Activity 4 :General Instructions: Please place your name above, then complete the following questions. NOTE: Read the entire document below to get _a feel for
Activity 4
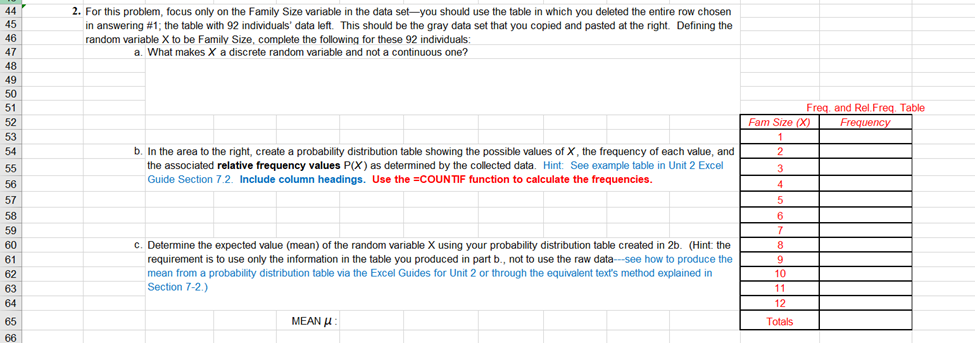
:General Instructions: Please place your name above, then complete the following questions. NOTE: Read the entire document below to get _a feel for the activity before continuing. Make sure to save this Excel file often using the filename "vourname Activity4Summer2024)". Once 'complete, submit your answers to this activity by attaching your Excel file through the completion link in the Unit 2 Activity 4 assignment description in Blackboard. Use the area to the near right in this Excel worksheet when calculating any statistics/parameters from data (except i - :for question 1. where you will follow directions to go to the second tab.) Methods/work to calculate values must be shown in the |spreadsheet using Excel in order to receive full credit. | Overview: This activity has three major purposes. First, it is designed to show the importance of examining the data prior to performing statistical calculations. Second, the activity should help you recognize the difference between a discrete random variable and a continuous random variable. Finally, the activity is designed to help you see how the descriptive statistical analysis differ for both types of data. The data to be used in answering the guestions below comes from the data collected in the Unit 1a Activity. The sample data set collected from the students of this course originally had a size of n = 254, However, to make the set a bit more manageable for beginning statistics, a collection of 93 individuals' data was selected. You may recognize your own data within this set if you were one of the randomly selected individuals. This data is supplied in the attached worksheet titled "Original Data Set for Analysis\"...see the tab at the bottom of this document window. The first step with analyzing data is to make sure that all data values were submitted correctly and seem to be reasonable/proper measurementsthis is called cleaning the data. In initial analysis of the student data, there were several mismeasurements or incorrectly given measurements; much of this was cleaned already. More formally one would also look for possible outliers using a process (like the 1.5I1QR rule) and decide whether or not to include these data in further analysis. In general, a valid and well-established argument should always be given for removal of any data from a data set; removal of any collected data should NOT be done arbitrarily or to skew the data to some desired viewpoint. Analyze the data given in the ATTACHED worksheet (see this worksheet below as "Original Data Set for Analysis\" in the second tab). When you open that tab, you will see instructions to the right of the blue highlighted data set. Follow those directions before returning to this tab (Activity 4) to complete the worksheet. 2. For this problem, focus only on the Family Size variable in the data set-you should use the table in which you deleted the entire row chosen 44 in answering #1; the table with 92 individuals' data left. This should be the gray data set that you copied and pasted at the right. Defining the 45 random variable X to be Family Size, complete the following for these 92 individuals: 46 a. What makes X a discrete random variable and not a continuous one? 47 48 Freq. and Rel.Freq. Table 49 Fam Size (x) Frequency 50 51 52 53 b. In the area to the right, create a probability distribution table showing the possible values of X, the frequency of each value, and 54 the associated relative frequency values P(X) as determined by the collected data. Hint: See example table in Unit 2 Excel Guide Section 7.2. Include column headings. Use the =COUNTIF function to calculate the frequencies. 55 56 57 58 59 c. Determine the expected value (mean) of the random variable X using your probability distribution table created in 2b. (Hint: the requirement is to use only the information in the table you produced in part b., not to use the raw data--see how to produce the 12 8 mean from a probability distribution table via the Excel Guides for Unit 2 or through the equivalent text's method explained in 11 12 62 Section 7-2.) 63 Totals 64 MEAN U : 65 66w w 8288 BIBRRBB2 B[ d. Determine the standard deviation of the random variable X, again using only the values within your probability distribution table. (You can check your answers by finding the population s.d. of the data on family size, BUT this problem needs to be answered through use of only the probability distribution table built in part b--see Section 7-2.) 