

Question
Model the following data in C++: data_v1.csv Be sure to create an effective and efficient class structure for the data. This will be part of
- Model the following data in C++: data_v1.csv
- Be sure to create an effective and efficient class structure for the data. This will be part of your grade. The grading rubric is below.
- Take note that the reports have some internal structure and behavior as well. Create an effective and efficient object hierarchy for your reports.
- DESIGN NOTES:
- IMPORTANT: Give this first step some serious, deep thought before you jump into writing code.
- Draw out all your objects. You might want to use UML; it's powerful and compact. Use whatever works for you, but draw it out and then use your diagrams as you are writing your coding.
- List all your instance variables, methods, operators, comparators, and iterators.
- Decide what should be private, public or protected?
- Think about the constructors, setters, and getters you will need. Will you overload any of them? Will you override any methods?
- Employ multiple inheritances, overloading and overriding, as appropriate.
- Are there any virtual functions? Any pure virtual functions?
- I will be using different datasets to grade your project, so be thinking about general coding concerns and expected edge cases. For example, what does your code do with an empty file, a non-existent file, a file with one line, a file where every line is repeated twice.
- Are there any other important questions to answer at this stage?
- Be sure to reread this first section after you have read through the entire assignment instructions once.
- And then read it once again after you complete your initial design, to make sure you have handled everything in your design for the assignment.
- IMPORTANT: Give this first step some serious, deep thought before you jump into writing code.
-
- Read the data from the CSV file into the internal data structure you have designed.
- DATA NOTES:
- CSV stands for Comma Separated Values, and it is a very common file format. The only commas in this data file are the commas (delimiters) that separate the different fields (columns) on each record (row) of data.
- I am supplying everyone with a working piece of code readCVS.cpp that reads CSV files so that no one gets stuck on this early task. It's crude, but it does work on the supplied data file. You may use any of this code in your project, so long as you properly cite it at the end of your main.cpp file.
- Use any ADT containers you would like to manage the data. I would expect to see at least one.
- Handle problems in the input data via exceptions. The supplied dataset will include the following errors, and there may be others:
- Missing field value(s), aka incomplete data report a warning on input, then ignore this row. (Missing data will appear as two or more consecutive commas on one line (row) in the CSV file.)
- Duplicate rows - report a warning on input, then ignore these as well.
- You might want to get things working first without handling the input exceptions (try-catch-throw). Partial credit will be awarded in that case. But note that the reports with incorrect data will be wrong. GIGO
- DATA NOTES:
-
- Create the following 3 data reports:
- An "Employee Phone Number List" Report that lists: ID, LastName, FirstName, and PhoneNumber. Sorting is optional.
- An "Input Data Quality Report" that lists all the data, in the order it was input. It follows the input data with 3 error sections that describe the data quality problems that may have occurred. You might want to do this report after everything else is working.
- While listing the data that was read, print a single line with a single "*" (asterisk) to indicate when there was a problem with a row of input data. You can include a description of the problem after the asterisk.
- At the end of the "Input Data Quality Report", provide 3 "Data Quality Exceptions Sections":
- A list of any "Duplicates" (duplicates should be ignored as data).
- Records are considered duplicates if the ID is duplicated.
- List each duplicated original input line in this section.
- Summarize this section with the "Total Count of Duplicate Records".
- A list of any "Incomplete Records" incomplete (these should be ignored as data).
- Records are considered incomplete if any field is missing a value.
- Print each incomplete record by printing the original input line in this section.
- Summarize this section with the "Total Count of Incomplete Records".
- Finally, in an " Exceptions Section Summary", list the "Total Error Count" (the sum of 1 and 2 above), and "Total Good Records Count".
- A list of any "Duplicates" (duplicates should be ignored as data).
- This "Input Data" report can be requested at any time by the user. (See #6 below.)
- Be sure to include a data header row in the appropriate places in this multi-part report.
- For the 3rd report, design your own report that takes advantage of your object-oriented design.
