

Question
Text Mining Python Code Question is in attached screenshot. Please help to see. Link attached again - Python Relevant Files accessible via this link, please
Text Mining
Python Code Question is in attached screenshot. Please help to see.
Link attached again - Python Relevant Files accessible via this link, please check :
https://drive.google.com/drive/folders/1KFsTbZnOlmjimRdSXfh_lKtJYMIvxw-2?usp=sharing
QUESTION
In this assignment, we practice document similarity. First, we are going to scrapephilosophers' biographies from their Wikipedia page and construct a corpus of documents. Then, we'll match every philosopher to its most similar one based on their Wikipedia biographies.
We will useWikipedia's List of ancient Greekphilosopherspage (you can find ithere).First,we'll scrape the names of the authors and get their filepaths (Question 1). Then, wewill create function to get the content from an article with onlyits file path (Question 2). Finally, we'll build the LSI model to find the most similar other philosopher for each of the authors in our database(Question 3).
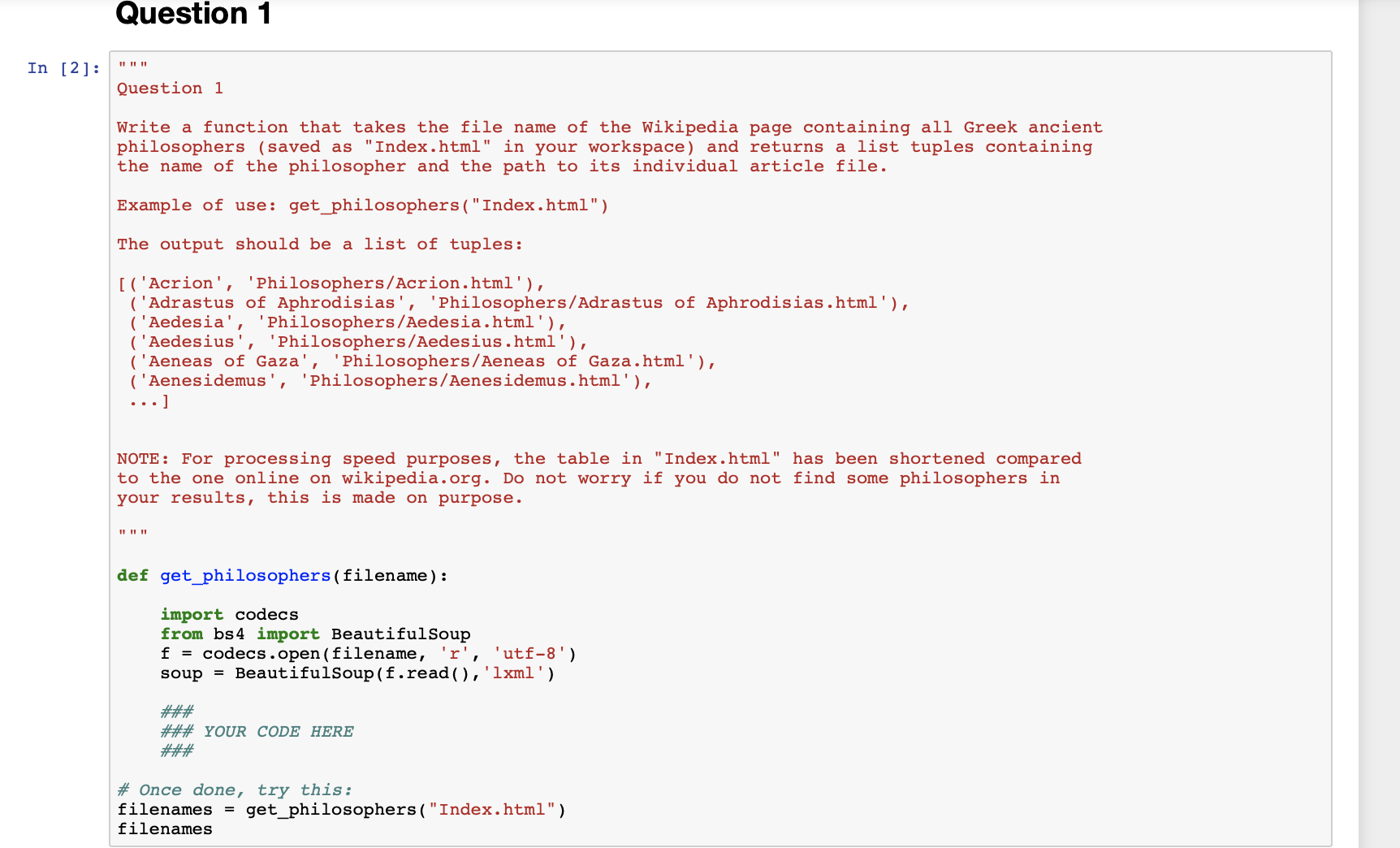
Question 1
Write function that takes the file name of the Wikipedia page containing the list of all Greek ancientphilosophers and returns a list of tuples containingthe name of the philosopher and the path to its individual article file.
