

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
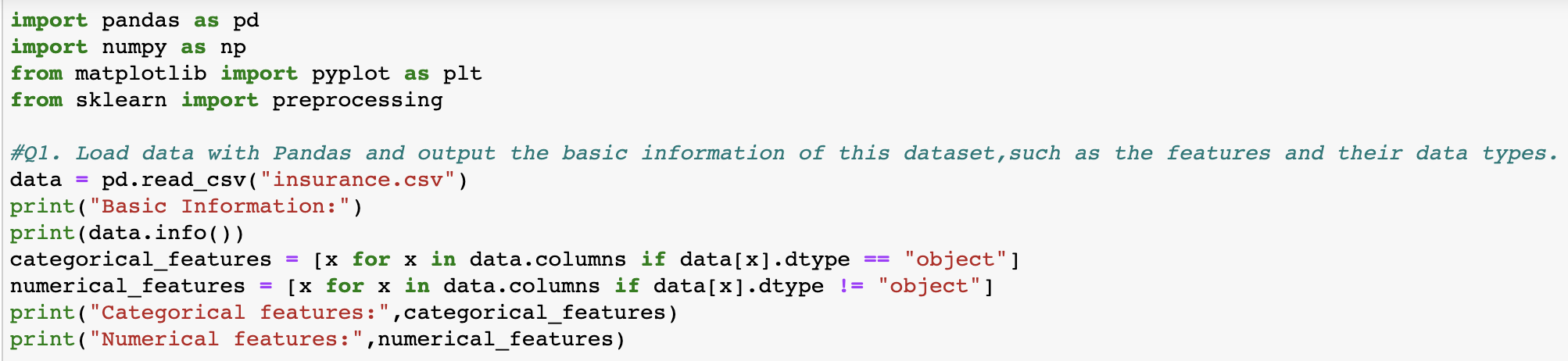
import pandas as pd import numpy as np from matplotlib import pyplot as plt from sklearn import preprocessing #01. Load data with Pandas and output

Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Oracle PL/SQL Programming Database Management Systems
Authors: Steven Feuerstein
1st Edition
978-1565921429