 Please help on it
Please help on it
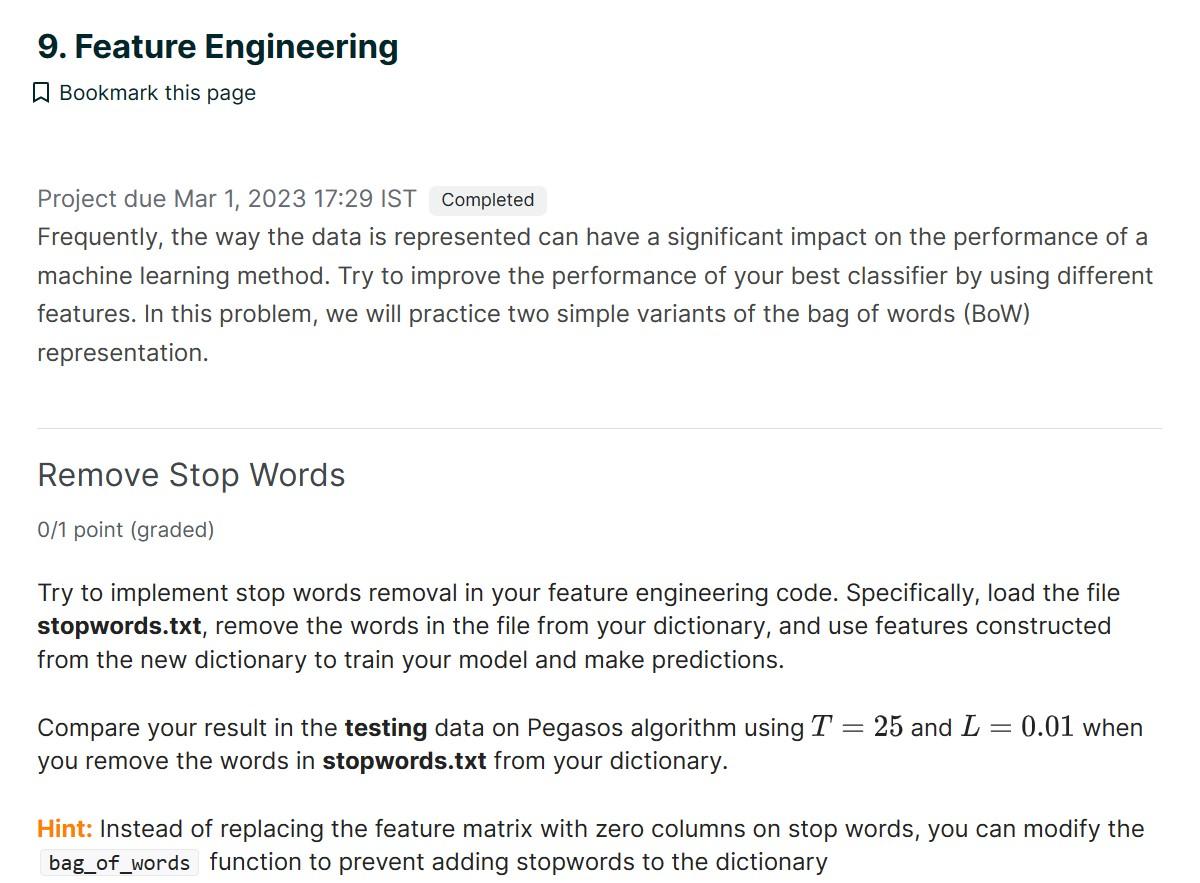
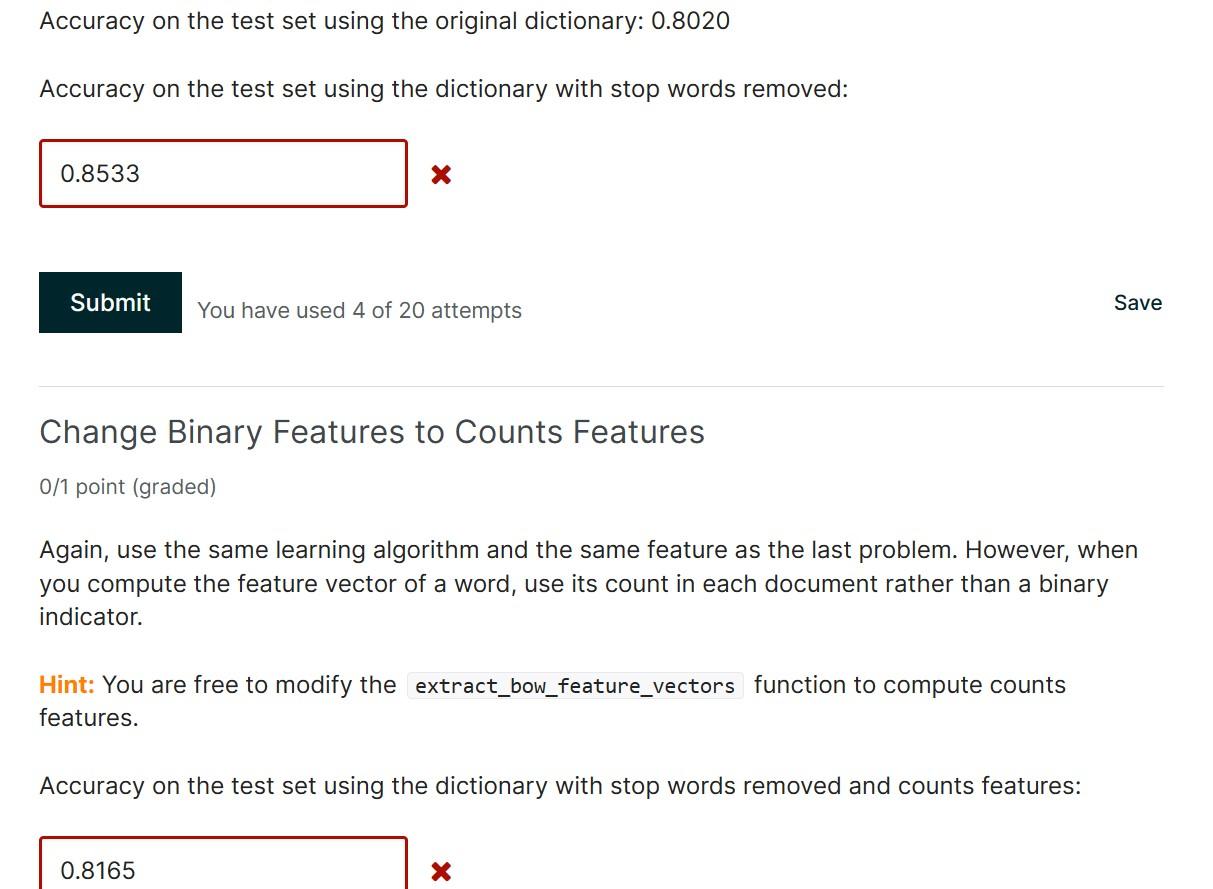
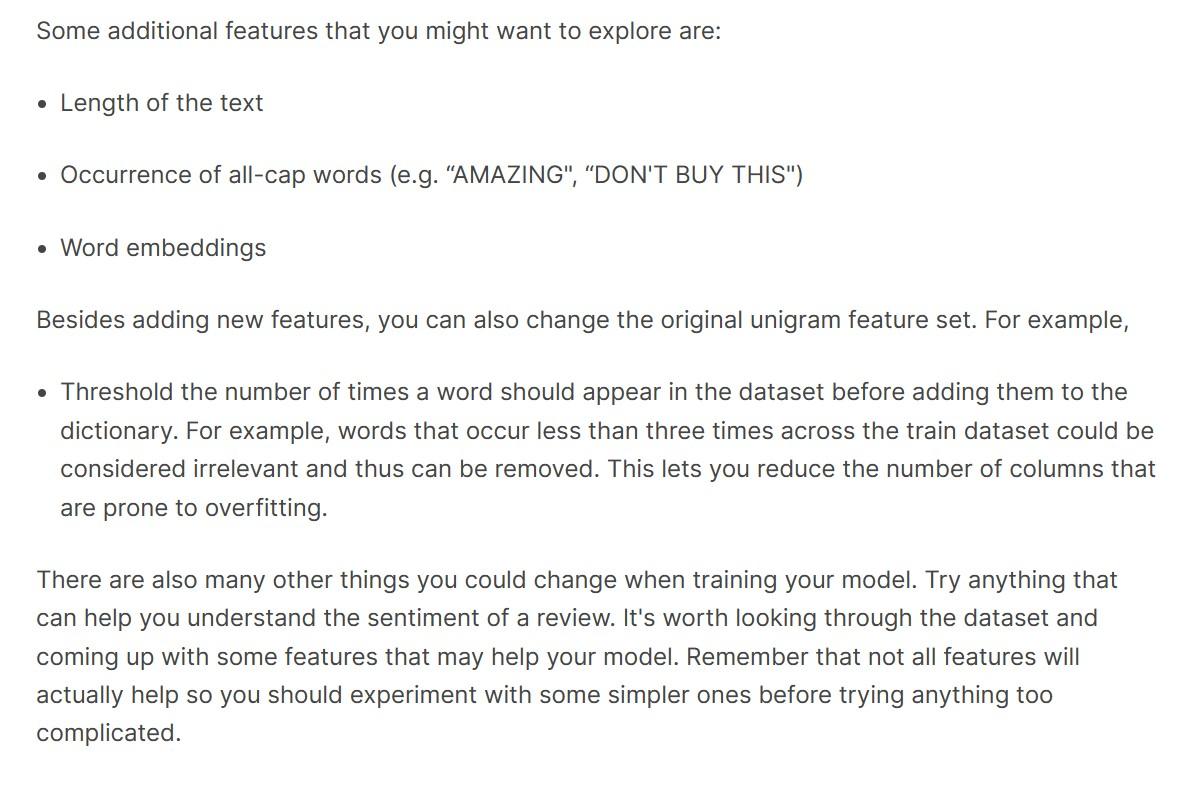
Project due Mar 1, 2023 17:29 IST Frequently, the way the data is represented can have a significant impact on the performance of a machine learning method. Try to improve the performance of your best classifier by using different features. In this problem, we will practice two simple variants of the bag of words (BoW) representation. Remove Stop Words 0/1 point (graded) Try to implement stop words removal in your feature engineering code. Specifically, load the file stopwords.txt, remove the words in the file from your dictionary, and use features constructed from the new dictionary to train your model and make predictions. Compare your result in the testing data on Pegasos algorithm using T=25 and L=0.01 when