To avoid scraping directly from Wikipedia, we downloaded a page (Index.html) and put it in your starting code. This file contains the HTML code of the page of the list ofancient Greek philosophers(that you can findhere).
Your function should beget_philosophers(filename)where 'filename'is thefilecontaining the HTMLof a page of a list of philosophers, 'Index.html' in our case. The function should return a list of tuples containing the name of the philosopher and its associated filepath. Note that all philosophers articles are in the 'Philosophers' folder, hence the path should contain 'Philosophers', '/', 'author_name' and '.html'.
The output should look like that:
[('Acrion', 'Philosophers/Acrion.html'), ('Adrastus of Aphrodisias', 'Philosophers/Adrastus of Aphrodisias.html'), ('Aedesia', 'Philosophers/Aedesia.html'), ('Aedesius', 'Philosophers/Aedesius.html'), ('Aeneas of Gaza', 'Philosophers/Aeneas of Gaza.html'), ('Aenesidemus', 'Philosophers/Aenesidemus.html'), ...]Some additional advice:
One of the problems with Wikipedia is that page structure is not always consistent, and some cells in the table might be empty. There are many tags to look for in the actual table, but probably looking for the first occurrence of 'tr' is the safest option.
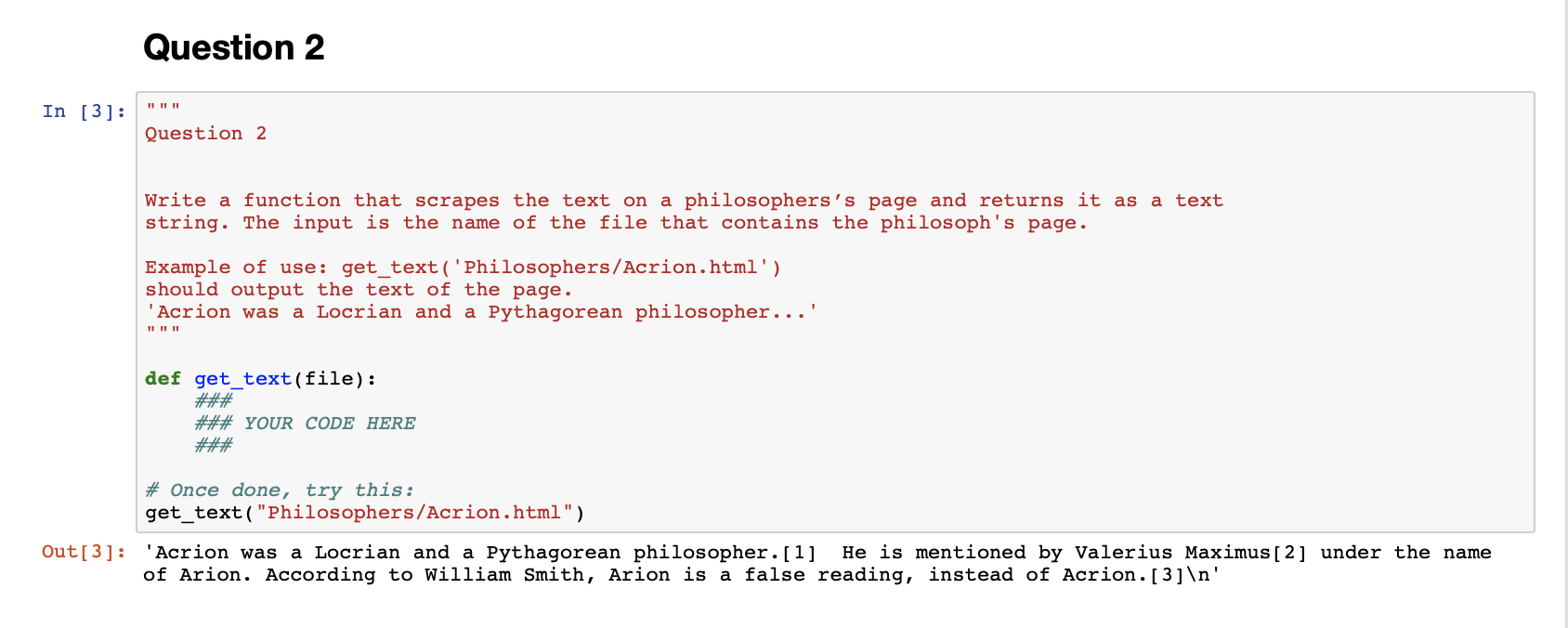
Question 2
