can you please help me with the pseudo code what kind of information do you need? Here is the task: write a scanner using an
can you please help me with the pseudo code
what kind of information do you need?
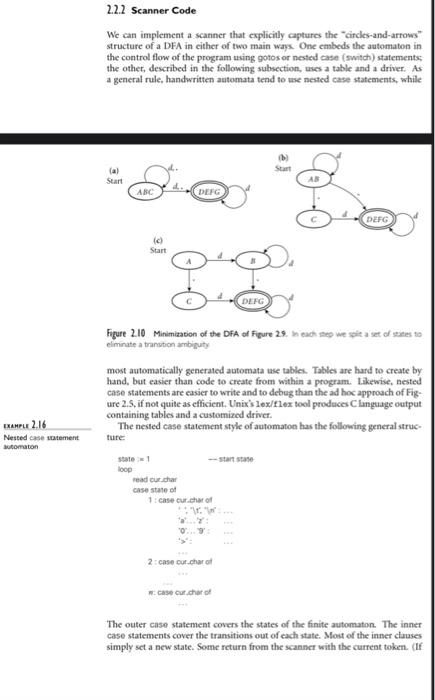
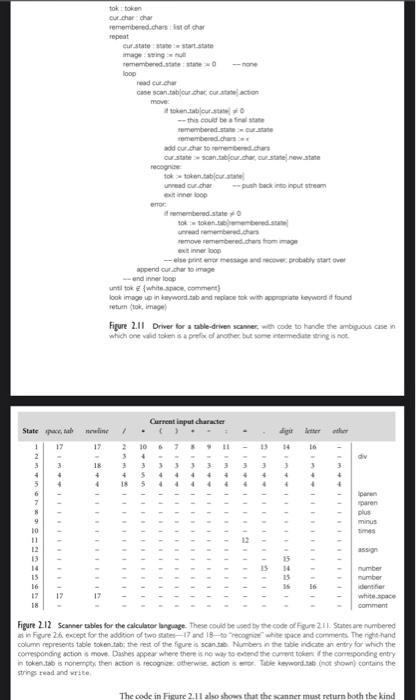
Here is the task: write a scanner using an imperative language: C/C++ (in this option, your program must be compilable using goc or g++.), Java and Python. Your program must have the scan function. Its precondition is that the current pointer of the input file is NOT at the end of file (EOF). It scans from the current pointer of the input file and stops when either a valid token or invalid token can be decided. In the case of a valid token, scan returns the token type (i.e., the left hand side symbol of the corresponding production rule. E.g., for production rule id -> letter letter, the token type of an input "abc" would be id); otherwise, it returns an error flag. Note here when deciding a token you must use the "longest possible token" rule. Your scanner should also deal with the read and write token correctly. The scanner takes the name of a text file from the command line. It outputs to the console errorif there is any non-valid token in the input file; the list of tokens otherwise. Your implementation should be based on the automata in on Page 54 of the textbook. Commandline Invocation: scanner If there is any non-token string in the input file, your program should exit and output to the console only: error. Otherwise, your program outputs only the list of tokens in the form of (tokeni, token2, ...). Example Input File: foo.txt with the following content: read /* foo bar */ * five 5 Example Commandline: scanner foo.txt Example Output: (read, times, id, number). Note that your scanner does NOT output the token of comment. In fact, your function scan should completely ignore all comments in the input. In the example, the next token of times is id, instead of comment. skip any initial white space (spaces, tabs, and newlines) if cur_char e{'(','), '+''-','*'} return the corresponding single-character token if cur_char = ':' read the next character if it is '=' then return assign else announce an error if cur_char = '/ peek at the next character if it is '*' or '/ read additional characters until "*/" or newline is seen, respectively jump back to top of code else return diy if cur_char = read the next character if it is a digit read any additional digits return mumber else announce an error if cur char is a digit read any additional digits and at most one decimal point return number if cur.char is a letter read any additional letters and digits check to see whether the resulting string is read or write if so then return the corresponding taken else return id else announce an error Example Pseudocode Problem: Given a sorted array a with n elements (i.e., a[0] top) b = 0 and stop. find the mid point mid of the array between bottom and top 2.2.2 Scanner Code We can implement a scanner that explicitly captures the circles-and-arrows structure of a DFA in cither of two main ways. One embeds the automaton in the control flow of the program using gotos or nested case (switch) statements the other, described in the following subsection, uses a table and a driver. As a general rule, handwritten automata tend to use nested case statements, while b) (a) Start .. ABC DEFG DEFG id Start DEFG Figure 2.10 Minimization of the DFA of Figure 29 nach seo we a set of sites to eliminate a tration ambiguity most automatically generated automata tise tables Tables are hard to create by hand, but easier than code to create from within a program. Likewise, nested case statements are easier to write and to debug than the ad hoc approach of Fig- ure 2.5, if not quite as efficient. Unix's lex/flex tool produces Clanguage output containing tables and a customized driver. The nested case statement style of automaton has the following general struc- ture EXAMPL 2.16 Nested case stment utomaton loop read curthar case state of 1: case our charol 2 case our charat case cur.charo The outer case statement covers the states of the finite automaton. The inner case statements cover the transitions out of each state. Most of the inner causes simply set a new state. Some return from the scanner with the current token. (If the current character should not be part of that token, it is pushed back onto the input stream before returning.) Two aspects of the code typically deviate from the strict form of a formal finite automaton. One is the handling of keywords. The other is the need to peek ahead when a token can validly be extended by two or more additional characters, but not by only one As noted at the beginning of Section 2.1.1, keywords in most languages look just like identifiers, but are reserved for a special purpose (some authors use the term reserved word instead of keyword). It is possible to write a finite automaton that distinguishes between keywords and identifiers, but it requires a lot of states (see Exercise 2.3). Most scanners, both handwritten and automatically generated, therefore treat keywords as "exceptions to the rule for identifiers. Before return Start DESIGN & IMPLEMENTATION 2.4 Recognizing multiple kinds of token One of the chief ways in which a scanner differs from a formal DFA is that it identifies tokens in addition to recognizing them. That is, it not only deter- mines whether characters constitute a valid token; it also indicates which one. In practice, this means that it must have separate final states for every kind of token. We glossed over this issue in our RE-to-DFA constructions, To build a scanner for a language with n different kinds of tokens, we begin with an NFA of the sort suggested in the figure Mi here. Given NFAs M.1
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance