Please provide full code. It needs to have this end output. The expected result value for the given dataset is: [[13.346550530668159, 3.236599802533008], [7.9971108077796735, 4.473417525043109]]
The full question is below. With the type of packages that can be used, the code that I was used that was incorrect, along with the test cell to check everything.


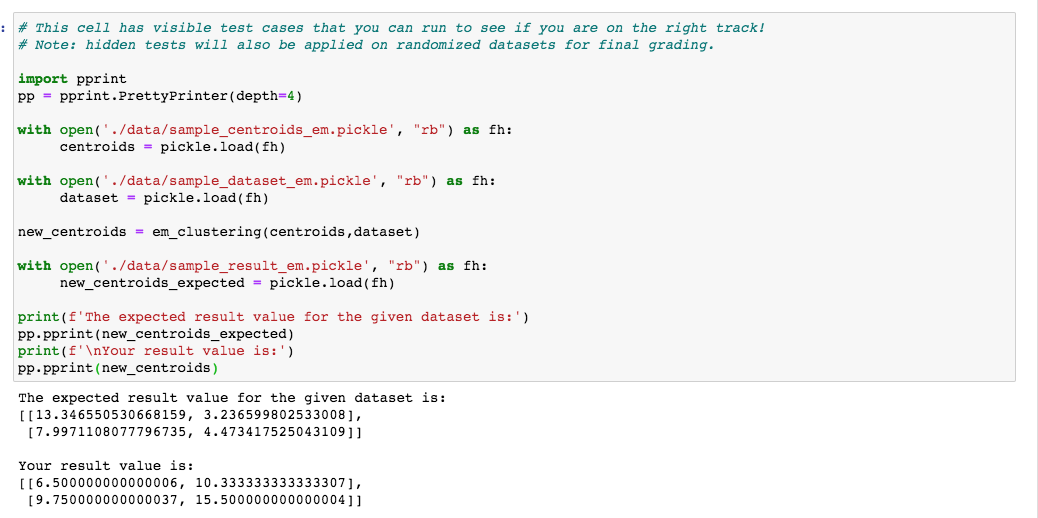
Remember that you are encouraged to discuss the problems with your instructors and classmates, but you must write all code and solutions on your own. The rules to be followed for the assignment are: - Do NOT load additional packages beyond what we've shared in the cells below. - Some problems with code may be autograded. If we provide a function or class API do not change it. - Do not change the location of the data or data directory. Use only relative paths to access the data. [10 points] Problem 2 - Clustering using EM Method A sample dataset has been provided to you in the './data/sample_dataset_em.pickle' path. The centroids are in './data/sample_centroids_em.pickle' and the sample result is in './data/sample_result_em.pickle' path. You can use these to test your code. Here are the attributes for the dataset. Use this dataset to test your functions. - Dataset should load the points in the form of a list of lists where each list item represents a point in the space. - An example dataset will have the following structure. If there are 3 points in the dataset, this would appear as follows in the list of lists. dataset=[5,7,9] Note: - A sample dataset to test your code has been provided in the location "data/em_dataset.pickle". Please maintain this as it would be necessary while grading. - Do not change the variable names of the returned values. - After calculating each of those values, assign them to the corresponding value that is being returned. import numpy as np import pickle def em_clustering(centroids, dataset, max _iterations =100, tolerance =1e4 ): centroids = np.array (centroids) dataset = np.array ( dataset ) num_clusters, num_features = centroids.shape num_points = len (dataset) responsibilities = np.zeros ((num_points, num_clusters ) ) for iteration in range(max_iterations): \# E-step: Calculate responsibilities for i in range(num_points): for j in range(num_clusters): responsibilities [i,j]=npexp(nplinalgnorm(dataset[i]centroids[j])2) \# Normalize responsibilities responsibilities /= np.sum(responsibilities, axis=1, keepdims=True) \# M-step: Update centroids new_centroids =npdot( responsibilities.T, dataset) / np.sum(responsibilities, axis=0, keepdims=True).T \# Check for convergence using a simple approach if np.max(np.abs(new_centroids - centroids)) = new_centroids return new_centroids.tolist() \# Test code with open('./data/sample_centroids_em.pickle', "rb") as fh: centroids = pickle.load (fh) with open('./data/sample_dataset_em.pickle', "rb") as fh: dataset = pickle.load (fh) \# Initialize centroids using the first k data points initial_centroids = dataset [: 1 en(centroids) ] \# Apply EM clustering new_centroids = em_clustering (initial_centroids, dataset) with open('./data/sample_result_em.pickle', "rb") as fh: new_centroids_expected = pickle.load (fh) print(f'The expected result value for the given dataset is:') pp.pprint(new_centroids_expected) print (f' Your result value is:') \# This cell has visible test cases that you can run to see if you are on the right track! \# Note: hidden tests will also be applied on randomized datasets for final grading. import pprint pp= pprint.PrettyPrinter (depth=4) with open('./data/sample_centroids_em.pickle', "rb") as fh: centroids = pickle. load(fh) with open('./data/sample_dataset_em.pickle', "rb") as fh: dataset = pickle.load (fh) new_centroids = em_clustering (centroids, dataset) with open('./data/sample_result_em.pickle', "rb") as fh: new_centroids_expected = pickle.load (fh) print(f'The expected result value for the given dataset is:') pp.pprint(new_centroids_expected) print (f' Your result value is:') pp.pprint(new_centroids) The expected result value for the given dataset is: [ [13.346550530668159,3.236599802533008], [7.9971108077796735,4.473417525043109]] Your result value is: [ [6.500000000000006, 10.333333333333307], [9.750000000000037,15.500000000000004]]