Write a function that scrapes the text on a philosophers's pageand returns it as a text string.
As before, we saved a page in a file so that you don't have to scrape on Wikipedia, seePhilosophers/Acrion.html. Your function should be calledget_text(file).It takes thefilepath of the saved HTML file as an input and returns a string. Scrape all the text that is inside atag. Assuming that page_soup contains the entire bs4 object for the page, the following code should get you all the relevant text on the page:all_text = ""for tag in page_soup.find_all('p'): all_text += tag.get_text()
We downloaded all of thephilosophers' pages from the list, and extracted and saved their text. They are in the 'Philosophers' folder.
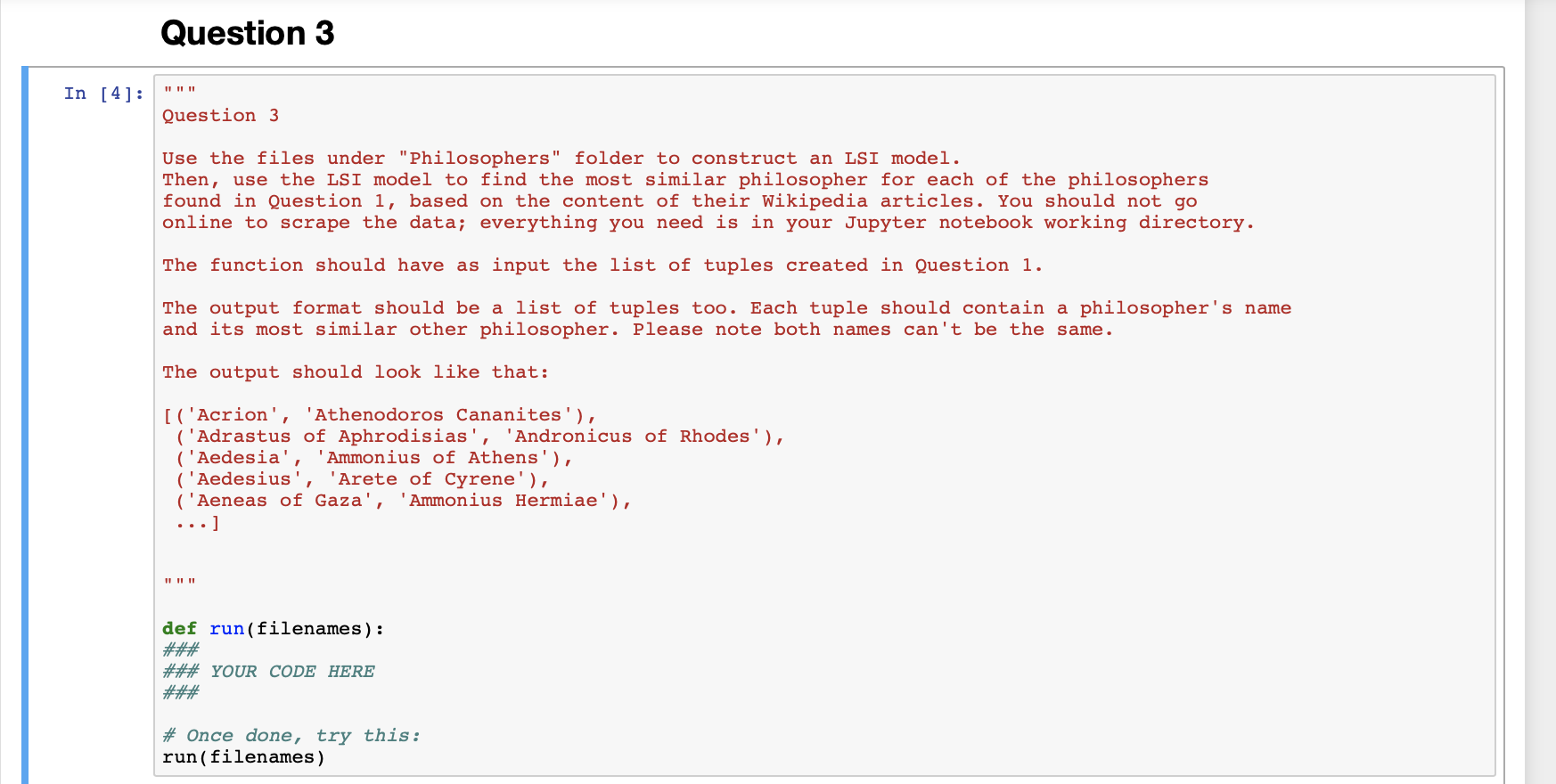
Question 3
Use the files under "Philosophers" folder to construct an LSI model.Then, use the LSI model to find the most similar philosopher for each of the philosophersfound in Question 1, based on the content of their Wikipedia articles. YouMUSTNOT goonline to scrape the data; everything you need is in your Jupyter notebook working directory.
The function should have as input the list of tuples created in Question 1.
The output format should be a list of tuples too. Each tuple should contain a philosopher's name and its most similar other philosopher. Please note both names can't be the same.
The output should look like that:
[('Acrion', 'Athenodoros Cananites'), ('Adrastus of Aphrodisias', 'Andronicus of Rhodes'), ('Aedesia', 'Ammonius of Athens'), ('Aedesius', 'Arete of Cyrene'), ('Aeneas of Gaza', 'Ammonius Hermiae'), ...]The name of the author must be the 'title' tag found in the 'Index.html'. Be careful, if itis not the case, the grader will not detect your answer and you'll get no points.
NOTE_1:For processing speed purposes, the table in "Index.html" has been shortened comparedto the one online on wikipedia.org. Do not worry if you do not find some philosophers inyour results, this is made on purpose.
There are some instructions you need to follow:
You only need to write code in the comment area "Your Code Here".
Do not upload your own file. Please make the necessary changes in the Jupyter notebook file already present in the server.
Please note, there are several cells in the Assignment Jupyter notebook that are empty and read only. Do not attempt to remove them or edit them. They are used in grading your notebook. Doing so might lead to 0 points.
PYTHON FILE - See in google drive link:
"""
Question 1
Write function that takes the file name of the Wikipedia page containing all Greek ancient
philosophers (saved as "Index.html" in your workspace) and returns a list tuples containing
the name of the philosopher and the path to its individual article file.
