create an Entity Relationship Diagram (ie, data model) of the Chateau Noir business, as shown in the case above. Starting from the provided starting point diagram, completely and correctly specify all Entities, Relationships and Attributes as described in the lecture and lab materials on Entity Relationship Diagramming. Include all relevant facts from the case into the model, including primary keys, volume estimates, data-types for all fields, descriptive labels on relationships, and italicization of foreign key fields. Ensure that your relationship lines do NOT cross or overlay, as this makes them hard to read. There is no need to create or assume any new business entities or attributes other than those required for the case above. Your final model should have exactly TEN entities and, if printed (not required), should fit on ONE 8.5 x 11 page. NOTE: In the starting point diagram, the number of lines with xs indicates the total number of expected attributes (including all keys). Do NOT re-organize this diagram.

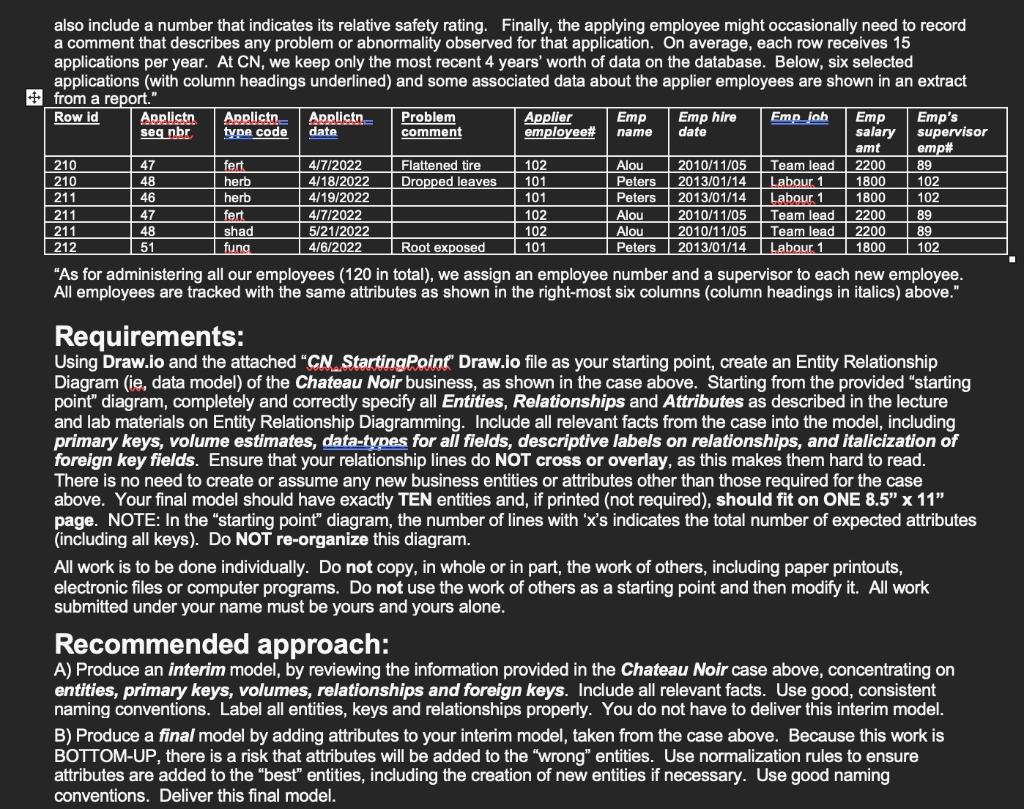

Chateau Noir (also called CN), a mid-sized winery located on a Summerland, BC plateau, enjoys an ideal climate for producing superb grapes. CN has developed a growing customer base due to imaginative marketing strategies, expansion into nearby orchard-lands and innovative use of technology. CN's owner, Clarice Sevier, is championing a database that will track treatments (called applications) for field-rows, as well as grape-samples and soil-samples against individual plants. "Let me describe my vision," Clarice says. "One: we celebrate the scandalous side of life and link it to our products. Two: we grow exceptional grapes at lower costs by taking advantage of local government incentives to convert tree-fruit orchards to vineyards, which consume less water. Three: we will use new, low-cost technologies to track each individual plant - this will give us more control over watering, sweetness and yield, and enables us to market 'high-tech select' vintages at premium prices." "To do this, first we must track our 180 fields, each of which is identified by a simple CN-generated field "id" number. For each field, we record a description of the zoning-address as well as the total number of hectares in the field. We also record the topsoil depth (estimated) in centimeters. Lastly, for each field we keep two indicators: one indicates whether or not the field is eligible to receive government assistance, and the other indicates whether or not we are temporarily leasing the field (before buying it)." "Each field has associated with it, on average, 50 rows for planting. To identify each row, we use a simple row "id" number. We also use a code to categorize each row based on the type of watering system installed - possible codes include spaw (spray watering), pipi (pipe irrigation), subi (sub-surface irrigation) or atnd (continuous drip). We associate watering types with rows, not fields, because a field might not have the same type for all of its rows. For each row, we must also track how thickly it is covered by grass (in percent) - we grow this grass to help prevent soil-loss. For each watering type, in addition to the above codes and descriptions, we also need to track its estimated cost per hectare and an indication of whether there is a tax incentive for that watering type (eg. ' Y ' for ctn) ). "Within each row, of course, we grow many individual grape-vines, simply called plants. On average, there are 40 plants per row. Each plant is identified by a CN-generated id number, which is attached to the plant as a seedling and then stays with it, even if it is transplanted somewhere else. We also capture the date it was planted, as well as its associated row-identifier and an estimate in meters of how far it is displaced from the beginning of its row. We must also, for each plant, record a code for its grape-type - we don't associate grape-types directly with rows, because it is possible for different plants in one row to be of different grape-types." within a field. In order to preserve the exact location, we mark each soil-sample with the associated plant id number, not the field identifier. For each soil-sample, we also record the sample date, the depth (in cm ) at which the sample was taken, and the id number of the analyzing employee. Each soil-sample records four additional numbers: the soil-sample's texture-diameter, saturation percentage, pH rating and nitrogen (N) rating in kgms per hectare. When taking soil-samples, a technician takes ten such samples on average for each field