Python only


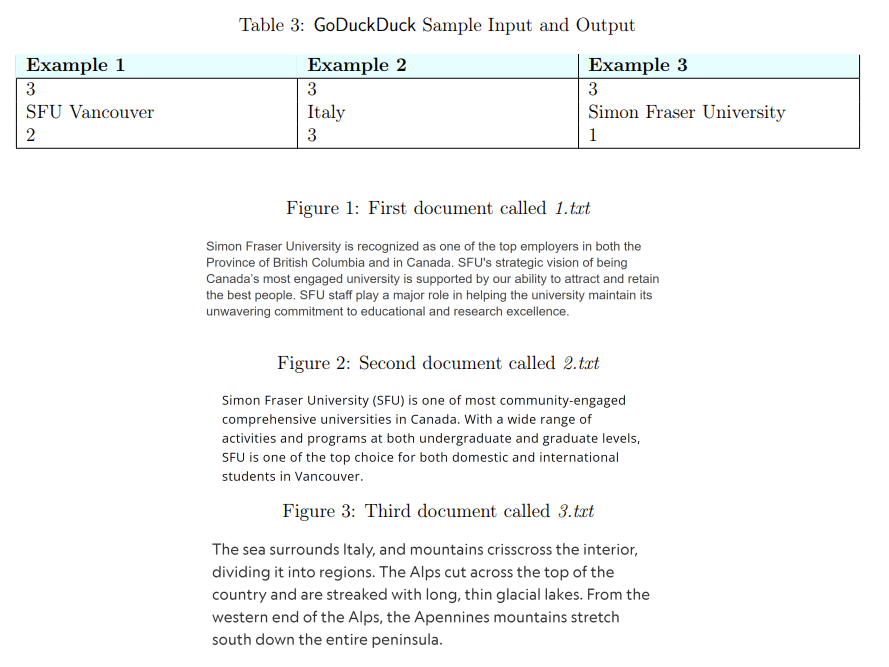
Search engines have a central role in information retrieval from the web. More than 90% of online experiences begin with a search engine. Search engines have a very complicated architecture but it has three major components: crawling, indexing and ranking. Crawling is about exploring the web to find new pages and indexing the process of storing information in a way for faster information retrieval. In this assignment, your focus will be on the search engine ranking component. The estimated number of web pages indexed in Google is about 50 billion. Returning pages most relevant to a query is one of the most important measures to evaluate a search engine's performance. And this is all about the ranking algorithm that a search engine uses. Two important sources that search engines use in their ranking algorithms include the content of web pages and links between them. In this part of the assignment, you will develop a content-based search engine called, GoDuckDuck. Given a query, GoDuckDuck task is to explore a set of text files, and employ a ranking algorithm to return the most relevant file with regard to the given query considering the files' content. To implement GoDuckDuck first, we need to define the ranking algorithm we use. For a given query, the ranking algorithm computes a relevance score for each document; a greater relevance score ranks a document higher. The main input of the ranking algorithm is the frequency of query words in different documents: frequency ( word, document )= number of occurrences ofword in document And the score of a document with respect to a query is computed as follows: score(query,document)=wordinqueryfrequency(word,document) meaning that the score is the total sum of the frequency of each word in the document. The documents are ranked based on their scores. Imagine your document content is: "they ran into many problems in the last year. They are trying to solve them.". And the user query is "they went". First, we parse the query to get the single words in the query including "they" and "went". The frequency of these words are frequency ( they, document )=2 frequency ( went, document )=0 and consequently the score of this document is equal to 2. GoDuckDuck works as follows: - First, GoDuckDuck receives the total number of documents n (greater than 0) that it does the search over. GoDuckDuck assumes there are n text files in the same directory as your program with the names 1.txt, 2.txt, , n.txt. Each file contains words separated by space. - Next, GoDuckDuck receives a query from the user in a new line. This is a string containing words separated by space. Then, GoDuckDuck does the processing and computes the score of each document with respect to the given query using the ranking algorithm described above. - Finally, GoDuckDuck prints out the name of the file with the maximum score, which is a number between 1 and n, in a new line. For example, if "5.txt" has the highest score, your program simply prints out 5. If there are two or more documents having the same largest score, your program should print the document with the smaller name. For example, if files '4.txt' and '7.txt" gains the same score as the highest score, GoDuckDuck prints 4 (as a smaller file name) in the output. - In counting words, GoDuckDuck only considers the exact ones. Meaning that the program in the counting process ignores the derivatives of a given word, or if the word is surrounded by characters such as comma, quote, hyphen, parenthesis and apostrophe. Moreover, GoDuckDuck is case-sensitive, meaning that it differentiates between lowercase and uppercase letters. Three examples in Table 3 are related to the result of GoDuckDuck on the corpus of three files shown in Figures 1, 2 and 3. In all three examples, the first line is equal to three which shows the number of text files GoDuckDuck should process. The second line shows the submitted query and the third line is the name of the file with the highest score relevant to the given query. In example 1 , the query contains two words "SFU" and "Vancouver". Only the word "SFU" occurred one time in "1.txt" resulting in score of 1 for this document. Each of the words "SFU" and "Vancouver" occurred in the file "2.txt" one time. This means the score of this file is 2. And "3.txt" does not contain these words and this assigns a score of 0 to this file. Accordingly "2.txt" gains the highest score and GoDuckDuck prints 2 in the output. Note that GoDuckDuck ignored "SFU's" and "(SFU)" in counting the number of "SFU". In example 2 the query consists of only one word "Italy" and only "3.txt" includes this word. So, GoDuckDuck prints 3 as result. For example 3, the query includes three words each has appeared only once in "1.txt" and "2.txt" This means these two files get the same score and GoDuckDuck prints 1 as the name of the file which has a smaller value. You can use the modules introduced during the semester to solve the problem. Your program input and output format should be exactly the same as the format of the examples shown in Table 3 . Table 3: GoDuckDuck Sample Input and Output Figure 1: First document called 1.txt Simon Fraser University is recognized as one of the top employers in both the Province of British Columbia and in Canada. SFU's strategic vision of being Canada's most engaged university is supported by our ability to attract and retain the best people. SFU staff play a major role in helping the university maintain its unwavering commitment to educational and research excellence. Figure 2: Second document called 2.txt Simon Fraser University (SFU) is one of most community-engaged comprehensive universities in Canada. With a wide range of activities and programs at both undergraduate and graduate levels, SFU is one of the top choice for both domestic and international students in Vancouver. Figure 3: Third document called 3.txt The sea surrounds Italy, and mountains crisscross the interior, dividing it into regions. The Alps cut across the top of the country and are streaked with long, thin glacial lakes. From the western end of the Alps, the Apennines mountains stretch south down the entire peninsula




