

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
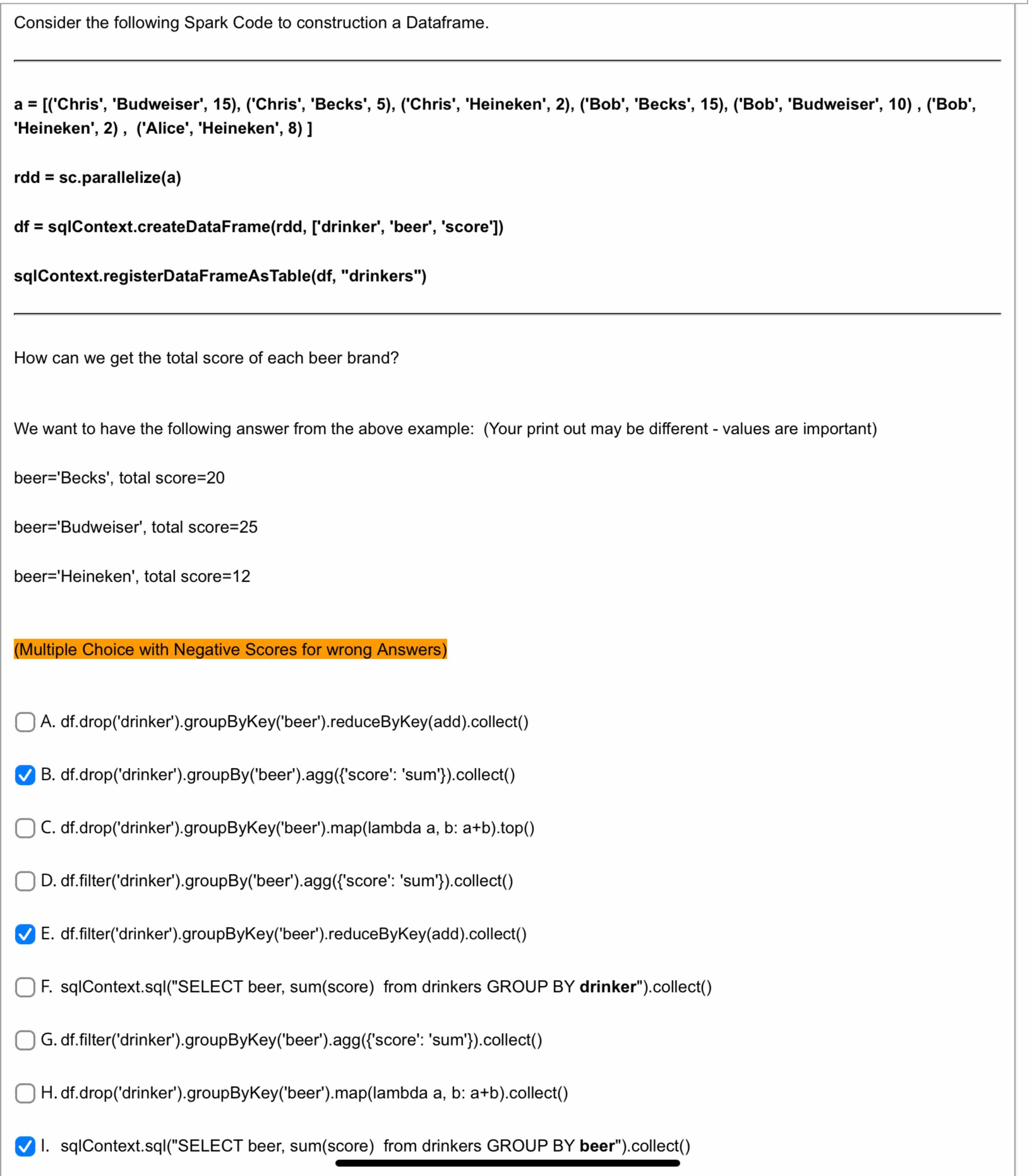
Consider the following Spark Code to construction a Dataframe. a = [ ( ' Chris ' , 'Budweiser', 1 5 ) , ( ' Chris
Consider the following Spark Code to construction a Dataframe.
a Chris 'Budweiser', Chris 'Becks', Chris 'Heineken', Bob 'Becks', Bob 'Budweiser', Bob
'Heineken', Alice 'Heineken',
rdd sc parallelize
df sqIContext.createDataFramerdddrinker 'beer', 'score'
sqIContext.registerDataFrameAsTabledf "drinkers"
How can we get the total score of each beer brand?
We want to have the following answer from the above example: Your print out may be different values are important
beer'Becks', total score
beer'Budweiser', total score
beer'Heineken', total score
Multiple Choice with Negative Scores for wrong Answers
A dfdropdrinkergroupByKeybeerreduceByKeyaddcollect
B dfdropdrinkergroupBybeeraggscore: 'sum'collect
C dfdropdrinkergroupByKeybeermaplambda a b: abtop
D dffilterdrinkergroupBybeeraggscore: 'sum'collect
E dffilterdrinkergroupByKeybeerreduceByKeyaddcollect
F sqIContext.sqlSELECT beer, sumscore from drinkers GROUP BY drinker"collect
G dffilterdrinkergroupByKeybeeraggscore: 'sum'collect
H dfdropdrinkergroupByKeybeermaplambda a b: abcollect
I. sqIContext.sqISELECT beer, sumscore from drinkers GROUP BY beer"collect
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Programming Languages 12th International Symposium Dbpl 2009 Lyon France August 2009 Proceedings Lncs 5708
Authors: Philippa Gardner ,Floris Geerts
2009th Edition
3642037925, 978-3642037924