

Question
IN THE CODE YOU WILL SEE WHERE IT SAYS WHERE THE CODE SHOULD BE PROVIDED IN THE MAPPER AND REDUCER. SOMEONE PLEASE SOLVE THE CODE.
IN THE CODE YOU WILL SEE WHERE IT SAYS WHERE THE CODE SHOULD BE PROVIDED IN THE MAPPER AND REDUCER. SOMEONE PLEASE SOLVE THE CODE. THANKS
Dataset: The toy dataset is the following graph. The PageRank values are already known. We can use it to check your program.
Figure 1:
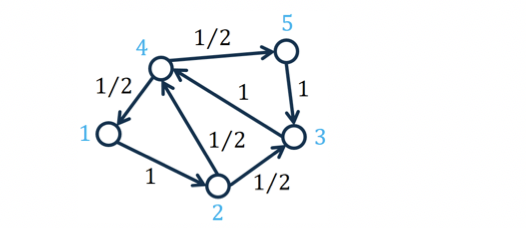
A toy graph for computing PageRank. The number on the edge represents the transition probability from one node to another.
The PageRank values are given in the following table (given that the decay factor c=0.85):
Nodes PageRank Values
1 0.1556
2 0.1622
3 0.2312
4 0.2955
5 0.1556
PageRank: Compute the PageRank value of each node in the graph. Please refer to the slides for more details about the PageRank method. The key PageRank equation is as follows. r=cP^ r+(1-c)1
where r represents the n1 PageRank vector with each element r_i representing the PageRank value of node i, n represents the number of nodes in the graph, P represents the nn transition probability matrix with each element P_(i,j)=p_(i,j)=1/d_i representing the transition probability from node i to node j, d_i represents the degree of node i, P^ represents the transpose of P, c(0,1) represents a decay factor, 1 represents a n1 vector of all 1's, and n represents the number of nodes in the graph.
Please see the slides for more details.
In this assignment, we set the decay factor c=0.85 and set the number of iterations to 30.
Implementation: Design and implement a MapReduce program to compute the PageRank values. A template "PageRankIncomplete.java" file is given. You need to add four sentences in the file.
Example command: hadoop jar PageRank.jar /user/rob/pagerank/01InitialPRValues.txt /user/rob/pagerank/02AdjacencyList.txt /user/rob/pagerank/out01 30
The files were uploaded into HDFS.
Report:
Please write a report illustrating your experiments. You need to explain your basic idea about how to design the computing algorithm. You may add comments to the source code such that the source code can be read and understood by the graders.
In the report, you should include the answers to the following questions.
1) Explanation of the source code:
1.1) How is the Mapper function defined? Which kind of intermediate results are generated?
1.2) How is the Reducer function defined? How do you aggregate the intermediate results and get the final outputs?
1.3) Do you use a Combiner function? Why or why not?
2) Experimental Results
2.1) Screenshots of the key steps. For example, the screenshot for the outputs in the terminal when you run "Hadoop jar YourJarFile" command. It will demonstrate that your program has no bug.
2.2) Explain your results. Does your implementation give the exact PageRank values? How large are the errors? Submission Materials:
a) Your report
b) Source code (.java file) and the .jar file for the Hadoop
c) The output file of your program.
THIS IS THE JAVA CODE BUT IT IS MISSING 4 LINES
PageRankIncomplete.java is the template java file. It is incomplete. You need to add four lines in total. If you see the comment "// You need to add one sentence here.", you need to add one line there.
package Assignments;
import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.util.HashMap; import java.util.Map; import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageRankIncomplete {
public static class PowerIterationMapper extends Mapper
public static class PowerIterationReducer extends Reducer
// The PageRank Values of all the nodes; the PageRank vector private Map
public void reduce(IntWritable key, Iterable
public static void main(String[] args) throws Exception { // args[0] the initial PageRank values String sInputPathForOneIteration = args[0]; // args[1] the input file containing the adjacency list of the graph String sInputAdjacencyList = args[1]; // args[2] Output path String sExpPath = args[2]; String sOutputFilenameForPreviousIteration = ""; // args[3] number of iterations Integer nNumOfTotalIterations = Integer.parseInt(args[3]); for (Integer nIdxOfIteration = 0; nIdxOfIteration 0) { // In the Iteration 2, 3, 4, ..., // the output of the previous iteration => the input of this iteration sInputPathForOneIteration = sOutputFilenameForPreviousIteration; } job.addCacheFile(new Path(sInputPathForOneIteration).toUri()); FileInputFormat.addInputPath(job, new Path(sInputAdjacencyList)); // Change the output directory String sOutputPath = sExpPath + "/Iteration" + nIdxOfIteration.toString() + "/"; String sOutputFilename = sOutputPath + "part-r-00000"; sOutputFilenameForPreviousIteration = sOutputFilename; FileOutputFormat.setOutputPath(job, new Path(sOutputPath)); if (nIdxOfIteration 3 5 1 2 1 2 1 1 4 2 1 1 3 5 1 2 1 2 1 1 4 2 1 1
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Intelligent Information And Database Systems 12th Asian Conference ACIIDS 2020 Phuket Thailand March 23 26 2020 Proceedings
Authors: Pawel Sitek ,Marcin Pietranik ,Marek Krotkiewicz ,Chutimet Srinilta
1st Edition
9811533792, 978-9811533792