Example of use: get_philosophers("Index.html")
The output should be a list of tuples:
[('Acrion', 'Philosophers/Acrion.html'),
('Adrastus of Aphrodisias', 'Philosophers/Adrastus of Aphrodisias.html'),
('Aedesia', 'Philosophers/Aedesia.html'),
('Aedesius', 'Philosophers/Aedesius.html'),
('Aeneas of Gaza', 'Philosophers/Aeneas of Gaza.html'),
('Aenesidemus', 'Philosophers/Aenesidemus.html'),
...]
NOTE: For processing speed purposes, the table in "Index.html" has been shortened compared
to the one online on wikipedia.org. Do not worry if you do not find some philosophers in
your results, this is made on purpose.
"""
def get_philosophers(filename):
import codecs
from bs4 import BeautifulSoup
f = codecs.open(filename, 'r', 'utf-8')
soup = BeautifulSoup(f.read(),'lxml')
###
### YOUR CODE HERE
###
# Once done, try this:
filenames = get_philosophers("Index.html")
filenames
"""
Question 2
Write function that scrapes the text on a philosophers's page and returns it as a text
string. The input is the name of the file that contains the philosoph's page.
Example of use: get_text('Philosophers/Acrion.html')
should output the text of the page.
'Acrion was a Locrian and a Pythagorean philosopher...'
"""
def get_text(file):
###
### YOUR CODE HERE
###
# Once done, try this:
get_text("Philosophers/Acrion.html")
"""
Question 3
Use the files under "Philosophers" folder to construct an LSI model.
Then, use the LSI model to find the most similar philosopher for each of the philosophers
found in Question 1, based on the content of their Wikipedia articles. You should not go
online to scrape the data; everything you need is in your Jupyter notebook working directory.
The function should have as input the list of tuples created in Question 1.
The output format should be a list of tuples too. Each tuple should contain a philosopher's name
and its most similar other philosopher. Please note both names can't be the same.
The output should look like that:
[('Acrion', 'Athenodoros Cananites'),
('Adrastus of Aphrodisias', 'Andronicus of Rhodes'),
('Aedesia', 'Ammonius of Athens'),
('Aedesius', 'Arete of Cyrene'),
('Aeneas of Gaza', 'Ammonius Hermiae'),
...]
"""
def run(filenames):
###
### YOUR CODE HERE
###
# Once done, try this:
run(filenames)


tag. Assuming that page_soup contains the entire bs4 object for the page, the following code should get you all the relevant text on the page: all_text = "" for tag in page_soup.find_all('p'): all_text += tag.get_text() We downloaded all of the philosophers' pages from the list, and extracted and saved their text. They are in the 'Philosophers' folder. Question 3 Use the files under "Philosophers" folder to construct an LSI model. Then, use the LSI model to find the most similar philosopher for each of the philosophers found in Question 1, based on the content of their Wikipedia articles. You MUST NOT go online to scrape the data; everything you need is in your Jupyter notebook working directory. The function should have as input the list of tuples created in Question 1. The output format should be a list of tuples too. Each tuple should contain a philosopher's name and its most similar other philosopher. Please note both names can't be the same. The output should look like that: [('Acrion', 'Athenodoros Cananites'), "Adrastus of Aphrodisiac', 'Andronicus of Rhodes"), ('Aedesia', 'Ammoniumhens'), ('Aedesius', 'Arete of Cyrene"), ('Aeneas of Gaza', 'Ammoniumermiae"), ...] The name of the author must be the 'title' tag found in the 'Index.html'. Be careful, if it is not the case, the grader will not detect your answer and you'll get no points. NOTE_1: For processing speed purposes, the table in "Index.html" has been shortened compared to the one online on wikipedia.org. Do not worry if you do not find some philosophers in your results, this is made on purpose.There are some instructions for submitting the assignment: 1. You only need to write your code in the comment area \"Your Code Here". jupyter Control Panel Files Running Clusters Select items to perform actions on them. Upload New Name + Last Modified + O O Philosophers 3 months ago O O resource 2 days ago