

Question: Need a Python code to able fill out the table below: For this assignment, you are to determine which model is best for prediction, report
Need a Python code to able fill out the table below:
For this assignment, you are to determine which model is best for prediction, report the right hyperparameters, and the resulting accuracy for the Digit Recognition data set that was used in this python code:
import numpy as np import pandas as pd from sklearn import datasets from sklearn.metrics import confusion_matrix from sklearn.model_selection import train_test_split
def euclidean_distance(x1, x2): return np.sqrt(np.sum((x1 - x2)**2))
def predict(X_train, y_train, x, k): distances = [] for i in range(X_train.shape[0]): dist = euclidean_distance(X_train[i], x) distances.append((dist, y_train[i])) distances = sorted(distances) top_k = distances[:k] y_freq = {} for i in range(len(top_k)): if top_k[i][1] in y_freq: y_freq[top_k[i][1]] += 1 else: y_freq[top_k[i][1]] = 1 return max(y_freq, key=y_freq.get)
def kNN(X_train, y_train, X_test, k): predictions = [] for x in X_test: pred = predict(X_train, y_train, x, k) predictions.append(pred) return predictions
def accuracy(y_true, y_pred): return np.sum(y_true == y_pred) / len(y_true)
def classify_kNN(): digits = datasets.load_digits() X = digits.images.reshape(len(digits.images), -1) y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
ks = [1, 3, 5, 100, 500] for k in ks: y_pred = kNN(X_train, y_train, X_test, k) acc = accuracy(y_test, y_pred) print("Accuracy for k =", k, ":", acc) cm = confusion_matrix(y_test, y_pred) print("Confusion Matrix for k =", k, ": ", cm)
if __name__ == "__main__": classify_kNN()
create a PDF of your notebook showing your steps and include the table below as mentioned. Attach both a Jupyter notebook and the PDF version.
Steps are as follows: 1. Separate your data into training and testing. We will use cross-validation over the training set to select the right parameters
a. Use train_test_split to create a separate training and test set. X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=True, test_size=0.20)
b. For the training set, you have two choices to perform hyperparameter selection. i. Use cross-validation to evaluate each model variant and select the best hyperparameters (standard practice, most recommended)
ii. Create a hold-out validation set and train on one portion of the data and use the accuracy on the hold-out validation set to pick the right hyperparameters (also valid)
2. Steps to turn in for the assignment (Deliverables):
a. Train the four models with their default parameters. Report the resulting accuracy of each model using the default parameters.
b. For each of the four models, find the hyperparameters giving the highest accuracy on the validation set by performing an exhaustive grid search. Report the hyperparameter values and accuracy on the validation set.
i. Consider using sklearn.model_selection.GridSearchCV
ii. For the models with two hyperparameters, you will need to search both simultaneously to find the optimum combination
c. Now apply the highest accuracy trained models to the test set. Report the accuracy of each model.
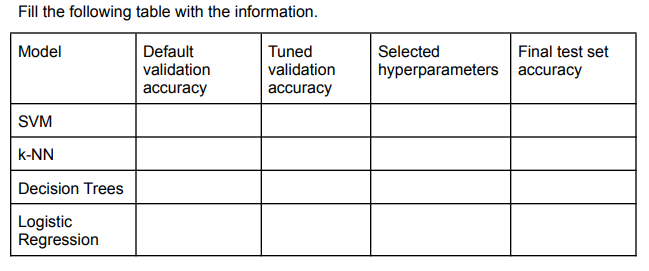
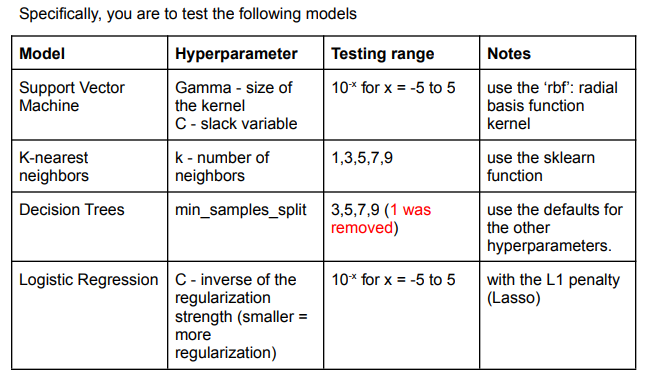
Specifically, you are to test the following models Fill the following table with the information
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts