

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
movies table: actors table: tags table: genres table: Use MySql or Postgresql to answer this question please (1) We will now write some queries for

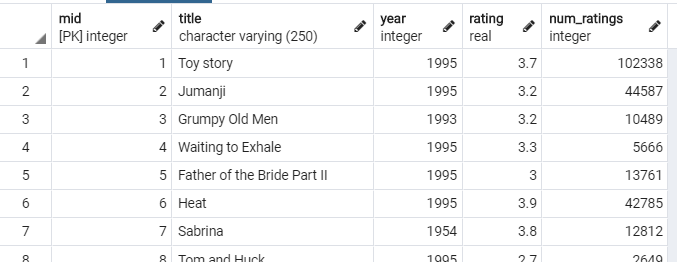
movies table:
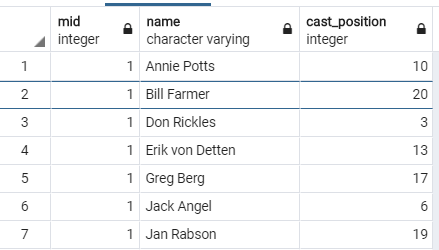
actors table:
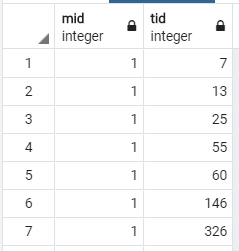
tags table:
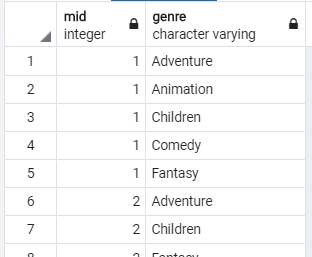
genres table:
Use MySql or Postgresql to answer this question please
(1) We will now write some queries for a Content-Based Movie Recommendation Sys- tem such as NetFlix. In reality, the accuracy of the recommendations is so important that NetFlix, for instance, offered a prize of one million dollars for the first algorithm that could beat its own recommendation algorithm by 10%! The prize was finally won in 2009, by a team of researchers called "Bellkor's Pragmatic Chaos. However, in this project we shall deploy a simple algorithm that may or may not produce optimal recommendations. Content-based recommendations focus on the properties of items, in our case movies. The similarity of two movies is determined by measuring the similarity of their properties. For a movie item, we shall consider the following five properties: actors, taga, genres, year, and rating Given two movies X and Y, the similarity of Y to X, sim(X,Y), can be computed 24: fraction of common actors + fraction of common tage + fraction of common genres + age gap + rating gap where fraction is the number of common elements between X and Y divided by the number of elements of X, age gap is the normalized difference between the production years of X and Y, and rating gap is the normalized difference between the ratings of X and Y. Intuitively, the smaller the gaps are, the better since movies of the same decade and rating are more likely to be similar). Moreover, note that we divide by five because each property is given an equal weight of 1. Given a user who is known to like the movie 'Mr. & Mrs. Smith', write a query that prints the movie title, rating, and similarity percentage i.e., similarity x 100) for the top 10 movies that are most similar to the 'Mr. & Mrs. Smith' movie, ordered by the similarity percentage. Use tricus to answer this questions rating mid [PK] integer real num_ratings integer 102338 3.7 3.2 title character varying (250) ving (250) 1 Toy story 2 Jumanji 3 Grumpy Old Men 4 Waiting to Exhale 5 Father of the Bride Part II 6 Heat 7 Sabrina year integer 1995 1995 1993 1995 1995 1995 1954 44587 10489 5666 13761 42785 12812 8 Tom and Huck 1905 2610 mid integer cast_position integer name character varying 1 Annie Potts 1 Bill Farmer 1 Don Rickles 1 Erik von Detten 1 Greg Berg 1 Jack Angel 1 Jan Rabson tid mid integer integer 146 326 mid integer genre character varying 1 Adventure 1 Animation 1 Children 1 Comedy 1 Fantasy 2 Adventure 2 Children Ponto (1) We will now write some queries for a Content-Based Movie Recommendation Sys- tem such as NetFlix. In reality, the accuracy of the recommendations is so important that NetFlix, for instance, offered a prize of one million dollars for the first algorithm that could beat its own recommendation algorithm by 10%! The prize was finally won in 2009, by a team of researchers called "Bellkor's Pragmatic Chaos. However, in this project we shall deploy a simple algorithm that may or may not produce optimal recommendations. Content-based recommendations focus on the properties of items, in our case movies. The similarity of two movies is determined by measuring the similarity of their properties. For a movie item, we shall consider the following five properties: actors, taga, genres, year, and rating Given two movies X and Y, the similarity of Y to X, sim(X,Y), can be computed 24: fraction of common actors + fraction of common tage + fraction of common genres + age gap + rating gap where fraction is the number of common elements between X and Y divided by the number of elements of X, age gap is the normalized difference between the production years of X and Y, and rating gap is the normalized difference between the ratings of X and Y. Intuitively, the smaller the gaps are, the better since movies of the same decade and rating are more likely to be similar). Moreover, note that we divide by five because each property is given an equal weight of 1. Given a user who is known to like the movie 'Mr. & Mrs. Smith', write a query that prints the movie title, rating, and similarity percentage i.e., similarity x 100) for the top 10 movies that are most similar to the 'Mr. & Mrs. Smith' movie, ordered by the similarity percentage. Use tricus to answer this questions rating mid [PK] integer real num_ratings integer 102338 3.7 3.2 title character varying (250) ving (250) 1 Toy story 2 Jumanji 3 Grumpy Old Men 4 Waiting to Exhale 5 Father of the Bride Part II 6 Heat 7 Sabrina year integer 1995 1995 1993 1995 1995 1995 1954 44587 10489 5666 13761 42785 12812 8 Tom and Huck 1905 2610 mid integer cast_position integer name character varying 1 Annie Potts 1 Bill Farmer 1 Don Rickles 1 Erik von Detten 1 Greg Berg 1 Jack Angel 1 Jan Rabson tid mid integer integer 146 326 mid integer genre character varying 1 Adventure 1 Animation 1 Children 1 Comedy 1 Fantasy 2 Adventure 2 Children PontoStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Fundamentals Of Database Systems
Authors: Ramez Elmasri, Sham Navathe
4th Edition
0321122267, 978-0321122261