

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Please help with steps 1-3 thanks This assignment is based on the dataset 'Big Mart Sales'. The data scientists at Big Mart have collected 2013
Please help with steps 1-3 thanks 
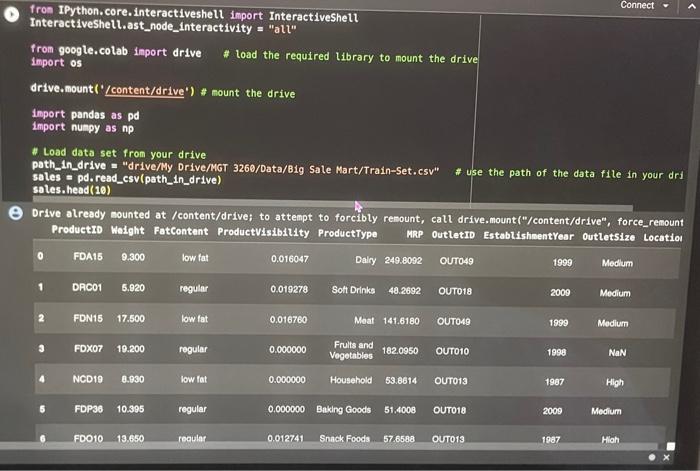
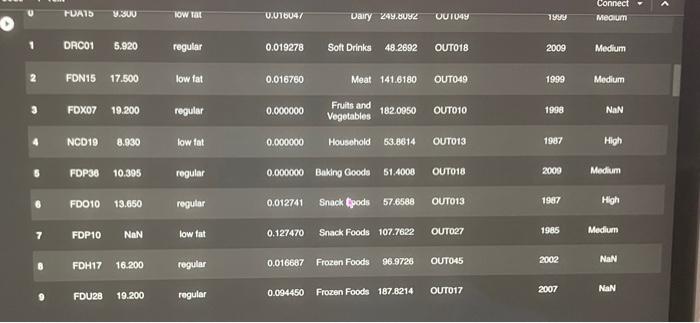

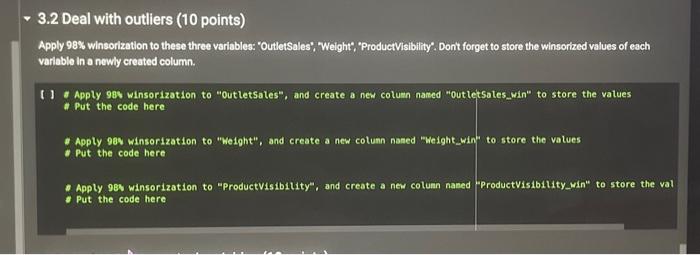
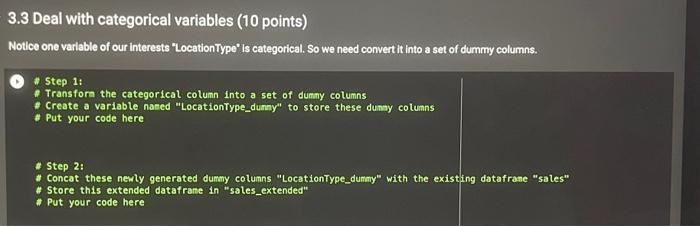
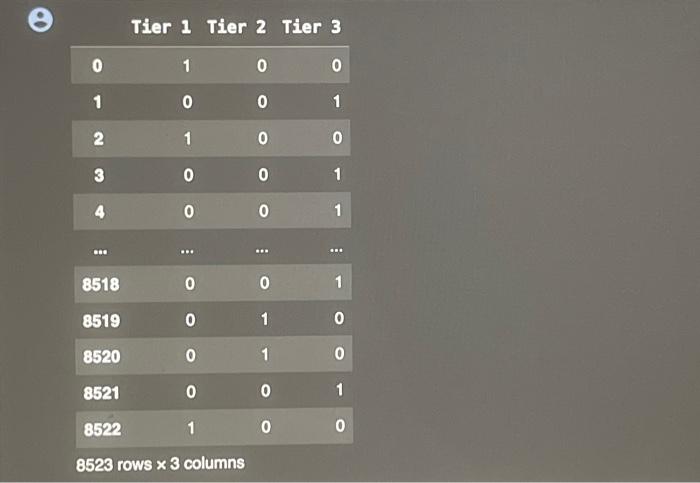
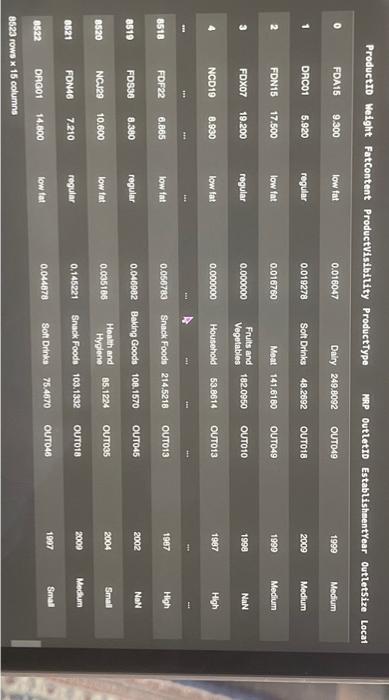
This assignment is based on the dataset 'Big Mart Sales'. The data scientists at Big Mart have collected 2013 sales data for 1559 products across 10 stores in different cliles. Also, certain attributes of each product and store have been defined. The aim is to build a predictive model and predict the sales of each product at a particular outlet. Using this model, Big Mart will try to understand the properties of products and outlets which play a key role in increasing sales. Please note that the data may have missing values as some stores might not report all the data due to technical glitches. Hence, it will be required to treat them accordingly. In this assignment, you will be required to perform an initial analyals and some preprocessing work in preparation for the predictive analysis that follows. You can use this assignment as a preparatory exercise for your final project. Below is the Variable Description: - ProductiD : unique product ID - Weight : weight of products - Fatcontent: specifies whether the product is low on fat or not - Visibility : percentage of total display area of all products in a store allocated to the particular product - ProductType : the category to which the product belongs - MRP : Maximum Retall Price (listed price) of the products - OutletiD : unique store ID - EstablishmentYear : year of establishment of the outlets - Outletsize : the size of the store in terms of ground area covered - LocationType : the type of cily in which the store is located - OutletType : specifies whether the outlet is just a grocery store or some sort of supermarket - OutletSales : (target variable) sales of the product in the particular store Connect fron IPython, core. interactiveshell import Interact Iveshell Interactiveshell,ast_node_interactivity = "all" from google.colab inport drive \# load the required library to mount the drive import os drive.mount( / /content/drive') inport pandas as pd import nunpy as np. * Load data set from your drive path_in_drive = "drive/My Drive/MGT 3260/Data/Big Sale Mart/Train-Set.csv" * use the path of the data file in your dri sales = pd, read_csv(path_in_drive) sales, head(10) Drive already nounted at/content/drive; to attempt to forcibly remount, call drive.mount/"/content/drive", force_remount Productio Walght Fatcontent ProductVisibility Productiype WRP OutletiD EstablishentYear OutletSize Locatioi 0 FDA15 9,300 low fat 0.016047 Daly 2490092 Ourro49 1999 Modum 1 DRCO1 5.020 reguler 0.019278 Sot Drinks 40.2692 