

Evaluation of an imputation method for missing data. When analyzing large data sets with many variables, researchers
Question:
Evaluation of an imputation method for missing data.
When analyzing large data sets with many variables, researchers often encounter the problem of missing data
(e.g., non-response). Typically, an imputation method will be used to substitute in reasonable values (e.g., the mean of the variable) for the missing data. An imputation method that uses “nearest neighbors” as substitutes for the missing data was evaluated in Data & Knowledge Engineering
(Mar. 2013). Two quantitative assessment measures of the imputation algorithm are normalized root mean square error (NRMSE) and classification bias. The researchers applied the imputation method to a sample of 3600 data sets with missing values and determined the NRMSE and classification bias for each data set. The correlation coefficient between the two variables was reported as r = .2838.
a. Conduct a test to determine if the true population correlation coefficient relating NRMSE and bias is positive.
Interpret this result practically.
b. A scatterplot for the data (extracted from the journal article) is shown below. Based on the graph, would you recommend using NRMSE as a linear predictor of bias?
Explain why your answer does not contradict the result in part a.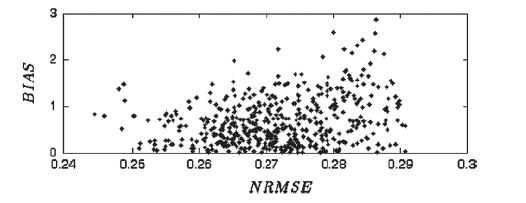
Step by Step Answer:

This question has not been answered yet.
You can Ask your question!


Statistics Plus New Mylab Statistics With Pearson Etext Access Card Package
ISBN: 978-0134090436
13th Edition
Authors: James Mcclave ,Terry Sincich
