

Question
Ok just a few more issues in my code! project 2 part G and H previous code: Part A import numpy as np import pandas
Ok just a few more issues in my code! project 2 part G and H
previous code:
Part A
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, expr
spark = SparkSession.builder.getOrCreate()
Part B
from pyspark.sql.types import StructType, StructField, IntegerType, StringType
accepted_schema = StructType([
StructField("acc_term_id", StringType(), True),
StructField("sid", IntegerType(), True),
StructField("first_name", StringType(), True),
StructField("last_name", StringType(), True),
StructField("major", StringType(), True)
])
alumni_schema = StructType([
StructField("sid", IntegerType(), True)
])
expelled_schema = StructType([
StructField("sid", IntegerType(), True)
])
unretained_schema = StructType([
StructField("sid", IntegerType(), True)
])
faculty_schema = StructType([
StructField("fid", IntegerType(), True),
StructField("first_name", StringType(), True),
StructField("last_name", StringType(), True),
StructField("dept", StringType(), True)
])
courses_schema = StructType([
StructField("dept", StringType(), True),
StructField("course", StringType(), True),
StructField("prereq", StringType(), True),
StructField("credits", IntegerType(), True)
])
grades_schema = StructType([
StructField("term_id", StringType(), True),
StructField("course", StringType(), True),
StructField("sid", IntegerType(), True),
StructField("fid", IntegerType(), True),
StructField("grade", StringType(), True)
])
accepted = spark.read.csv("/FileStore/tables/univ/accepted.csv", header=True, schema=accepted_schema)
alumni = spark.read.csv("/FileStore/tables/univ/alumni.csv", header=True, schema=alumni_schema)
expelled = spark.read.csv("/FileStore/tables/univ/expelled.csv", header=True, schema=expelled_schema)
unretained = spark.read.csv("/FileStore/tables/univ/unretained.csv", header=True, schema=unretained_schema)
faculty = spark.read.csv("/FileStore/tables/univ/faculty.csv", header=True, schema=faculty_schema)
courses = spark.read.csv("/FileStore/tables/univ/courses.csv", header=True, schema=courses_schema)
grades = spark.read.csv("/FileStore/tables/univ/grades.csv", header=True, schema=grades_schema)
dataframes = [accepted, alumni, expelled, unretained, faculty, courses, grades]
names = ["accepted", "alumni", "expelled", "unretained", "faculty", "courses", "grades"]
for name, df in zip(names, dataframes):
count = df.count()
print(f"The number of records in {name} is {count}.")
Part C
enrolled = accepted.join(grades, accepted.sid == grades.sid, "inner").select(accepted.sid.alias("enrolled_sid"), "*")
current = enrolled.join(alumni, enrolled.enrolled_sid == alumni.sid, "left_anti") \
.join(unretained, enrolled.enrolled_sid == unretained.sid, "left_anti") \
.join(expelled, enrolled.enrolled_sid == expelled.sid, "left_anti")
former = enrolled.join(current, enrolled.enrolled_sid == current.enrolled_sid, "left_anti")
counts = {
"Number of accepted students: ": accepted.count(),
"Number of enrolled students: ": enrolled.count(),
"Number of current students: ": current.count(),
"Number of former students: ": former.count(),
"Number of unretained students:": unretained.count(),
"Number of expelled students: ": expelled.count(),
"Number of alumni: ": alumni.count()