5t Deviation @ e Typically, any data outside of the 2 Sigma Rule (pg. 154) is considered "unusual * Decide if any of the included values of the random variable X is unusual. Give a concluding statement below in regard to your decision. Show work for 2 Sigma Rule to the right of the problem. f. Create a probability statement which is supported by the values in the probability distnibution table. (For example, "The probability that a randomly selected member of this group comes from a family of size 7 or more is 77%"). Mean: Standard Deviation: wrar 96 3. Now consider your cleaned data in reference to the Height variable of the students. Motice that this data is categorized as quantitative, 97 continuous, and ratio level in type. (This portion of the activity is Based on Workshop Statistics, Rossman, p. 66) 98 1 99 a. In column N at the right, copy the Height variable values (again take the cleaned data set of 92 values on this worksheet) and 100 then sort them in order from least to greatest. From this column of Height values, create an appropriate frequency table with 101 exactly 5 classes--remember, we did such frequency charts back in Unit 1. (Use the answer key from Activity 2 as a guide for 102" how to make the class widths.) For the next part, b, you may choose to produce the histogram graph at the same time. Finally 03| extend your frequency table to include a relative frequency column. (You may want to review how to make a complete : o4 histogram using the answer key to Activity 2, too.) 105 106 b. Produce a 5 class histogram for your frequency table (if you did not do so as you constructed your table in part a). Does the 107 distribution of the Height values appear to be roughly normal? Explain your answer briefly. 108 109 110, 11 . Compute the mean and standard deviation of the Height values...not from the frequency table as done in the discrete case 112 above but as done in the first unit, but this time assuming this is sample data of all stats students. 113 Sample mean, x bar: 114 Sample std. deviation, s 115 116, 117 d. Determine the proportion of the students in this sample whose Height is at least 164 cm. 118, 119, @ Al 96 3. Mow consider your cleaned data in reference to the Height variable of the students. Motice that this data is categorized as quantitative, al continuous, and ratio level in type. (This portion of the activity is Based on Workshop Statistics, Rossman, p. 66) 98 | 99 a. In column N at the right, copy the Height variable values (again take the cleaned data set of 92 values on this worksheet) and then 100 sort them in order from least to greatest. From this column of Height values, create an appropriate frequency table with exactly 101 classes--remember, we did such frequency charts back in Unit 1. (Use the answer key from Activity 2 as a guide for how to make 1 02' the class widths.) For the next part, b, you may choose to produce the histogram graph at the same time. Finally extend your = frequency table to include a relative frequency column. (You may want to review how to make a complete histogram using the :$ answer key to Activity 2, t00.) 105, 106 p. Produce a class histogram for your frequency table (if you did not do so as you constructed your table in part a). Does the 107 distribution of the Height values appear to be roughly normal? Explain your answer briefly, 108 109 110, 111 c. Compute the mean and standard deviation of the Height values. .. not from the frequency table as done in the discrete case above 112 but as done in the first unit, but this time assuming this is sample data of all stats students. 113| Sample mean, xbar: 114 Sample std. deviation, s: 115 116/ 117 d. Determine the proportion of the students in this sample whose Height is at least 164 cm. 118 119 120 121 122 123 e. Suppose that the Heights in the population of all university students taking Elements of Statistics do in fact follow a perfect normal 124 distribution (though our group did not) with the population mean p = 170.0 cm and population standard dewviation o = 10.35cm . 125 Under this assumption, determine the proportion of all students who have a Height measure of at least 164 cm. (HINT: this 126_ calculation is related to the concepts covered in text section 8-4!) = a_ae ea s | A EL N ewCiC Mok Lo R S ET
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance