

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Do write proper pseudocode for this sample of code about recommending the book. import numpy as np import pandas as pd #importing modules pandas and
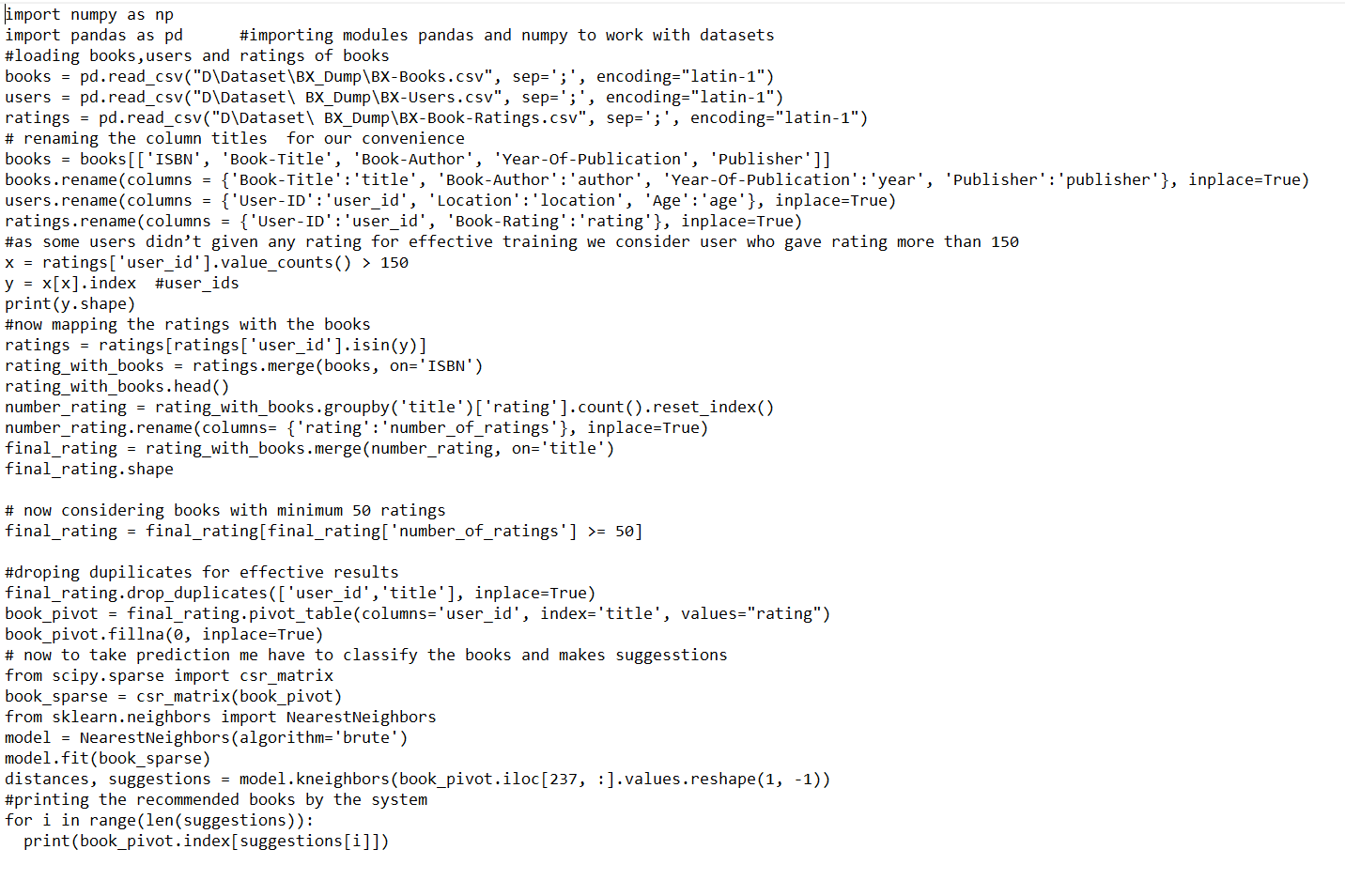
Do write proper pseudocode for this sample of code about recommending the book.
import numpy as np import pandas as pd #importing modules pandas and numpy to work with datasets #loading books, users and ratings of books books = pd.read_csv ("D\Dataset\BX_Dump\BX-Books.csv", sep=';', encoding="latin-1") users = pd.read_csv("D\Dataset\ BX_Dump\BX-Users.csv", sep=';' , encoding="latin-1") ratings = pd.read_csv("D\Dataset| BX_Dump\BX-Book-Ratings.csv", sep=';', encoding="latin-1") # renaming the column titles for our convenience books = books[['ISBN', 'Book-Title', 'Book-Author', 'Year-Of-Publication', 'Publisher']] books.rename(columns = {'Book Title':'title', 'Book-Author':'author', 'Year-Of-Publication': 'year', 'Publisher':'publisher'}, inplace=True) users.rename(columns = {'User-ID':'user_id', 'Location':'location', 'Age':'age'}, inplace=True) ratings.rename(columns = {'User-ID':'user_id', 'Book-Rating':'rating'}, inplace=True) #as some users didn't given any rating for effective training we consider user who gave rating more than 150 x = ratings['user_id'].value_counts() > 150 y = x[x]. index #user_ids print(y.shape) #now mapping the ratings with the books ratings = ratings[ratings['user_id'].isin(y)] rating_with_books = ratings.merge (books, on='ISBN') rating_with_books.head() number_rating = rating_with_books.groupby('title')['rating'].count().reset_index() number_rating.rename(columns= {'rating': 'number_of_ratings'}, inplace=True) final_rating = rating_with_books.merge(number_rating, on='title') final_rating.shape # now considering books with minimum 50 ratings final_rating = final_rating[final_rating['number_of_ratings'] >= 50] #droping dupilicates for effective results final_rating.drop_duplicates (['user_id', 'title'], inplace=True) book_pivot = final_rating.pivot_table(columns='user_id', index='title', values="rating") book_pivot.fillna(0, inplace=True) # now to take prediction me have to classify the books and makes suggesstions from scipy.sparse import csr_matrix book_sparse = csr_matrix(book_pivot) from sklearn.neighbors import NearestNeighbors model = NearestNeighbors (algorithm='brute') model.fit(book_sparse) distances, suggestions = model.kneighbors (book_pivot.iloc[237, :].values.reshape(1, -1)) #printing the recommended books by the system for i in range(len(suggestions)): print(book_pivot.index[suggestions[i]])Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
The Complete Database Marketer Tapping Your Customer Base To Maximize Sales And Increase Profits
Authors: Arthur M. Hughes
1st Edition
1557381925, 978-1557381927