}
for key, value in counts.items():
print(f"{key} {value}")
Part D
num_current_students = current.count()
major_distribution = current.groupBy('major').count()
major_distribution = major_distribution.withColumnRenamed('count', 'n_students')
major_distribution = major_distribution.withColumn('prop',
(col('n_students') / num_current_students).cast('double'))
major_distribution = major_distribution.orderBy('prop', ascending=False)
major_distribution.show()
Part E
sp21_enr = grades.filter(grades.term_id == "2021A")
department_enrollments = sp21_enr.join(courses, sp21_enr.course == courses.course, "inner")
department_enrollments = department_enrollments.groupBy("dept").count().withColumnRenamed("count", "n_students")
total_enrollments = sp21_enr.count()
department_enrollments = department_enrollments.withColumn("prop", (col("n_students") / total_enrollments).cast("double"))
department_enrollments = department_enrollments.orderBy("prop", ascending=False)
department_enrollments.show()
Part F:
former_by_major = former.groupBy("major").count() \
.withColumnRenamed("count", "n_former") \
.orderBy("major")
alumni_by_major = alumni.join(accepted, accepted.sid == alumni.sid, "inner") \
.groupBy("major").count() \
.withColumnRenamed("count", "n_alumni") \
.orderBy("major")
graduation_rates = former_by_major.join(alumni_by_major, "major", "left") \
.withColumn("grad_rate", (col("n_alumni") / col("n_former")).cast("double")) \
.orderBy("major")
graduation_rates.show()
Part G:
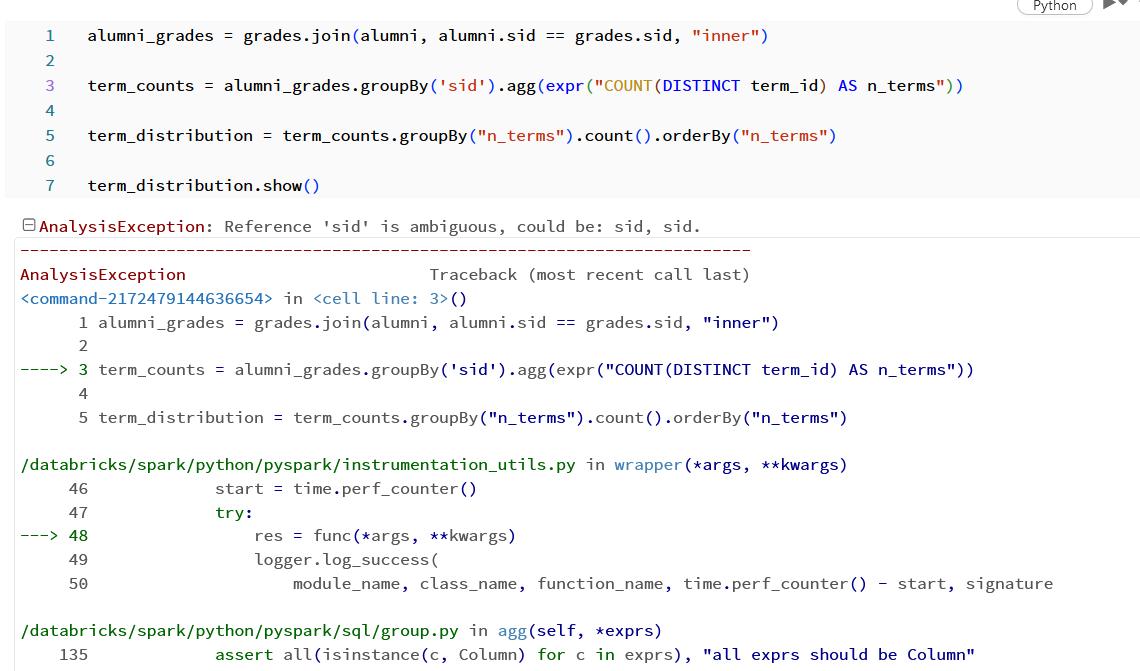
Part H: I have the same ‘sid’ error as G.
from pyspark.sql.functions import udf
from pyspark.sql.types import DoubleType
def letter_to_num(letter_grade):
grade_mapping = {"A": 4.0, "B": 3.0, "C": 2.0, "D": 1.0, "F": 0.0}
return grade_mapping.get(letter_grade, 0.0)
letter_to_num_udf = udf(letter_to_num, DoubleType())
current_gpa = grades.join(courses, grades.course == courses.course, "inner") \
.withColumn("num_grade", letter_to_num_udf(col("grade"))) \
.withColumn("gp", col("credits") * col("num_grade")) \
.groupBy("sid").agg(expr("SUM(gp) AS gp_sum"), expr("SUM(credits) AS credits_sum")) \
.withColumn("gpa", (col("gp_sum") / col("credits_sum")).cast("double")) \
.join(current, "sid", "inner") \
.select("sid", "first_name", "last_name", "major", "gpa") \
.orderBy("gpa")
current_gpa.show(10)


Part G: Number of Terms Required for Graduation In this part, we will find a frequency distribution for the number of terms that alumni required for graduation. Perform the steps below by chaining together DataFrame methods in a single multi-line statement. Apply a filtering join to the grades DataFrame to keep only records associated with alumni. Group the filtered Data Frame according to sid. Perform an aggregation to count the number of DISTINCT values of term_id appearing for each alumnus. Name the resulting column n_terms. Group this most recent result according to n_terms. Perform an aggregation to count the number of records associated with each value of n_terms. Name the resulting column n_alumni. Sort the results by n_terms. Use show() to display all records in the the resulting DataFrame.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Business A Changing World
Authors: O. C. Ferrell, Geoffrey Hirt, Linda Ferrell
10th edition
1259179397, 978-1259179396