O a textmining.ipynb 2 days ago O _ Index.html 3 months agojupyter textmining Last Checkpoint: Last Saturday at 8:04 PM (autosaved) Control Panel File Edit View Insert Cell Kernel Widgets Help Not Trusted Python 3.5 0 C Markdown There are some instructions you need to follow: . You only need to write your code in the comment area "Your Code Here". . Do not upload your own file. Please make the necessary changes in the Jupyter notebook file already present in the server. . Please note, there are several cells in the Assignment Jupyter notebook that are empty and read only. Do not attempt to remove them or edit them. They are used in grading your notebook. Doing so might lead to 0 points. In [1] : import nitk import os import _sqlite3 from nitk. corpus import PlaintextCorpusReader from nitk import sent_tokenize, word_tokenize from gensim import corpora, models, similarities from gensim. models . Idamodel import LdaModel from gensim. parsing . preprocessing import STOPWORDS from gensim. similarities . docsim import SimilarityQuestion 1 In [2] : Question 1 Write a function that takes the file name of the Wikipedia page containing all Greek ancient philosophers (saved as "Index. html" in your workspace) and returns a list tuples containing the name of the philosopher and the path to its individual article file. Example of use: get_philosophers ( "Index. html") The output should be a list of tuples: [ ( 'Acrion' , 'Philosophers/Acrion . html' ) , ( 'Adrastus of Aphrodisiac' , 'Philosophers/Adrastus of Aphrodisiac . html' ) , ( 'Aedesia' , 'Philosophers/Aedesia . html' ) , ( 'Aedesius', 'Philosophers/Aedesius . html' ) , ( 'Aeneas of Gaza' , 'Philosophers/Aeneas of Gaza. html' ) , ( 'Aenesidemus' , 'Philosophers/Aenesidemus . html' ), NOTE: For processing speed purposes, the table in "Index. html" has been shortened compared to the one online on wikipedia. org. Do not worry if you do not find some philosophers in your results, this is made on purpose. def get_philosophers (filename ) : import codecs from bs4 import BeautifulSoup f = codecs . open (filename, 'r' , 'utf-8') soup = BeautifulSoup (f. read( ) , '1xml ' ) ### ### YOUR CODE HERE # ## # Once done, try this: filenames = get_philosophers ( "Index. html") filenamesQuestion 2 In [3] : Question 2 Write a function that scrapes the text on a philosophers's page and returns it as a text string. The input is the name of the file that contains the philosoph's page. Example of use: get_text ( 'Philosophers/Acrion. html' ) should output the text of the page. 'Acrion was a Locrian and a Pythagorean philosopher...' def get_text (file) : ### ### YOUR CODE HERE # ## # Once done, try this: get_text ( "Philosophers/Acrion . html" ) Out [3]: 'Acrion was a Locrian and a Pythagorean philosopher. [1] He is mentioned by Valerius Maximus [2] under the name of Arion. According to William Smith, Arion is a false reading, instead of Acrion. [3] \ 'Question 3 In [4] : Question 3 Use the files under "Philosophers" folder to construct an LSI model. Then, use the LSI model to find the most similar philosopher for each of the philosophers found in Question 1, based on the content of their Wikipedia articles. You should not go online to scrape the data; everything you need is in your Jupyter notebook working directory. The function should have as input the list of tuples created in Question 1. The output format should be a list of tuples too. Each tuple should contain a philosopher's name and its most similar other philosopher. Please note both names can't be the same. The output should look like that: [ ( 'Acrion' , 'Athenodoros Cananites' ) , ( 'Adrastus of Aphrodisiac' , 'Andronicus of Rhodes' ) , ( 'Aedesia' , 'Ammonium of Athens' ) , ( 'Aedesius' , 'Arete of Cyrene' ) , ( ' Aeneas of Gaza' , 'Ammonium Hermiae' ) , . . . ] def run (filenames ) : # ## ### YOUR CODE HERE # ## # Once done, try this: run ( filenames )
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Introduction to Wireless and Mobile Systems
Authors: Dharma P. Agrawal, Qing An Zeng
4th edition
1305087135, 978-1305087132, 9781305259621, 1305259629, 9781305537910 , 978-130508713