

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Please do this and explain in Java(PS. Do not use HashMap in this task). The goal of this assignment is to demonstrate your mastery of
Please do this and explain in Java(PS. Do not use HashMap in this task).

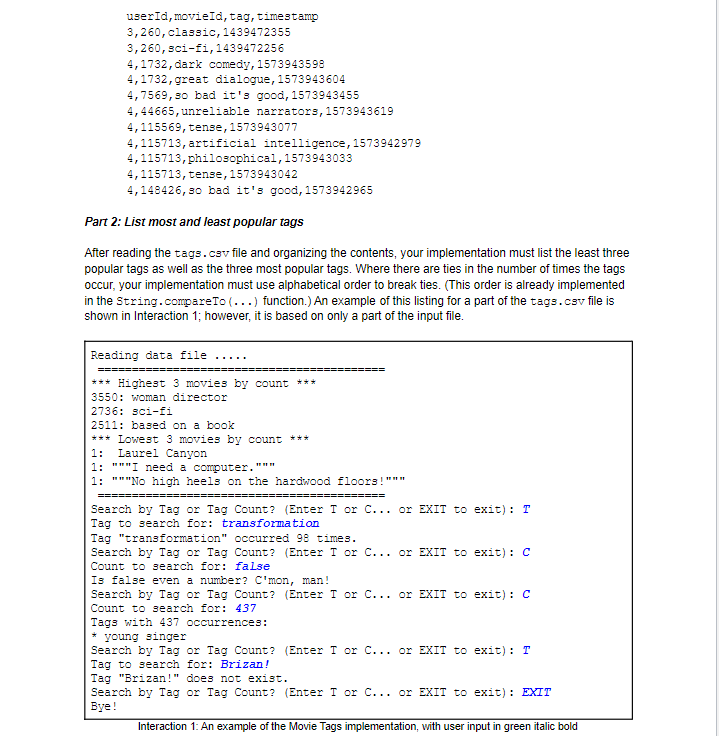


The goal of this assignment is to demonstrate your mastery of object oriented design, searching and sorting algorithms by handling a large dataset efficiently with respect to time and space. Background In this assignment, you will create a search for movie tags which entertainment consumers have placed in the MovieLens Dataset. For this, you will use the algorithms and data structures covered in class to this point. Your implementation will read data from a file of tags, allow the user to search for individual tags by popularity and display the results in a user-friendly manner. Functional Requirements Part 1: Read the data file The datafile for this assignment is the tags.csv file from the MovieLens 25M Dataset, which is available for download through Kaggle download or via The location of this file will be provided to your implementation on command line as the first and only argument to your implementation. Your implementation must read this file and may not assume this file is in any location other than the one provided. For example, if your implementation is MovieTags.java, it may be called with: java MovieTags/tmo/data_files/tags.csv The tags. csv file is a CSV file with the first row as a header. Your implementation should ignore the first (header) row and read all others in the file. Once the file has been read, the file must be closed and should not be re-read. The first few rows in the tags.csv file appear below. The fields are as follows: - userID: the ID of the user who assigned the tag in question - movieID: the ID of the movie being tagged - tag: The tag assigned - timestamp: the date/time when the tag was assigned in The file may be sorted by userID, movieID and tag but your implementation should not rely on that sorting unless you have verified it. Another file in the same dataset (movies.csv) can be used to determine the name of the movie being referenced but you do not need it for this assignment. The header row as well as the first few rows of data from the file appear below. userId, movieId, tag, timestamp 3,260, classic, 1439472355 3,260, sci-fi, 1439472256 4,1732 , dark comedy, 1573943598 4,1732 , great dialogue, 1573943604 4,7569, so bad it's good, 1573943455 4,44665 , unreliable narrators, 1573943619 4,115569 , tense, 1573943077 4,115713, artificial intelligence, 1573942979 4,115713, philosophical,1573943033 4,115713, tense, 1573943042 4,148426, so bad it's good, 1573942965 Part 2: List most and least popular tags After reading the tags. csv file and organizing the contents, your implementation must list the least three popular tags as well as the three most popular tags. Where there are ties in the number of times the tags occur, your implementation must use alphabetical order to break ties. (This order is already implemented in the String.compareTo (...) function.) An example of this listing for a part of the tags.csv file is shown in Interaction 1; however, it is based on only a part of the input file. Interaction 1: An example of the Movie Tags implementation, with user input in green italic bold Part 3: Find tags by count or tag counts by name or tags by counts Depending on the desire of the user, your implementation must find tags by count, find the count of a particular tag or exit: - Upon request from the user, your implementation must accept a number of tag counts from the user. All tags appearing a number of times equal to this count must be displayed. Of course, multiple tags could have equal counts. - Upon request from the user, your implementation must accept a tag. The number of times this tag appears must be displayed. An example of this interaction appears in Interaction 1; however, this interaction is based on only a part of the input file so you may find your counts differ from what is shown here. Part 4: Running time For each of the above three functional requirements (read the data file, list most and least popular tags, find tags by count and counts by name), you must provide details of: 1. Any data structures used 2. Details of the algorithm used 3. The big-O running time of the algorithm used and the justification for this running time If your implementation uses a modification of an exact implementation of an algorithm we discussed in class, you may omit the detail and simply name this algorithm along with its running time. If your implementation uses a modified version of a studied algorithm covered in class, you may assume this algorithm as a starting point and detail only your implementation's changes to this algorithm. These details must appear in the README.md or README.txt file accompanying your implementation. A (partial) example from README.md appears below. Read the data file - This algorithm uses tagEntry: an array of TagEntries, each of which is a pair of \{ String: tag, int: count \}. - For each line in the input data file, the implementation uses Linear Search on tagEntry to determine whether the tag exists. - If the tag exists, the count is incremented. - If the tag does not exist, it is added to the end of the tagEntry array with a count of 1. - Running time: O(n2) where n is the number of lines in the input file because each line of input requires a linear search on the array tagEntry, which may contain up to " n " entries. Example of contents in the README.md file (markdown formatting copied) Your implementation must be tolerant to invalid input from the user and must recover gracefully from invalid numbers, names, etc. Your implementation is required to use only the data structures (arrays) and algorithms (searching, sorting and recursion) we covered in class to this point. Your implementation must provide a full implementation of all algorithms - i.e. cannot call an external library - with the following exceptions permitted in your implementation: - Arraylist data structure may be used in place of arrays - Input and output classes (BufferedReader, FileReader, Scanner, etc.) Your implementation is expected to be efficient with respect to space and time. Specific attention will be paid to all functional requirements above: - The time to load the tags. csv file - The time required to search for a particular tag - The time required to search for a set of tags by count Your implementation is expected to exhibit good Object-Oriented Design, specifically: - The Java class(es) used in the implementation must represent a reasonable encapsulation of data and separation of concerns - The methods for each class must constitute a reasonable set of (reusable) functions Your implementation is expected to exhibit a consistent and readable style, specifically: - The functions, variables, etc. must display a reasonable and consistent naming convention - The indentation must be consistent - The comments for functions should follow a Javadoc style, and within functions, complex code should be consistently commented
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Advanced Database Systems
Authors: Carlo Zaniolo, Stefano Ceri, Christos Faloutsos, Richard T. Snodgrass, V.S. Subrahmanian, Roberto Zicari
1st Edition
155860443X, 978-1558604438