I would like some help on the following parts. I have started the code for Part 2 and I need help for that part and Part 3.
Thank you for your time and effort.
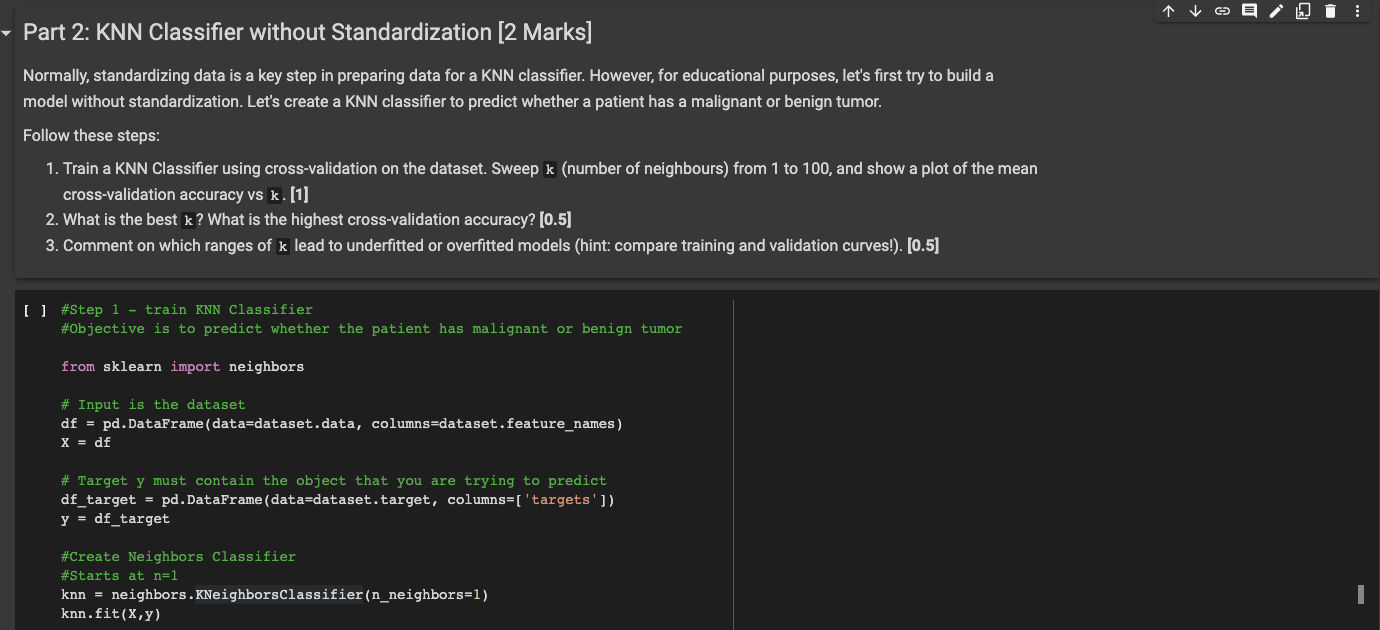

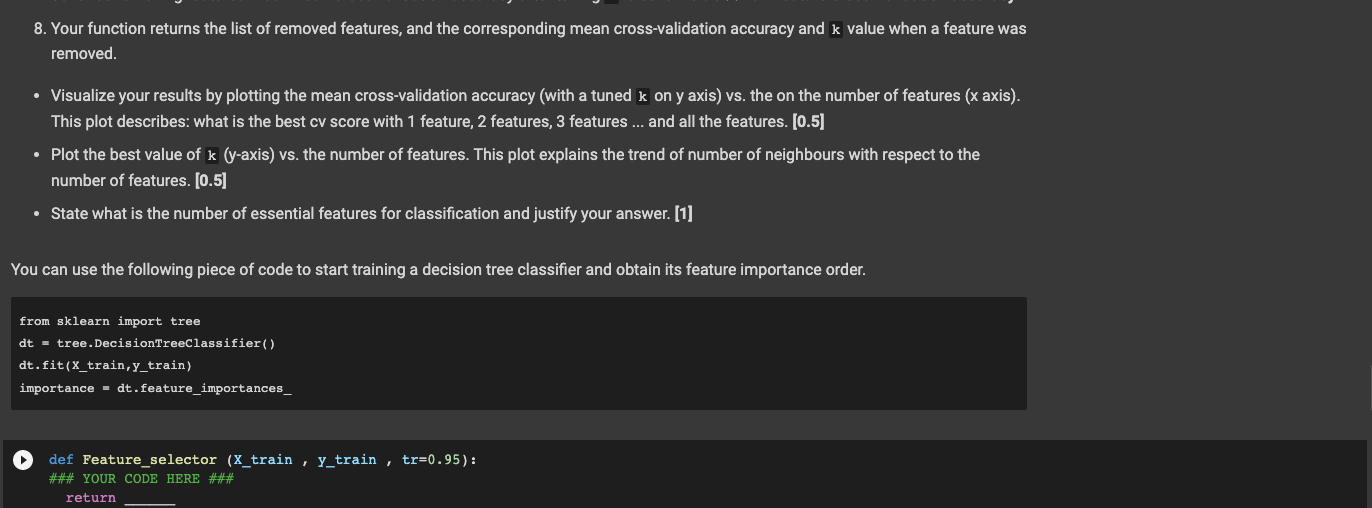
Part 2: KNN Classifier without Standardization [2 marks] Normally, standardizing data is a key step in preparing data for a KNN classifier. However, for educational purposes, let's first try to build a model without standardization. Let's create a KNN classifier to predict whether a patient has a malignant or benign tumor. Follow these steps: 1. Train a KNN Classifier using cross-validation on the dataset. Sweep k (number of neighbours) from 1 to 100, and show a plot of the mean cross-validation accuracy vs k. [1] 2. What is the best k? What is the highest cross-validation accuracy? (0.5) 3. Comment on which ranges of k lead to underfitted or overfitted models (hint: compare training and validation curves!). [0.5) U #Step 1 - train KNN Classifier #Objective is to predict whether the patient has malignant or benign tumor from sklearn import neighbors # Input is the dataset df = pd. DataFrame (data=dataset.data, columns=dataset.feature_names) x = df # Target y must contain the object that you are trying to predict df_target = pd.DataFrame (data=dataset.target, columns=['targets']) y = df_target #Create Neighbors Classifier #Starts at n=1 knn = neighbors .KNeighborsClassifier (n_neighbors=1) knn.fit(x,y) - Part 3: Feature Selection (3 Marks] In this part, we aim to investigate the importance of each feature on the final classification accuracy. If we want to try every possible combination of features, we would have to test 2F different cases, where F is the number of features, and in each case, we have to do a hyperparameter search (finding K, in KNN using cross-validation). That will take days! To find more important features we will use a decision tree. based on a decision tree we can compute feature importance that is a metric for our feature selection (code is provided below). You can use this link to get familiar with extracting the feature impotance order of machine learning algorithms in Python. After we identified and removed the least important feature and evaluated a new KNN model on the new set of features, if the stop conditions (see step 7 below) are not met, we need to repeat the process and remove another feature. Design a function ( Feature_selector) that accepts your dataset (X_train ,y_train) and a threshold as inputs and: [1] 1. Fits a decision tree classifier on the training set. 2. Extracts the feature importance order of the decision tree model. 3. Removes the least important feature based on step 2. 4. Then, a KNN model is trained on the remaining features. The number of neighbors (k) for each KNN model should be tuned using a 5-fold cross-validation 5. Store the best mean cross-validation score and the corresponding k (number of neighbours) value in two lists. 