

Given a set of training samples DN = x1, x2, , xN , the so-called empirical distribution
Question:
Given a set of training samples DN =
x1, x2, , xN
, the so-called empirical distribution corresponding to DN is defined as follows:
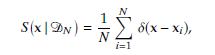
where ¹º denotes Dirac’s delta function. Show that the MLE is equivalent to minimizing the Kullback–
Leibler (KL) divergence between the empirical distribution and the data distribution described by a generative model pˆ¹xº:
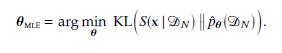
Fantastic news! We've Found the answer you've been seeking!
Step by Step Answer:

Answered By
Robert Mwendwa Nzinga
I am a professional accountant with diverse skills in different fields. I am a great academic writer and article writer. I also possess skills in website development and app development. I have over the years amassed skills in project writing, business planning, human resource administration and tutoring in all business related courses.
187+ Reviews
378+ Question Solved
Related Book For 

Machine Learning Fundamentals A Concise Introduction
ISBN: 9781108940023
1st Edition
Authors: Hui Jiang
Question Posted:
