

Question: I am having issues with storing the maximum weight of each token Build a spam classifier by two methods, first through unsupervised learning (K-Means Clustering)
I am having issues with storing the maximum weight of each token
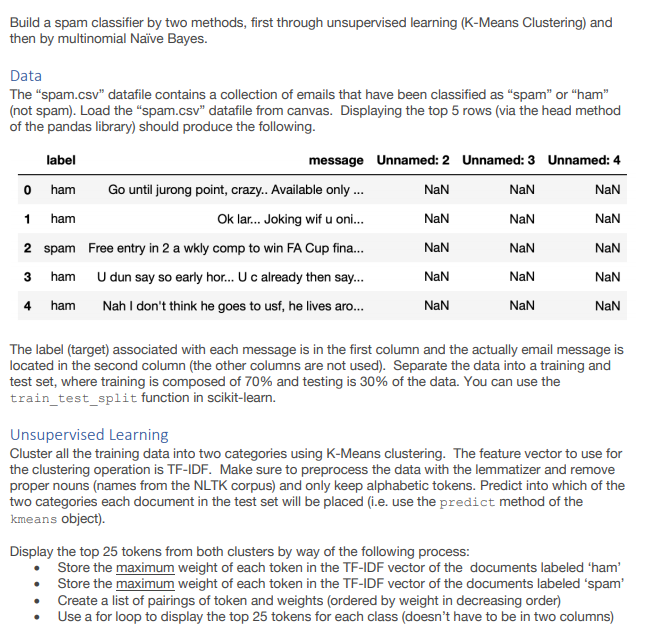
Build a spam classifier by two methods, first through unsupervised learning (K-Means Clustering) and then by multinomial Naive Bayes. Data The "spam.csv" datafile contains a collection of emails that have been classified as "spam" or "ham" (not spam). Load the "spam.csv" datafile from canvas. Displaying the top 5 rows (via the head method of the pandas library) should produce the following. label message Unnamed: 2 Unnamed: 3 Unnamed: 4 ham Go until jurong point, crazy.. Available only... NaN NaN NaN ham Ok lar... Joking wif u oni... NaN NaN NaN 2 spam Free entry in 2 a wkly comp to win FA Cup fina... NaN NaN NaN ham U dun say so early hor... U c already then say.. NaN NaN 4 ham Nah I don't think he goes to usf, he lives aro... NaN NaN 0 1 3 NaN NaN The label (target) associated with each message is in the first column and the actually email message is located in the second column (the other columns are not used). Separate the data into a training and test set, where training is composed of 70% and testing is 30% of the data. You can use the train_test_split function in scikit-learn. Unsupervised Learning Cluster all the training data into two categories using K-Means clustering. The feature vector to use for the clustering operation is TF-IDF. Make sure to preprocess the data with the lemmatizer and remove proper nouns (names from the NLTK corpus) and only keep alphabetic tokens. Predict into which of the two categories each document in the test set will be placed (i.e. use the predict method of the kmeans object). Display the top 25 tokens from both clusters by way of the following process: Store the maximum weight of each token in the TF-IDF vector of the documents labeled 'ham' Store the maximum weight of each token in the TF-IDF vector of the documents labeled 'spam' Create a list of pairings of token and weights (ordered by weight in decreasing order) Use a for loop to display the top 25 tokens for each class (doesn't have to be in two columns) Build a spam classifier by two methods, first through unsupervised learning (K-Means Clustering) and then by multinomial Naive Bayes. Data The "spam.csv" datafile contains a collection of emails that have been classified as "spam" or "ham" (not spam). Load the "spam.csv" datafile from canvas. Displaying the top 5 rows (via the head method of the pandas library) should produce the following. label message Unnamed: 2 Unnamed: 3 Unnamed: 4 ham Go until jurong point, crazy.. Available only... NaN NaN NaN ham Ok lar... Joking wif u oni... NaN NaN NaN 2 spam Free entry in 2 a wkly comp to win FA Cup fina... NaN NaN NaN ham U dun say so early hor... U c already then say.. NaN NaN 4 ham Nah I don't think he goes to usf, he lives aro... NaN NaN 0 1 3 NaN NaN The label (target) associated with each message is in the first column and the actually email message is located in the second column (the other columns are not used). Separate the data into a training and test set, where training is composed of 70% and testing is 30% of the data. You can use the train_test_split function in scikit-learn. Unsupervised Learning Cluster all the training data into two categories using K-Means clustering. The feature vector to use for the clustering operation is TF-IDF. Make sure to preprocess the data with the lemmatizer and remove proper nouns (names from the NLTK corpus) and only keep alphabetic tokens. Predict into which of the two categories each document in the test set will be placed (i.e. use the predict method of the kmeans object). Display the top 25 tokens from both clusters by way of the following process: Store the maximum weight of each token in the TF-IDF vector of the documents labeled 'ham' Store the maximum weight of each token in the TF-IDF vector of the documents labeled 'spam' Create a list of pairings of token and weights (ordered by weight in decreasing order) Use a for loop to display the top 25 tokens for each class (doesn't have to be in two columns)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts