

Question
Use R programming (R studio) to respond to the inquiry. Use have 5 factors with 480 perceptions. To get to the information utilize the accompanying
Use "R programming (R studio)" to respond to the inquiry. Use have 5 factors with 480 perceptions. To get to the information utilize the accompanying R order: frozen yogurt <-readRDS(url("https://ecnp003.netlify.app/information/icecream.rds")) Requirements: I. assist me with figuring out the information; ii. give proof that arbitrarily relegating average working days and areas is a sub-par procedure; and, iii. to exhort me on a more ideal task of average working days and areas for every deals specialist. Note: There is no word/space limit (it very well may be as short or as long as you can imagine). There are likewise no designing prerequisites. Nonetheless, compose report in a R Notebook (see https://bookdown.org/yihui/rmarkdownotebook.html) and present a solitary. Rmd (R Markdown) record. This record ought to be completely reproducible and I should have the option to arrange it (see https://davidzeleny.net/wiki/doku.php/recol:reproducible_script for direction on planning reproducible and compact R script).
I might want to know how to use For circle to consequently gather important information since I can do physically individually.
Here is the example information (https://ideone.com/eypcRj).
This information is Google's people group portability information in the Netherlands which is openly accessible.
GM_combined = pd.read_csv("textfile.txt") #the URL text document here
#A touch of cleaning GM_combined = GM_combined.rename(columns={'date': 'Date'})
GM_combined["Date"] = pd.to_datetime(GM_combined["Date"]) GM_combined.sort_values(by='Date', ascending=True) GM_region_1 = GM_combined.loc[(GM_combined['place_id'] != 'ChIJu-SH28MJxkcRnwq9_851obM')] GM_region_1['sub_region_1'].unique()
What I need to do is to code circling which gets:
a new dataframe for each "sub_region_1" with a dataframe name setted as the name of every area - - - allude (1) each dataframe of the sub_region_1 has mean worth of segments beneath gathered by "Date" - - - allude (2) 'retail_and_recreation_percent_change_from_baseline', 'grocery_and_pharmacy_percent_change_from_baseline', 'parks_percent_change_from_baseline', 'transit_stations_percent_change_from_baseline', 'workplaces_percent_change_from_baseline', 'residential_percent_change_from_baseline' rename these sections in 2 as "Sub-district 1-name_following": - - - allude (3) 'retail_and_recreation_percent_change_from_baseline': 'Sub-district 1-name_Retail_Rec_%Change', 'grocery_and_pharmacy_percent_change_from_baseline': 'Sub-district 1-name_Grocery_Pharma_%Change',
'parks_percent_change_from_baseline': 'Sub-district 1-name_Parks_%Change',
'transit_stations_percent_change_from_baseline': 'Sub-district 1-name_Transit_%Change',
'workplaces_percent_change_from_baseline': 'Sub-district 1-name_Workplace_%Change',
'residential_percent_change_from_baseline': 'Sub-district 1-name_Resident_%Change'
4. change the date section in each of new dataframe of sub_region_1 - - - allude (4)
#the name of dataframe can rely upon each of new dataframe Drenthe["Date"] = pd.to_datetime(Drenthe["Date"]) Drenthe.set_index('Date', inplace=True) Drenthe = Drenthe.asfreq("D")
Essentially, I have this manual coding underneath for every area (I just put one district as an example), however in the event that you can assist me with utilizing For Loop to naturally create a new dataframe per sub_region_1, I would be truly apprecaited.
