

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Give a permutation for the values 0 through 7 that will cause Quicksort to have its worst case behavior. The image below are inforation concerning
Give a permutation for the values 0 through 7 that will cause Quicksort to have its worst case behavior. 




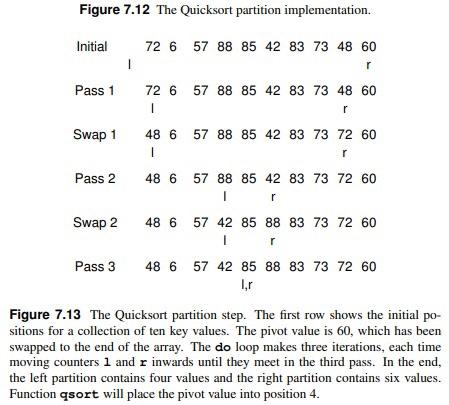

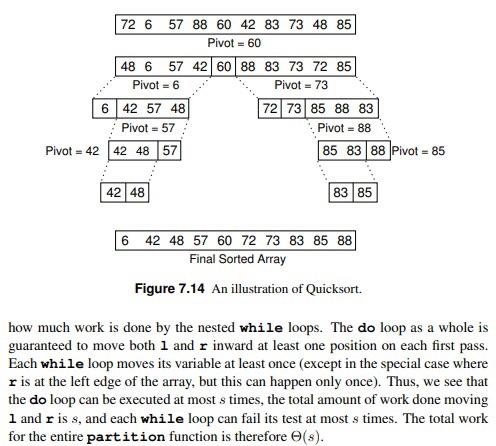






7.5 Quicksort While Mergesort uses the most obvious form of divide and conquer (split the list in half then sort the halves), it is not the only way that we can break down the sorting problem. And we saw that doing the merge step for Mergesort when using an array implementation is not so easy. So perhaps a different divide and conquer strategy might turn out to be more efficient? Quicksort is aptly named because, when properly implemented, it is the fastest known general-purpose in-memory sorting algorithm in the average case. It does not require the extra array needed by Mergesort, so it is space efficient as well. Quicksort is widely used, and is typically the algorithm implemented in a library sort routine such as the UNIX qsort function. Interestingly, Quicksort is ham- pered by exceedingly poor worst-case performance, thus making it inappropriate for certain applications. Before we get to Quicksort, consider for a moment the practicality of using a Binary Search Tree for sorting. You could insert all of the values to be sorted into the BST one by one, then traverse the completed tree using an inorder traversal. The output would form a sorted list. This approach has a number of drawbacks, including the extra space required by BST pointers and the amount of time required to insert nodes into the tree. However, this method introduces some interesting ideas. First, the root of the BST (i.e., the first node inserted) splits the list into two sublists: The left subtree contains those values in the list less than the root value while the right subtree contains those values in the list greater than or equal to the root value. Thus, the BST implicitly implements a "divide and conquer" approach to sorting the left and right subtrees. Quicksort implements this concept in a much more efficient way. Quicksort first selects a value called the pivot. (This is conceptually like the root node's value in the BST.) Assume that the input array contains k values less than the pivot. The records are then rearranged in such a way that the k values less than the pivot are placed in the first, or leftmost, k positions in the array, and the values greater than or equal to the pivot are placed in the last, or rightmost, n-k positions. This is called a partition of the array. The values placed in a given partition need not (and typically will not) be sorted with respect to each other. All that is required is that all values end up in the correct partition. The pivot value itself is placed in position k. Quicksort then proceeds to sort the resulting subarrays now on either side of the pivot, one of size k and the other of size n-k-1. How are these values sorted? Because Quicksort is such a good algorithm, using Quicksort on the subarrays would be appropriate. Unlike some of the sorts that we have seen earlier in this chapter, Quicksort might not seem very "natural" in that it is not an approach that a person is likely to use to sort real objects. But it should not be too surprising that a really efficient sort for huge numbers of abstract objects on a computer would be rather different from our experiences with sorting a relatively few physical objects. The Java code for Quicksort is shown in Figure 7.11. Parameters i and ; define the left and right indices, respectively, for the subarray being sorted. The initial call to Quicksort would be qsort (array, 0, n-1). Function partition will move records to the appropriate partition and then return k, the first position in the right partition. Note that the pivot value is initially static The image below are inforation concerning quick sort. 
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Beginning ASP.NET 2.0 And Databases
Authors: John Kauffman, Bradley Millington
1st Edition
0471781347, 978-0471781349