and does this three times per year." "On a scheduled basis, a grape-sample (identified with a sequential number) is taken from a randomly selected plant within a field. We mark each grape-sample with the associated plant number, as well as the sample-date and the quantity of individual grapes (called berries) in the sample (eg 10 or 12). When the sample is assessed for sweetness and tannin, we capture the id of the assessing employee, along with the numeric sweetness rating and tannin rating. A CN technician (not tracked) takes twenty such samples on average for each field and does this five times per year." "To support plant-health, we must regularly apply treatments called applications (such as fertilizer). When any application is done, it is done to exactly one entire row - any application to the next row is considered a separate application. To identify each application, we use a composite of two separate numbers: its row number plus an additional sequence number which starts at 1 for each row and increases by 1 for each application applied to that row: for example, row 185 application 01 vs row also include a number that indicates its relative safety rating. Finally, the applying employee might occasionally need to record a comment that describes any problem or abnormality observed for that application. On average, each row receives 15 applications per year. At CN, we keep only the most recent 4 years' worth of data on the database. Below, six selected applications (with column headings underlined) and some associated data about the applier employees are shown in an extract froma renort" "As for administering all our employees (120 in total), we assign an employee number and a supervisor to each new employee. All employees are tracked with the same attributes as shown in the right-most six columns (column headings in italics) above." Requirements: Using Draw.io and the attached "CN_StartingRoinf" Draw.io file as your starting point, create an Entity Relationship Diagram (ie, data model) of the Chateau Noir business, as shown in the case above. Starting from the provided "starting point" diagram, completely and correctly specify all Entities, Relationships and Attributes as described in the lecture and lab materials on Entity Relationship Diagramming. Include all relevant facts from the case into the model, including primary keys, volume estimates, data-types for all fields, descriptive labels on relationships, and italicization of foreign key fields. Ensure that your relationship lines do NOT cross or overlay, as this makes them hard to read. There is no need to create or assume any new business entities or attributes other than those required for the case above. Your final model should have exactly TEN entities and, if printed (not required), should fit on ONE 8.5" 11 page. NOTE: In the "starting point" diagram, the number of lines with ' x 's indicates the total number of expected attributes (including all keys). Do NOT re-organize this diagram. All work is to be done individually. Do not copy, in whole or in part, the work of others, including paper printouts, electronic files or computer programs. Do not use the work of others as a starting point and then modify it. All work submitted under your name must be yours and yours alone. Recommended approach: A) Produce an interim model, by reviewing the information provided in the Chateau Noir case above, concentrating on entities, primary keys, volumes, relationships and foreign keys. Include all relevant facts. Use good, consistent naming conventions. Label all entities, keys and relationships properly. You do not have to deliver this interim model. B) Produce a final model by adding attributes to your interim model, taken from the case above. Because this work is BOTTOM-UP, there is a risk that attributes will be added to the "wrong" entities. Use normalization rules to ensure attributes are added to the "best" entities, including the creation of new entities if necessary. Use good naming \begin{tabular}{|ll|} \hline & ????????? (?) \\ \hline PK ?????? & ??????? \\ \hline??????? & ?????? \\ ???????? & ?????? \\ ???????? & ?????? \\ \hline \end{tabular} \begin{tabular}{|l|l|} \hline \multicolumn{2}{|c|}{ ????????? (?) } \\ \hline PK ?????? & ??????? \\ \hline FK ?????? & ??????? \\ FK ????? & ?????? \\ ???????? & ?????? \\ \hline \end{tabular} \begin{tabular}{|ll|} \hline \multicolumn{2}{|c|}{ ????????? (?) } \\ \hline PK ?????? & ??????? \\ ???????? & ?????? \\ ???????? & ?????? \\ ???????? & ?????? \\ ???????? & ?????? \\ ???????? & ??????? \\ \hline \end{tabular}




