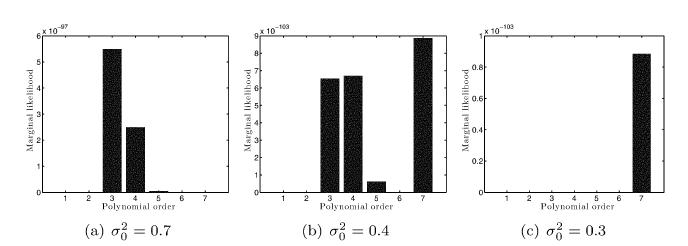
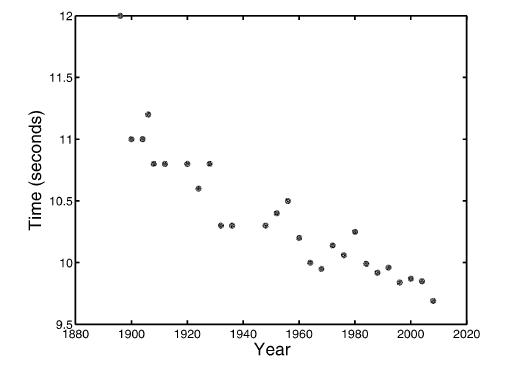
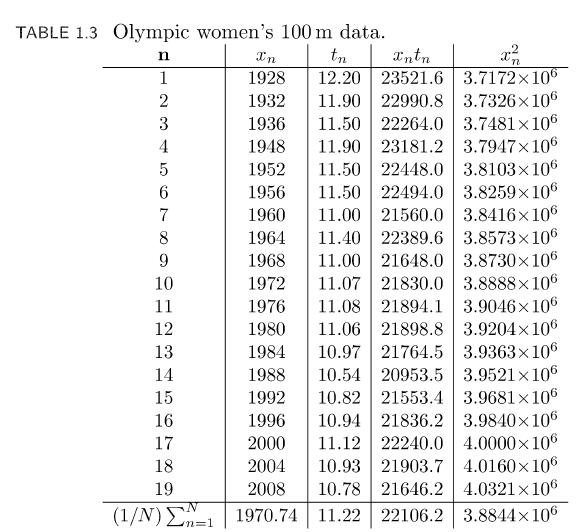
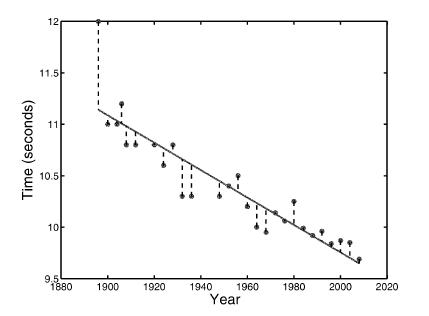
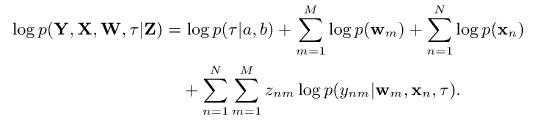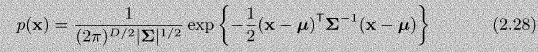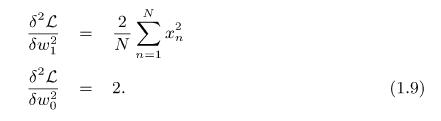A First Course In Machine Learning 2nd Edition Simon Rogers , Mark Girolam - Solutions
Discover comprehensive solutions and step-by-step answers to the questions from "A First Course In Machine Learning 2nd Edition" by Simon Rogers and Mark Girolam. Our online platform offers a complete solutions manual and answers key in a convenient PDF format, perfect for students and instructors alike. Explore chapter solutions and a detailed test bank to enhance your learning experience. Download the instructor manual for free and access solved problems to deepen your understanding of this essential textbook. Unlock the potential of machine learning with our expertly crafted questions and answers resource.