you remove the words in stopwords.txt from your dictionary. Hint: Instead of replacing the feature matrix with zero columns on stop words, you can modify the function to prevent adding stopwords to the dictionary Accuracy on the test set using the original dictionary: 0.8020 Accuracy on the test set using the dictionary with stop words removed: You have used 4 of 20 attempts Save Change Binary Features to Counts Features 0/1 point (graded) Again, use the same learning algorithm and the same feature as the last problem. However, when you compute the feature vector of a word, use its count in each document rather than a binary indicator. Hint: You are free to modify the function to compute counts features. Accuracy on the test set using the dictionary with stop words removed and counts features: Some additional features that you might want to explore are: - Length of the text - Occurrence of all-cap words (e.g. "AMAZING", "DON'T BUY THIS") - Word embeddings Besides adding new features, you can also change the original unigram feature set. For example, - Threshold the number of times a word should appear in the dataset before adding them to the dictionary. For example, words that occur less than three times across the train dataset could be considered irrelevant and thus can be removed. This lets you reduce the number of columns that are prone to overfitting. There are also many other things you could change when training your model. Try anything that can help you understand the sentiment of a review. It's worth looking through the dataset and coming up with some features that may help your model. Remember that not all features will actually help so you should experiment with some simpler ones before trying anything too complicated