Drenthe = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Drenthe')] #(1)
###I mannually coded new dataframe per locale like this. #Flevoland = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Flevoland')] #Friesland = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Friesland')] #Gelderland = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Gelderland')] #Groningen = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Groningen')] #Limburg = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Limburg')] #North_Brabant = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'North Brabant')] #North_Holland = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'North Holland')] #Overijssel = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Overijssel')] #South_Holland = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'South_Holland')] #Utrecht = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Utrecht')] #Zeeland = GM_region_1.loc[(GM_region_1['sub_region_1'] == 'Zeeland')]
#I might want to emphasize this cycle per "sub_region_1" area. #(2) Drenthe = Drenthe.groupby('Date', as_index=False, sort=False)['retail_and_recreation_percent_change_from_baseline', 'grocery_and_pharmacy_percent_change_from_baseline', 'parks_percent_change_from_baseline', 'transit_stations_percent_change_from_baseline', 'workplaces_percent_change_from_baseline', 'residential_percent_change_from_baseline'].mean()
#(3) Drenthe = Drenthe.rename(columns={'retail_and_recreation_percent_change_from_baseline': 'Drenthe_Retail_Rec_%Change', 'grocery_and_pharmacy_percent_change_from_baseline': 'Drenthe_Grocery_Pharma_%Change', 'parks_percent_change_from_baseline': 'Drenthe_Parks_%Change', 'transit_stations_percent_change_from_baseline': 'Drenthe_Transit_%Change', 'workplaces_percent_change_from_baseline': 'Drenthe_Workplace_%Change', 'residential_percent_change_from_baseline': 'Drenthe_Resident_%Change'})
#(4) Drenthe["Date"] = pd.to_datetime(Drenthe["Date"]) Drenthe.set_index('Date', inplace=True) Drenthe = Drenthe.asfreq("D")
PS: as I just included 400 line of test information, you may not track down each district in this code.
I didn't check the number of interesting districts are remembered for this example text document.
As I don't know such a huge amount about circling, I would truly see the value in it in the event that you can give point by point request of clarifications to how you did as such I can apply in the future as well.p
Bizarrely high grouping of metals in drinking water can represent a wellbeing peril. Twenty couples of information were taken from various areas of Ku? Cenneti Lake estimating zinc focus in base water and surface water. Table 1.Zinc Concentration (mg/l) in base and surface water in various locales and areas of Karacakaan Lake Location Region Area Zinc_Bottom Zinc Surface Zinc_ Mean TZ3_Mean Area 0.51 2.67 0.49 0.50 Loc 1 North An Area 0.46 2.45 0.45 0.46 North 0.46 A Loc 2 Area 0.52 2.66 0.52 0.52 Loc 3 North An Area 0.50 0.50 2.56 0.51 Loc 4 North An Area 0.58 3.03 0.57 0.58 Loc 5 North A
answer every one of the inquiries
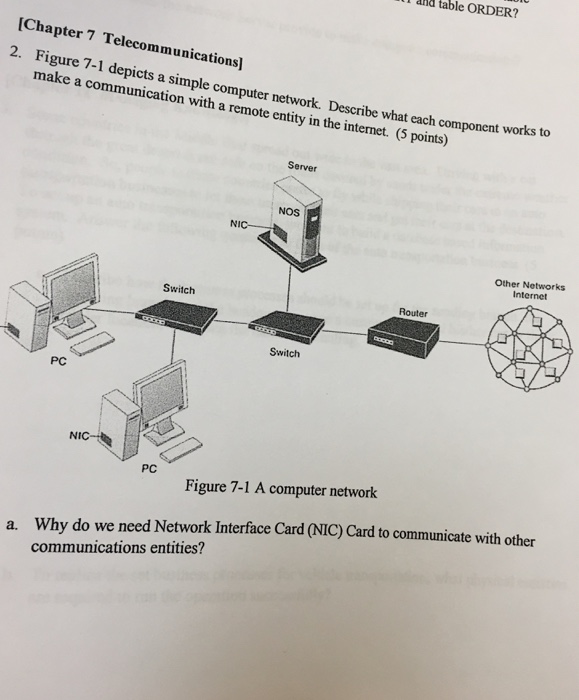
table ORDER? [Chapter 7 Telecommunications] 2. Figure 7-1 depicts a simple computer network. Describe what each component works to make a communication with a remote entity in the internet. (5 points) PC Switch Server NIC- NOS Switch NIC PC Figure 7-1 A computer network Router Other Networks Internet a. Why do we need Network Interface Card (NIC) Card to communicate with other communications entities?
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Income Tax Fundamentals 2013
Authors: Gerald E. Whittenburg, Martha Altus Buller, Steven L Gill
31st Edition
1111972516, 978-1285586618, 1285586611, 978-1285613109, 978-1111972516