

Question
I need help with the following functions below in python. I am using a csv file which can be found here- https://1drv.ms/x/s!Aj0EGBNy0RCLjWRF51Lye2y56X8H This program will
I need help with the following functions below in python. I am using a csv file which can be found
here- https://1drv.ms/x/s!Aj0EGBNy0RCLjWRF51Lye2y56X8H
This program will require you to work with modules, global variables, CSV files, and nested dictionaries.
- You will be writing a module. The module should not have a main or call any of its functions at the top level. It should only define functions and global variables.
- As a convention, you might want to start all of the global variables in the module with an _ (underscore) so they stand out. These will be a useful place to hold the dictionaries you create during the analysis.
- You need to implement below functions:
-
init() - This function should parse your CSV file and read all the lines. Lines read by this function should be reused by rest of the functions. In this way you avoid reading file multiple times for each of your functions.
-
genderDistribution() - Should return a dictionary for entire M and F population in the school
-
collegeDistribution() - Should return a nested dictionary for each of the college in the school with it's respective M and F population
-
departmentDistribution() - Should return a nested dictionary for each of the department in the school with it's respective M and F population
-
majorDistribution() - Should return a nested dictionary for each of the major in the school with it's respective M and F population
-
termDistribution() - Should return a nested dictionary for each term in the school with it's respective M and F population
-
For each of the below columns, create a dictionary with M and F population:
- College
- Department
- Major
- Term
In most cases, dictionaries are nested so you might want to review how to create, access, and update nested dictionaries.
-
Comma Separate Value (CSV) files are fairly common and useful since they may easily to loaded into a spreadsheet for analysis.
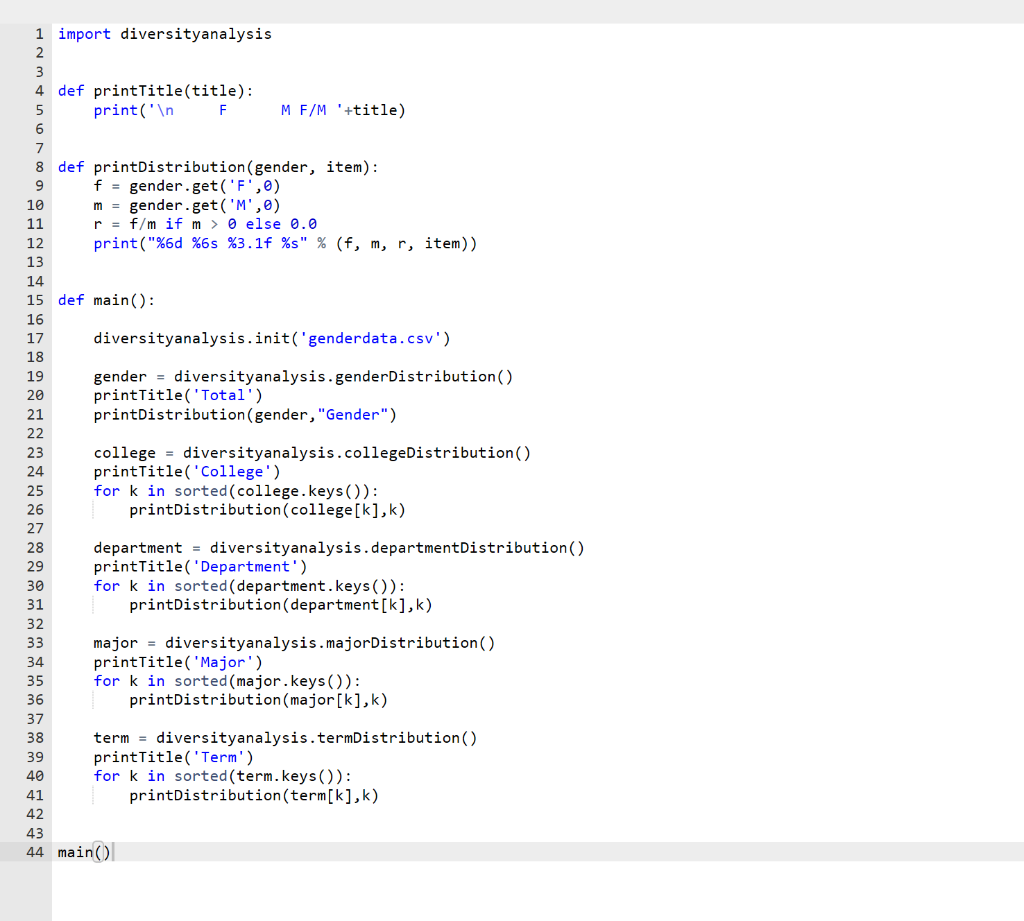
Here is the main:
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Sql++ For Sql Users A Tutorial
Authors: Don Chamberlin
1st Edition
0692184503, 978-0692184509