OUT18 Moat 141.6180 outo4s 1999 Modium 2 FDN15 17.500 low fat 0.016760 regular 0.000000 Frults and 182.0950 ouroto 1998 NaN 4 NCD19 a.9so low tat 0.000000 Household 53.6614 1907 High 6 FDP36 10.395 regular 0.000000 Baking Goods 51,4000 2009 Medum 6 F0010 13.650 reqular 0.012741 Snnck Foods 57.6508 ouro13 1007 Hoh \begin{tabular}{|c|c|c|c|c|c|c|c|c|c|} \hline 0 & rUAIS & y.evo & lowrat & o.u16047 & Dairy & 249.00y2 & uuives & & Meoum \\ \hline 1 & DRC01 & 5.920 & regular & 0.019278 & Sott Drinks & 48.2692 & ouro18 & 2009 & Modum \\ \hline 2 & FON15 & 17.500 & low fat & 0.016760 & Meat & 141.6180 & OUT049 & 1999 & Modlum \\ \hline 3 & FoX07 & 19.200 & regular & 0.000000 & \begin{tabular}{l} Frits and \\ Vogetables \end{tabular} & 182.0050 & o10 & 1998 & NaN \\ \hline 4 & NCD19 & 8.930 & low tat & 0.000000 & Housohold & 53.8014 & OuTo13 & 1987 & Hilph \\ \hline 8 & FDP39 & 10.395 & regular & 0.000000 & Bakling Cooda & 51.4000 & OU18 & 2000 & Modium \\ \hline 8 & FDO10 & 13.650 & regular & 0.012741 & Snack troods & 57.6588 & OUT13 & 1997 & Hgh \\ \hline 7 & FDP10 & NaN & low fat & 0.127470 & Snack Foods & 107.7622 & OUT & 1995 & Modum \\ \hline 8 & FOH17 & 16.200 & regular & 0.016607 & Frozen Foods & 969728 & 45 & 2002 & NaN \\ \hline 0 & FDU28 & 19.200 & regular & 0.094450 & Frozen Foods & 187.8214 & OU17 & 2007 & MaN \\ \hline \end{tabular} 3.1 Deal with Nan values (missing values) (10 points) From the output from Step 1, we can tell there are several missing values in the column of 'Welght: Choose a proper value to fill these missing values I 1. Fill the missing values with a proper value and store the output column in a niew column nased "Neight_filted" - Put the code here 3.2 Deal with outliers ( 10 points) Apply 98% Whinsorization to these three variables: 'OutletSales", "Weight:, "ProductVisibility". Dont forget to store the winsorized values of each variablo in a newly created column. I * Apply 98v winsorization to "Outletsales", and create a new column named "outletsales_win" to store the values * Put the code here. - Apply 98s winsorization to "Weight", and create a new colunn naned "Weight_win" to store the values - Put the code here - Apply 98w winsorization to "Productvisibility", and create a new colunn naned "Productvisibility_win" to store the val Put the code here 3.3 Deal with categorical variables ( 10 points) Notice one variable of our interests 'LocationType' is categorical. So we need convert it into a set of dummy columns. * Step 1: - Transfora the categorical column into a set of dumny columns - Create a variable naned "LocationType_dunny" to store these dunay columns * Put your code here - Step 2: * Concat these newly generated dumy columns "LocationType_dummy" with the existing datafrane "sales" "Store this extended datafrane in "sales_extended" - Put your code here Q Tier 1 Tier 2 Tier 3 \begin{tabular}{cccc} \hline 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 1 \\ 2 & 1 & 0 & 0 \\ 3 & 0 & 0 & 