

 I wanted to learn the second box
I wanted to learn the second box
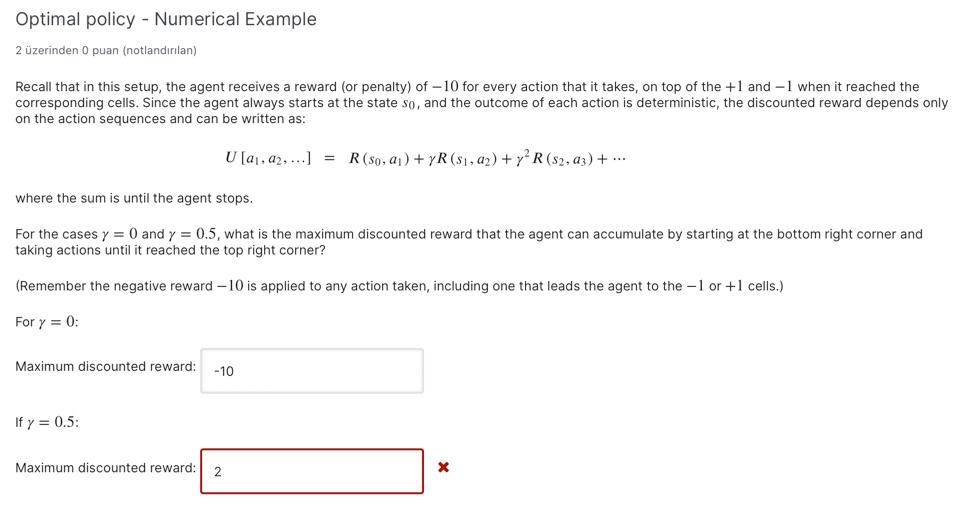
MDP Example: Negative Living Reward +1 -1 Agent's starting state Recall the MDP example in the lecture. An Al agent navigates in the 3x3 grid depicted above, where the middle square is not accessible (and hence is greyed out). The MDP is defined as follows. As before, every states is defined by the current position of the agent in the grid. The actions are the 4 directions "up", "down","left","right" Now, The transition probabilities from state s via action a to state s' is given by T (s, a, s') = P(s's, a). Reward structure: As before, the agent receives a reward of +1 for arriving at the top right cell, and a reward of -1 for arriving in the cell immediately below it. It does not receive any non-zero reward at the other cells as illustrated in the following figure. However, this time, the agent also receives a reward (or penalty) of -10 for every action that it takes, including any action that leads the agent into the +1 or -1 cells. Transition Probabilities: For simplicity, assume that all the transitions are deterministic. That is, given any states, the outcome of all actions are deterministic: The next state reached is completely predictable. For intance, taking the action "left" from the bottom right cell will always take the agent to the cell immediately to its left. Any action pointing off the grid would lead the agent to remain in its current cell. Initial State: Also, assume that the agent always starts off from the bottom right corner of the grid. It continues to take action until it reaches the top right corner, at which point it stops and does not act anymore. Optimal policy - Numerical Example 2 zerinden 0 puan (notlandrlan) Recall that in this setup, the agent receives a reward (or penalty) of -10 for every action that it takes, on top of the +1 and -1 when it reached the corresponding cells. Since the agent always starts at the state so, and the outcome of each action is deterministic, the discounted reward depends only on the action sequences and can be written as: U [41,42, ...] = R(80, 4) + YR (81, 42) + y R (52, 23) + ... where the sum is until the agent stops. For the cases y = 0 and y = 0.5, what is the maximum discounted reward that the agent can accumulate by starting at the bottom right corner and taking actions until it reached the top right corner? (Remember the negative reward -10 is applied to any action taken, including one that leads the agent to the - 1 or +1 cells.) For y = 0: Maximum discounted reward: -10 If y = 0.5: Maximum discounted reward: 2 x MDP Example: Negative Living Reward +1 -1 Agent's starting state Recall the MDP example in the lecture. An Al agent navigates in the 3x3 grid depicted above, where the middle square is not accessible (and hence is greyed out). The MDP is defined as follows. As before, every states is defined by the current position of the agent in the grid. The actions are the 4 directions "up", "down","left","right" Now, The transition probabilities from state s via action a to state s' is given by T (s, a, s') = P(s's, a). Reward structure: As before, the agent receives a reward of +1 for arriving at the top right cell, and a reward of -1 for arriving in the cell immediately below it. It does not receive any non-zero reward at the other cells as illustrated in the following figure. However, this time, the agent also receives a reward (or penalty) of -10 for every action that it takes, including any action that leads the agent into the +1 or -1 cells. Transition Probabilities: For simplicity, assume that all the transitions are deterministic. That is, given any states, the outcome of all actions are deterministic: The next state reached is completely predictable. For intance, taking the action "left" from the bottom right cell will always take the agent to the cell immediately to its left. Any action pointing off the grid would lead the agent to remain in its current cell. Initial State: Also, assume that the agent always starts off from the bottom right corner of the grid. It continues to take action until it reaches the top right corner, at which point it stops and does not act anymore. Optimal policy - Numerical Example 2 zerinden 0 puan (notlandrlan) Recall that in this setup, the agent receives a reward (or penalty) of -10 for every action that it takes, on top of the +1 and -1 when it reached the corresponding cells. Since the agent always starts at the state so, and the outcome of each action is deterministic, the discounted reward depends only on the action sequences and can be written as: U [41,42, ...] = R(80, 4) + YR (81, 42) + y R (52, 23) + ... where the sum is until the agent stops. For the cases y = 0 and y = 0.5, what is the maximum discounted reward that the agent can accumulate by starting at the bottom right corner and taking actions until it reached the top right corner? (Remember the negative reward -10 is applied to any action taken, including one that leads the agent to the - 1 or +1 cells.) For y = 0: Maximum discounted reward: -10 If y = 0.5: Maximum discounted reward: 2 x