6. Go back to step 3 and follow all the steps until you meet the stop condition (step 7). 7. We will stop this process when (1) there is only one feature left, or (2) our cross-validation accuracy is dropped significantly compared to a model that uses all the features. In this function, we accept a threshold as an input argument. For example, if threshold=0.95 we do not continue removing features if our mean cross-validation accuracy after tuning k is bellow 0.95 x Full Feature cross-validation accuracy. 8. Your function returns the list of removed features, and the corresponding mean cross-validation accuracy and k value when a feature was removed. Visualize your results by plotting the mean cross-validation accuracy (with a tuned k on y axis) vs. the on the number of features (x axis). This plot describes: what is the best cv score with 1 feature, 2 features, 3 features ... and all the features. (0.5) Plot the best value of k (y-axis) vs. the number of features. This plot explains the trend of number of neighbours with respect to the number of features. (0.5) State what is the number of essential features for classification and justify your answer. [1] You can use the following piece of code to start training a decision tree classifier and obtain its feature importance order. from sklearn import tree dt - tree. DecisionTreeClassifier() dt. fit(x_train, y_train) importance - dt.feature_importances_ def Feature_selector (x_train , y_train, tr=0.95): ### YOUR CODE HERE ### return Part 2: KNN Classifier without Standardization [2 marks] Normally, standardizing data is a key step in preparing data for a KNN classifier. However, for educational purposes, let's first try to build a model without standardization. Let's create a KNN classifier to predict whether a patient has a malignant or benign tumor. Follow these steps: 1. Train a KNN Classifier using cross-validation on the dataset. Sweep k (number of neighbours) from 1 to 100, and show a plot of the mean cross-validation accuracy vs k. [1] 2. What is the best k? What is the highest cross-validation accuracy? (0.5) 3. Comment on which ranges of k lead to underfitted or overfitted models (hint: compare training and validation curves!). [0.5) U #Step 1 - train KNN Classifier #Objective is to predict whether the patient has malignant or benign tumor from sklearn import neighbors # Input is the dataset df = pd. DataFrame (data=dataset.data, columns=dataset.feature_names) x = df # Target y must contain the object that you are trying to predict df_target = pd.DataFrame (data=dataset.target, columns=['targets']) y = df_target #Create Neighbors Classifier #Starts at n=1 knn = neighbors .KNeighborsClassifier (n_neighbors=1) knn.fit(x,y) - Part 3: Feature Selection (3 Marks] In this part, we aim to investigate the importance of each feature on the