1 \\ 4 & 0 & 0 & 1 \\ . & & & \\ 8518 & 0 & 0 & 1 \\ 8519 & 0 & 1 & 0 \\ 8520 & 0 & 1 & 0 \\ 8521 & 0 & 0 & 1 \\ 8522 & 1 & 0 & 0 \\ \hline \end{tabular} 8523 rows 3 columns This assignment is based on the dataset 'Big Mart Sales'. The data scientists at Big Mart have collected 2013 sales data for 1559 products across 10 stores in different cliles. Also, certain attributes of each product and store have been defined. The aim is to build a predictive model and predict the sales of each product at a particular outlet. Using this model, Big Mart will try to understand the properties of products and outlets which play a key role in increasing sales. Please note that the data may have missing values as some stores might not report all the data due to technical glitches. Hence, it will be required to treat them accordingly. In this assignment, you will be required to perform an initial analyals and some preprocessing work in preparation for the predictive analysis that follows. You can use this assignment as a preparatory exercise for your final project. Below is the Variable Description: - ProductiD : unique product ID - Weight : weight of products - Fatcontent: specifies whether the product is low on fat or not - Visibility : percentage of total display area of all products in a store allocated to the particular product - ProductType : the category to which the product belongs - MRP : Maximum Retall Price (listed price) of the products - OutletiD : unique store ID - EstablishmentYear : year of establishment of the outlets - Outletsize : the size of the store in terms of ground area covered - LocationType : the type of cily in which the store is located - OutletType : specifies whether the outlet is just a grocery store or some sort of supermarket - OutletSales : (target variable) sales of the product in the particular store Connect fron IPython, core. interactiveshell import Interact Iveshell Interactiveshell,ast_node_interactivity = "all" from google.colab inport drive \# load the required library to mount the drive import os drive.mount( / /content/drive') inport pandas as pd import nunpy as np. * Load data set from your drive path_in_drive = "drive/My Drive/MGT 3260/Data/Big Sale Mart/Train-Set.csv" * use the path of the data file in your dri sales = pd, read_csv(path_in_drive) sales, head(10) Drive already nounted at/content/drive; to attempt to forcibly remount, call drive.mount/"/content/drive", force_remount Productio Walght Fatcontent ProductVisibility Productiype WRP OutletiD EstablishentYear OutletSize Locatioi 0 FDA15 9,300 low fat 0.016047 Daly 2490092 Ourro49 1999 Modum 1 DRCO1 5.020 reguler 0.019278 Sot Drinks 40.2692 OUT18 Moat 141.6180 outo4s 1999 Modium 2 FDN15 17.500 low fat 0.016760 regular 0.000000 Frults and 182.0950 ouroto 1998 NaN 4 NCD19 a.9so low tat 0.000000 Household 53.6614 1907 High 6 FDP36 10.395 regular 0.000000 Baking Goods 51,4000 2009 Medum 6 F0010 13.650 reqular 0.012741 Snnck Foods 57.6508 ouro13 