for Hollywood professionals for several reasons Risk Mitigation The movie industry involves significant financial investments Accurate predictions help studios and investors assess the potential return on investment and minimize financial risks Resource Allocation Knowing which movies are likely to be successful allows studios to allocate resources effectively from marketing budgets to distribution strategies Audience Engagement Understanding audience preferences and predicting boxoffice performance helps in tailoring marketing campaigns and content ...View the full answer



Analytics Data Science And Artificial Intelligence Systems For Decision Support
ISBN: 9781292341552
11th Global Edition
Authors: Ramesh Sharda, Dursun Delen, Efraim Turban
