all photos are for the same problem!

same photos, but more clear !

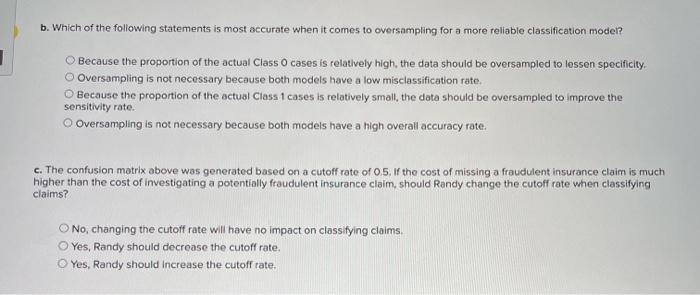
Randy Johnson is an insurance adjustor for a national auto insurance company. Using historical Insurance claim data, Randy has built an insurance fraud detection model with the help of a data analyst. Applying the model on the validation data set generated the following confusion matrix. A fraudulent insurance claim is a Class 1 case while a non-traudulent claim is a Class 0 case. Actual case Fredicted Class 1 332 class o 2. Compute the misclosunication rate, accuracy rate, sensitivity, precision and specificity of the classification model (Round Intermediate calculations to at least 4 decimal places and your final answers to 4 decimal places.) Miscascation rate Accuracy rate Sensitivity Precision Specificity b. Which of the following statements is most accurate when it comes to oversampling for a more reliable classification model? Because the proportion of the actual Class 0 cases is relatively high, the data should be oversampled to lessen specificity, Oversampling is not necessary because both models have a low misclassification rate. Because the proportion of the actual Class 1 cases is relatively small, the data should be oversampled to improve the sensitivity rate Oversampling is not necessary because both models have a high overall accuracy rate c. The confusion matrix above was generated based on a cutoff rate of 0.5, the cost of missing a fraudulent insurance Claim is much higher than the cost of investigating a potentially fraudulent insurance claim, should Randy change the cutoff rate when classifying claims? O No, changing the cutoff rate will have no impact on classifying claims Yes, Randy should decrease the cutoff rate. Yes, Randy should increase the cutoff rate, Randy Johnson is an insurance adjustor for a national auto insurance company. Using historical insurance claim data, Randy has built an insurance fraud detection model with the help of a data analyst. Applying the model on the validation data set generated the following confusion matrix. A fraudulent insurance claim is a Class 1 case while a non-fraudulent claim is a Class O case. Actual class Predicted Class 1 Class 1 332 Class o 359 Predicted class o 334 3,893 a. Compute the misclassification rate, accuracy rate, sensitivity, precision, and specificity of the classification model (Round intermediate calculations to at least 4 decimal places and your final answers to 4 decimal places.) Misclassification rate Accuracy rate Sensitivity Precision Specificity b. Which of the following statements is most accurate when it comes to oversampling for a more reliable classification model? Because the proportion of the actual Class O cases is relatively high, the data should be oversampled to lessen specificity. Oversampling is not necessary because both models have a low misclassification rate, Because the proportion of the actual Class 1 cases is relatively small, the data should be oversampled to improve the sensitivity rate. Oversampling is not necessary because both models have a high overall accuracy rate. c. The confusion motrix above was generated based on a cutoff rate of 0.5. If the cost of missing a fraudulent insurance claim is much higher than the cost of investigating a potentially fraudulent insurance claim, should Randy change the cutoff rate when classifying claims? No, changing the cutoff rate will have no impact on classifying claims Yes, Randy should decrease the cutoff rate, Yes, Randy should increase the cutoff rate