Need help with a practice problem in C sharp cant really rap my head around need to see how its done with comments to better understand. Theres a skeleton of the code of how its supposed to be done attached below, done it before but never like this not really used to working with nodes

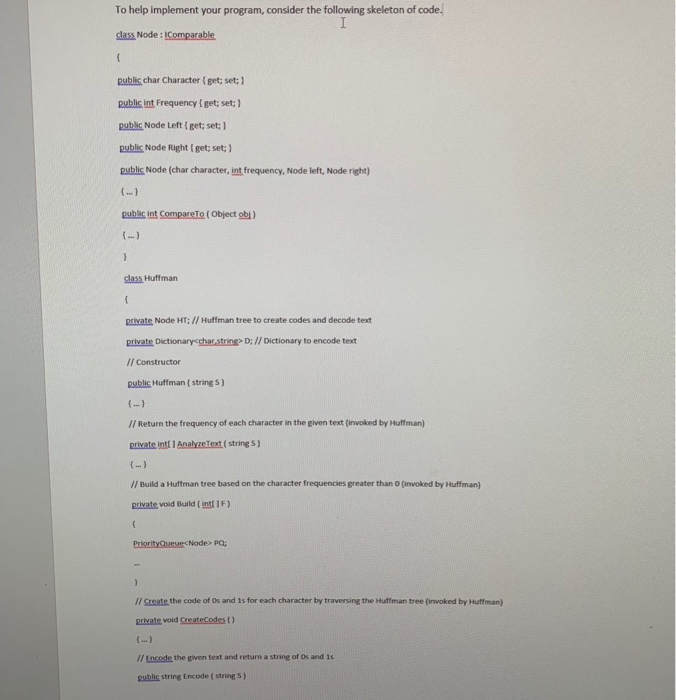
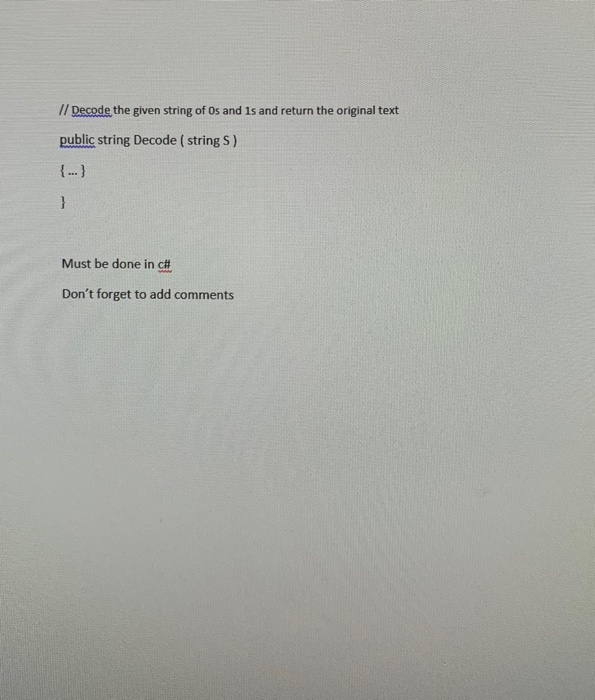
In 1952, David Huffman published a paper called "A Method for the Construction of Minimum-Redundancy Codes" It was a seminal paper. Given a text of characters where each character occurs with a freque greater than 0, Huffman found a way to encode each character as a unique sequence of O's and 1's such that the overall length (number of bits) of the encoded text was minimized. Huffman recognized that characters with a greater frequency should have shorter codes than those with a lower frequency. Therefore, to disambiguate two codes, no shorter code of O's and 1's can serve as the prefix (beginning) of a longer code. For example, if letter 'a' has a code of 010, no other character can have a code that begins with 010. To find these codes, a Huffman tree is constructed. The Huffman tree is a binary tree where the left edge of each node is associated with the number 0 and the right edge is associated with the number 1. All characters are stored as leaf nodes and the code associated with each character is the sequence of O's and 1's along the path from the root to the character Requirements Problem 1:s The principle class to implement is called Huffman which tackles each of the following tasks. Task 1: Determine the Character Frequencies Determine the frequency of each character in the given text and store it in an array. For simplicity, only lowercase letters from 'a to 'z , upper-case letters from A' to Z, and the blank space) are admissible as characters (see Analyze Text) Task 2: Build the Huffman Tree Using a priority queue of binary trees, a Huffman tree is constructed for the given text. Initially, the priority queue is populated with as many as 53 individual nodes (binary trees of sze 1) where each node stores a character and its frequency. The priority queue is ordered by frequency where a binary tree with a lower total frequency has a higher priority than one with a higher total frequency (see Build). Task 3: Create the Codes The final Huffman tree is then traversed in a prefix manner such that the code for each character is stored as a strin, of 0s and 1s, and placed in an instance of the C# Dictionar y class using its associated character as the key see CreateCodes). Task 4: Encode Using the dictionary of codes, a given text is converted into a string of Os and 1s (see Encode) Task 5: Decode Using the Huffman tree, a given string of Os and is to converted back into the original text (see Decode). In 1952, David Huffman published a paper called "A Method for the Construction of Minimum-Redundancy Codes" It was a seminal paper. Given a text of characters where each character occurs with a freque greater than 0, Huffman found a way to encode each character as a unique sequence of O's and 1's such that the overall length (number of bits) of the encoded text was minimized. Huffman recognized that characters with a greater frequency should have shorter codes than those with a lower frequency. Therefore, to disambiguate two codes, no shorter code of O's and 1's can serve as the prefix (beginning) of a longer code. For example, if letter 'a' has a code of 010, no other character can have a code that begins with 010. To find these codes, a Huffman tree is constructed. The Huffman tree is a binary tree where the left edge of each node is associated with the number 0 and the right edge is associated with the number 1. All characters are stored as leaf nodes and the code associated with each character is the sequence of O's and 1's along the path from the root to the character Requirements Problem 1:s The principle class to implement is called Huffman which tackles each of the following tasks. Task 1: Determine the Character Frequencies Determine the frequency of each character in the given text and store it in an array. For simplicity, only lowercase letters from 'a to 'z , upper-case letters from A' to Z, and the blank space) are admissible as characters (see Analyze Text) Task 2: Build the Huffman Tree Using a priority queue of binary trees, a Huffman tree is constructed for the given text. Initially, the priority queue is populated with as many as 53 individual nodes (binary trees of sze 1) where each node stores a character and its frequency. The priority queue is ordered by frequency where a binary tree with a lower total frequency has a higher priority than one with a higher total frequency (see Build). Task 3: Create the Codes The final Huffman tree is then traversed in a prefix manner such that the code for each character is stored as a strin, of 0s and 1s, and placed in an instance of the C# Dictionar y class using its associated character as the key see CreateCodes). Task 4: Encode Using the dictionary of codes, a given text is converted into a string of Os and 1s (see Encode) Task 5: Decode Using the Huffman tree, a given string of Os and is to converted back into the original text (see Decode)




