

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Can somebody take a looks of my code? I got ('happy', 60822),('love', 5057),('together', 2480) already, and want to add # infornt of them. How to
Can somebody take a looks of my code? I got ('happy', 60822),('love', 5057),('together', 2480) already, and want to add # infornt of them.
How to get the answer for question 7
Thank you!!
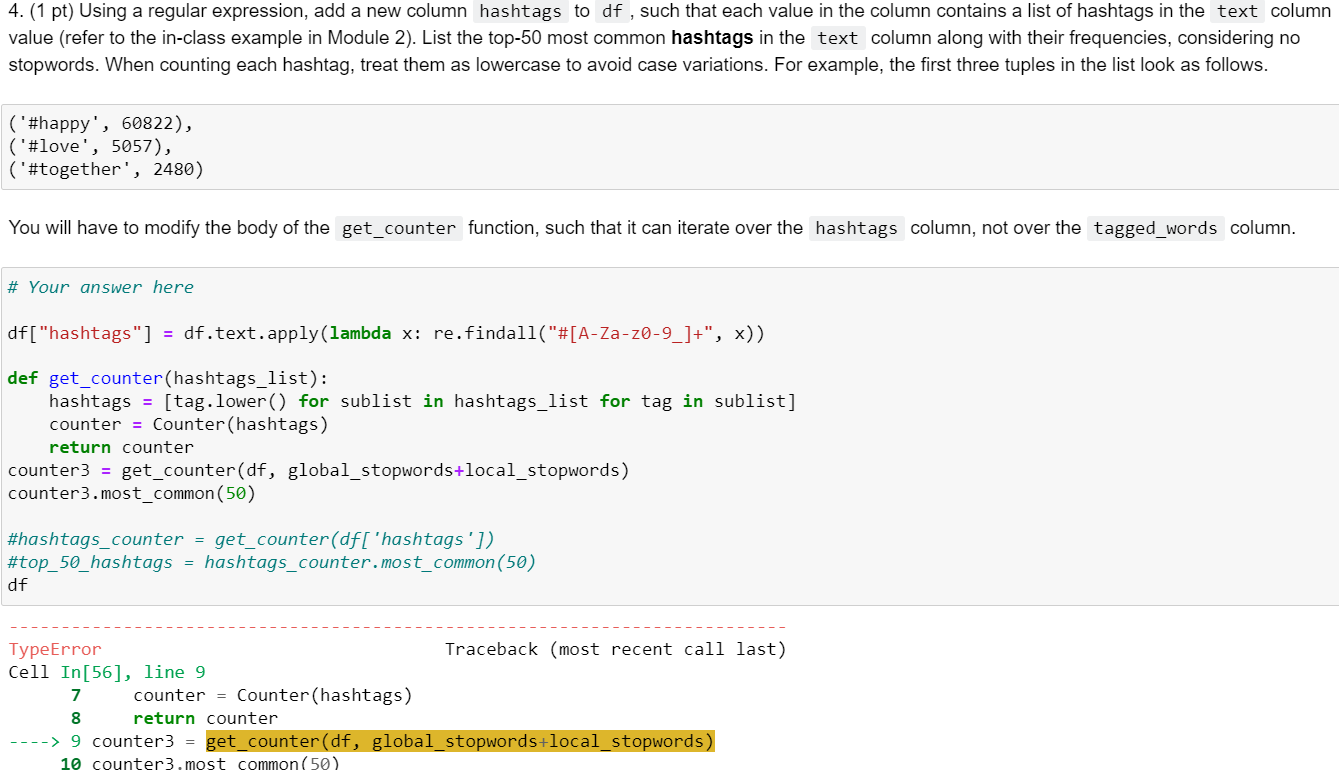
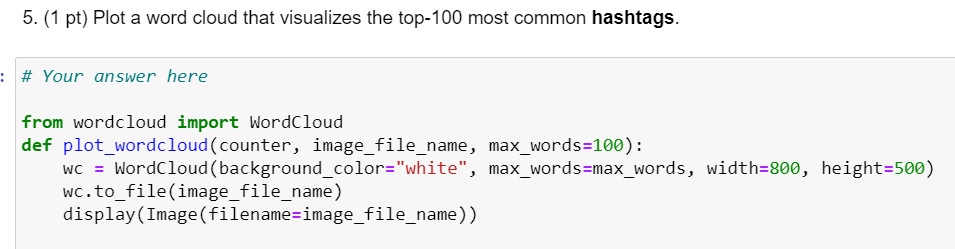
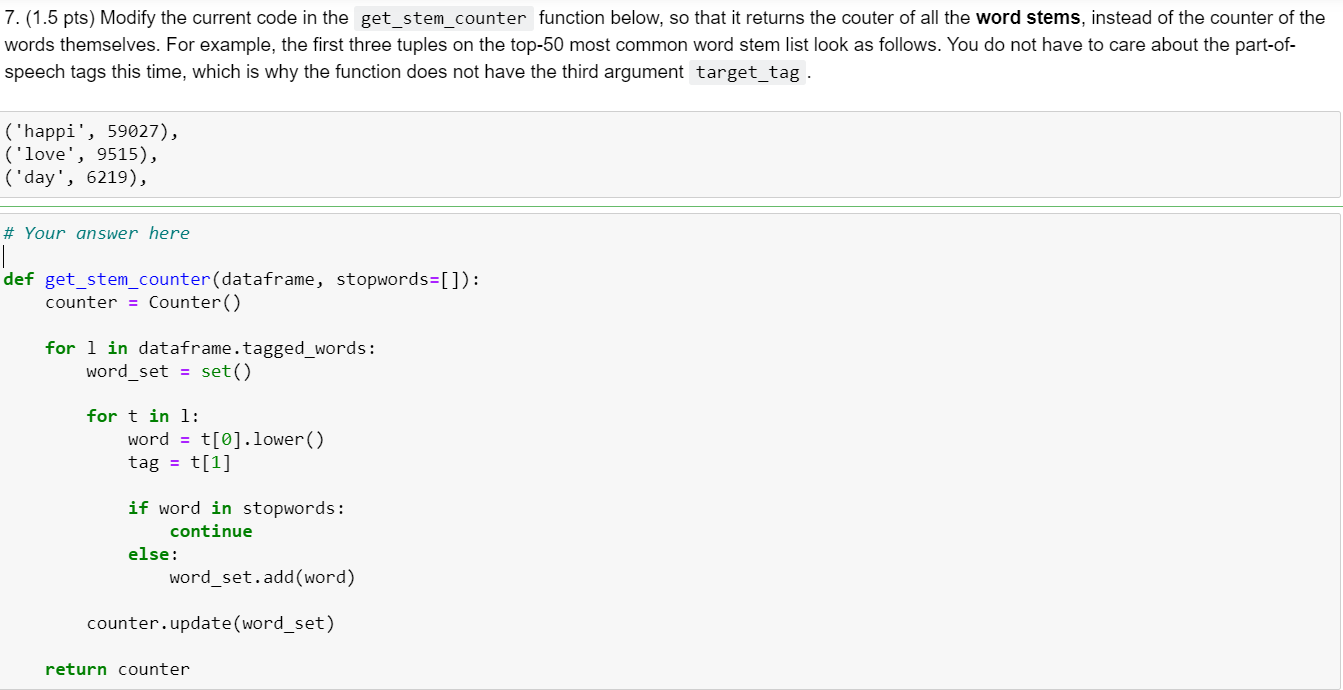
4. (1 pt) Using a regular expression, add a new column hashtags to df, such that each value in the column contains a list of hashtags in the text column value (refer to the in-class example in Module 2). List the top-50 most common hashtags in the text column along with their frequencies, considering no stopwords. When counting each hashtag, treat them as lowercase to avoid case variations. For example, the first three tuples in the list look as follows. ('\#happy' , 60822), ('\#love ' 5057), ('\#together ' 2480) You will have to modify the body of the get_counter function, such that it can iterate over the column, not over the column. \# Your answer here df[ "hashtags"] =df. text. apply (lambda x: re.findall ("#[AZaz09_]+",x)) def get_counter(hashtags_list): hashtags =[taglower() for sublist in hashtags_list for tag in sublist] counter = Counter ( hashtags) return counter counter3 = get_counter (df, global_stopwords+local_stopwords ) counter3.most_common (50) \#hashtags_counter = get_counter (df[ 'hashtags ' ]) \#top_50_hashtags = hashtags_counter.most_common (50) df TypeError Traceback (most recent call last) Cell In [56], line 9 7 counter = Counter (hashtags) 8 return counter 9 counter 3 = get_counter (df, global_stopwords+local_stopwords) 5. (1 pt) Plot a word cloud that visualizes the top-100 most common hashtags. \# Your answer here from wordcloud import WordCloud def plot_wordcloud (counter, image_file_name, max_words=100): wc= WordCloud (background_color="white", max_words=max_words, width=800, height=500) wc.to_file(image_file_name) display (Image(filename=image_file_name)) 7. (1.5 pts) Modify the current code in the get_stem_counter function below, so that it returns the couter of all the word stems, instead of the counter of the words themselves. For example, the first three tuples on the top-50 most common word stem list look as follows. You do not have to care about the part-ofspeech tags this time, which is why the function does not have the third argument (happi,59027),(love,9515),(day,6219), \# Your answer here def get_stem_counter (dataframe, stopwords=[]): counter = Counter () for 1 in dataframe.tagged_words: word_set = set() for t in 1: word =t[0].lower() tag =t[1] if word in stopwords: continue else: word_set.add(word) counter. update(word_set) return counterStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Oracle 10g Database Administrator Implementation And Administration
Authors: Gavin Powell, Carol McCullough Dieter
2nd Edition
1418836656, 9781418836658