

Question
Suppose that an online bookseller has collected ratings information from 20 past users (U1- U20) on a selection of recent books. The ratings range from
Suppose that an online bookseller has collected ratings information from 20 past users (U1- U20) on a selection of recent books. The ratings range from 1 = worst to 5 = best. Two new users (NU1 and NU2) have recently visited the site and rated some of the books ("?" represents missing ratings). The two new users' ratings given in the last two rows.
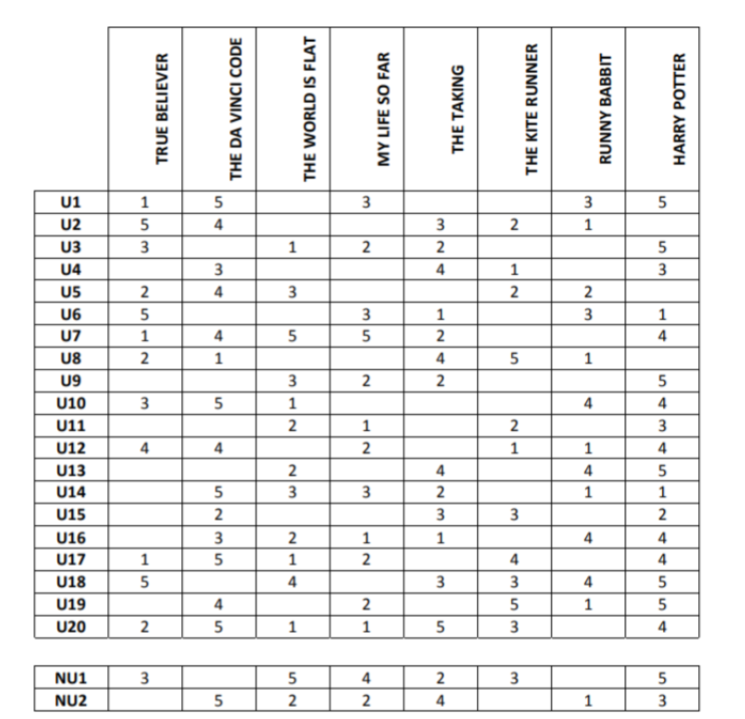
Using the K-Nearest Neighbor algorithm predict the ratings of these new users for each of the books they have not yet rated. Use the Pearson correlation coefficient as the similarity measure. a. First compute the correlations between the new users (NU1 and NU2) and all other users. Then for each new user compute the predicted rating for each of the unrated items using K=3 (i.e., 3 nearest neighbors). Use the weighted average function to compute the predictions based on ratings of the nearest neighbors. Be sure to show the intermediate steps in your work (or provide a short explanation of how you computed the predictions). b. Measure the Mean Absolute Error (MAE) on the predictions using NU1 and NU2 as test users. You can compute MAE by generating predictions for items already rated by the test user (e.g., for NU1 these are all items except "The DaVinci Code" and "Runny Babbit"). Then, for each of these items you can compute the absolute value of the difference between the predicted and the actual ratings. Finally, you can average these errors across all 12 compared items (for both NU1 and NU2) to obtain the MAE. c. Item-Based Collaborative Filtering. Using the same data as above and the item-based collaborative filtering algorithm (instead of user-based CF used in the previous parts), compute the predicted rating of NU1 on the book "The DaVinci Code". Note that in this case, you will need to find the K most similar items (books) to the target item based on their rating vectors (columns in the table), and then use NU1's ratings on the K neighbor items. For this problem use K = 2, and use Cosine Similarity to identify the most similar neighbors to "The DaVinci Code". In order to compute Cosine similarities, you may assume that missing values in the ratings table are considered to be zeros.
\begin{tabular}{|l|l|l|l|l|l|l|l|l|} \hline NU1 & 3 & & 5 & 4 & 2 & 3 & & 5 \\ \hline NU2 & & 5 & 2 & 2 & 4 & & 1 & 3 \\ \hline \end{tabular}Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Mastering PostgreSQL 12 Advanced Techniques To Build And Administer Scalable And Reliable PostgreSQL Database Applications
Authors: Hans-Jurgen Schonig
3rd Edition
1838988823, 978-1838988821