final classification accuracy. If we want to try every possible combination of features, we would have to test 2F different cases, where F is the number of features, and in each case, we have to do a hyperparameter search (finding K, in KNN using cross-validation). That will take days! To find more important features we will use a decision tree. based on a decision tree we can compute feature importance that is a metric for our feature selection (code is provided below). You can use this link to get familiar with extracting the feature impotance order of machine learning algorithms in Python. After we identified and removed the least important feature and evaluated a new KNN model on the new set of features, if the stop conditions (see step 7 below) are not met, we need to repeat the process and remove another feature. Design a function ( Feature_selector) that accepts your dataset (X_train ,y_train) and a threshold as inputs and: [1] 1. Fits a decision tree classifier on the training set. 2. Extracts the feature importance order of the decision tree model. 3. Removes the least important feature based on step 2. 4. Then, a KNN model is trained on the remaining features. The number of neighbors (k) for each KNN model should be tuned using a 5-fold cross-validation 5. Store the best mean cross-validation score and the corresponding k (number of neighbours) value in two lists. 6. Go back to step 3 and follow all the steps until you meet the stop condition (step 7). 7. We will stop this process when (1) there is only one feature left, or (2) our cross-validation accuracy is dropped significantly compared to a model that uses all the features. In this function, we accept a threshold as an input argument. For example, if threshold=0.95 we do not continue removing features if our mean cross-validation accuracy after tuning k is bellow 0.95 x Full Feature cross-validation accuracy. 8. Your function returns the list of removed features, and the corresponding mean cross-validation accuracy and k value when a feature was removed. Visualize your results by plotting the mean cross-validation accuracy (with a tuned k on y axis) vs. the on the number of features (x axis). This plot describes: what is the best cv score with 1 feature, 2 features, 3 features ... and all the features. (0.5) Plot the best value of k (y-axis) vs. the number of features. This plot explains the trend of number of neighbours with respect to the number of features. (0.5) State what is the number of essential features for classification and justify your answer. [1] You can use the following piece of code to start training a decision tree classifier and obtain its feature importance order. from sklearn import tree dt - tree. DecisionTreeClassifier() dt. fit(x_train, y_train) importance - dt.feature_importances_ def Feature_selector (x_train , y_train, tr=0.95): ### YOUR CODE HERE ### return




