

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
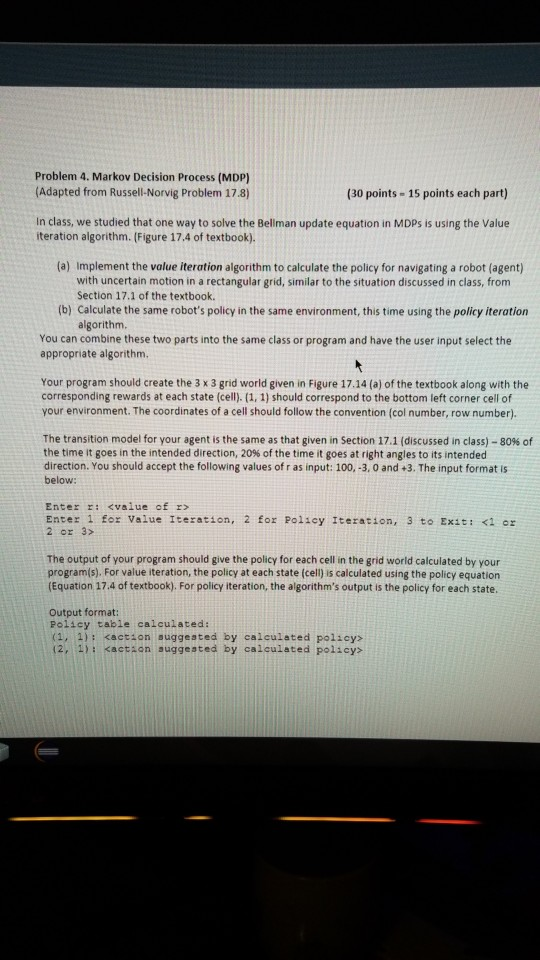
in java Problem 4. Markov Decision Process (MDP) (Adapted from Russell-Norvig Problem 178) (30 points 15 points each part) In class, we studied that one
in java
Problem 4. Markov Decision Process (MDP) (Adapted from Russell-Norvig Problem 178) (30 points 15 points each part) In class, we studied that one way to solve the Bellman update equation in MDPs is using the Value iteration algorithm. (Figure 17.4 of textbook). (a) Implement the value iteration algorithm to calculate the policy for navigating a robot (agent) with uncertain motion in a rectangular grid, similar to the situation discussed in class, from Section 17.1 of the textbook. (b) Calculate the same robot's policy in the same environment, this time using the policy iteration algorithm. You can combine these two parts into the same class or program and have the user input select the appropriate algorithm. Your program should create the 3 x 3 grid world given in Figure 17.14 (a) of the textbook along with the corresponding rewards at each state (cell). (1, 1) should correspond to the bottom left corner cell of your environment. The coordinates of a cell should follow the convention (col number, row number). The transition model for your agent is the same as that given in Section 17.1(discussed in class)-80% of the time it goes in the intended direction, 20% of the time it goes at right angles to its intended direction. You should accept the following values of r as input: 100, -3. 0 and +3. The input format is below: Enter rStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Oracle PL/SQL Programming Database Management Systems
Authors: Steven Feuerstein
1st Edition
978-1565921429