1007 Hoh \begin{tabular}{|c|c|c|c|c|c|c|c|c|c|} \hline 0 & rUAIS & y.evo & lowrat & o.u16047 & Dairy & 249.00y2 & uuives & & Meoum \\ \hline 1 & DRC01 & 5.920 & regular & 0.019278 & Sott Drinks & 48.2692 & ouro18 & 2009 & Modum \\ \hline 2 & FON15 & 17.500 & low fat & 0.016760 & Meat & 141.6180 & OUT049 & 1999 & Modlum \\ \hline 3 & FoX07 & 19.200 & regular & 0.000000 & \begin{tabular}{l} Frits and \\ Vogetables \end{tabular} & 182.0050 & o10 & 1998 & NaN \\ \hline 4 & NCD19 & 8.930 & low tat & 0.000000 & Housohold & 53.8014 & OuTo13 & 1987 & Hilph \\ \hline 8 & FDP39 & 10.395 & regular & 0.000000 & Bakling Cooda & 51.4000 & OU18 & 2000 & Modium \\ \hline 8 & FDO10 & 13.650 & regular & 0.012741 & Snack troods & 57.6588 & OUT13 & 1997 & Hgh \\ \hline 7 & FDP10 & NaN & low fat & 0.127470 & Snack Foods & 107.7622 & OUT & 1995 & Modum \\ \hline 8 & FOH17 & 16.200 & regular & 0.016607 & Frozen Foods & 969728 & 45 & 2002 & NaN \\ \hline 0 & FDU28 & 19.200 & regular & 0.094450 & Frozen Foods & 187.8214 & OU17 & 2007 & MaN \\ \hline \end{tabular} 3.1 Deal with Nan values (missing values) (10 points) From the output from Step 1, we can tell there are several missing values in the column of 'Welght: Choose a proper value to fill these missing values I 1. Fill the missing values with a proper value and store the output column in a niew column nased "Neight_filted" - Put the code here 3.2 Deal with outliers ( 10 points) Apply 98% Whinsorization to these three variables: 'OutletSales", "Weight:, "ProductVisibility". Dont forget to store the winsorized values of each variablo in a newly created column. I * Apply 98v winsorization to "Outletsales", and create a new column named "outletsales_win" to store the values * Put the code here. - Apply 98s winsorization to "Weight", and create a new colunn naned "Weight_win" to store the values - Put the code here - Apply 98w winsorization to "Productvisibility", and create a new colunn naned "Productvisibility_win" to store the val Put the code here 3.3 Deal with categorical variables ( 10 points) Notice one variable of our interests 'LocationType' is categorical. So we need convert it into a set of dummy columns. * Step 1: - Transfora the categorical column into a set of dumny columns - Create a variable naned "LocationType_dunny" to store these dunay columns * Put your code here - Step 2: * Concat these newly generated dumy columns "LocationType_dummy" with the existing datafrane "sales" "Store this extended datafrane in "sales_extended" - Put your code here Q Tier 1 Tier 2 Tier 3 \begin{tabular}{cccc} \hline 0 & 1 & 0 & 0 \\ 1 & 0 & 0 & 1 \\ 2 & 1 & 0 & 0 \\ 3 & 0 & 0 & 1 \\ 4 & 0 & 0 & 1 \\ . & & & \\ 8518 & 0 & 0 & 1 \\ 8519 & 0 & 1 & 0 \\ 8520 & 0 & 1 & 0 \\ 8521 & 0 & 0 & 1 \\ 8522 & 1 & 0 & 0 \\ \hline \end{tabular} 8523 rows 3 columns Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Financial Accounting An Integrated Approach
Authors: Michael Gibbins
6th Edition
0176407251, 978-0176407254