- REPORT NOTES:
-
- All reports should have:
- A Title,
- A header row (column names),
- Followed by all the report data.
- At the end of every report, you should print a message indicating how many "Total Rows" were in the report. Do not count the header in this count.
- Reports should be written to "court".
- You should consider creating a method called InfoToString to create the output strings that will be printed in each report.
- Use this method to create the strings (lines) that you will print out in all the reports.
- See if you can also use some form of this method to create the "Column Header" line for each report.
- Then each PrintReport method just prints out all these strings, each on a separate line, followed by the report line total count.
- Ideally, the columns of each report will line up vertically.
- You might choose to get this "columnization" to work after you have everything else working unless not having things in columns makes your code debugging too difficult. [A hint on how to do this is in the read CVs.cpp example file.]
- The Employee ID is expected to be unique. You will enforce this by ignoring rows with duplicate IDs. Employee names and locations may not be unique.
- IMPORTANT: CLion has a default 120 character limit on output. See the "Removing CLion's 120 character output limit" section below on how you can remove that limit so your reports will display properly.
- All reports should have:
-
- Create the following 3 analytical reports:
- An "Employee Cluster Report" shows the number of employees living in each ZipCode. The report lists the ZipCode, City, State, and EmployeeCount.
- List each ZipCode only once.
- Sorting by ZipCode is optional.
- This report might be used to help decide where to build the next company office building.
- An "Employee Pay Raise Report" shows EmployeeName, Salary, NewSalary, and RaiseAmount, where each employee gets a 2.5% raise.
- Write a CalculateEmployeeRaise method that takes one double argument, the percent raise. Use it to give each employee a raise.
- Note that NewSalary is a data element not in the original data file.
- Sorting the report by the RaiseAmount is optional.
- Be sure to include the employee's full name in the report.
- An "Employee Regional Raises Report", showing the total of the raises by ZipCode. Sorting is optional.
- An "Employee Cluster Report" shows the number of employees living in each ZipCode. The report lists the ZipCode, City, State, and EmployeeCount.
-
- Create 2 Unit Tests in a simple Test Harness.
- Test01: Test that you get the correct number of rows printed in one of your reports. Provide a small test dataset (in the code), create the objects that would be created if this data had been read in, and then check that the resulting total number of rows that would be printed is correct. Return an appropriate value to the test harness.
- Test02: Test the analysis of one of your analytic reports by providing a small test dataset (in the code), build your objects from it, generate the report, and check the result of the analysis. The "Employee Cluster Report" or the "Employee Regional Raises Report" are good candidates for this test, as they each have a summary number you can check in your test. Return an appropriate value to the test harness.
- TEST NOTES:
- Creating good test cases involves both good coding design and good test data choices.
- Ideally, these test cases should not read from files. They should have all their data in the code. But its ok to implement your test cases that read from specific test data files.
- It is the test harness that executes the tests. The test harness then takes the result from a test case being called and prints out an appropriate test result message, based on the result of the test.
- Add any additional test cases that you think are appropriate.
-
- Finally, orchestrate everything with the main menu loop that asks the user what they would like to do.
- Determine the input file name to use:
- Provide an option that will read the file: data_v1.csv
- Provide an option for the user to type in the filename to be read. You might find this useful in your own testing.
- Determine the user's desired processing:
- Allows the user to select any report, any test case, or Quit.
- Provide an "All" option that runs all the reports and all test cases.
- Allow the user to read data from a different file (see 6.a.ii above).
- Be sure to print out all the available menu options at least once.
- Determine the input file name to use:
- Deliverables:
- A single compressed .zip file folder containing the source code files and data files only.
- Don't just zip the whole project folder. It confuses CLion.
- Include data_v1.csv and any additional .csv files that you created.
- Please label the zip folder in this format: [LastName]_[FirstName]_final.zip
- For example: cameron_andy_final.zip
- Your project will be graded in CLion, not zyBooks. It needs to compile and run in CLion.
- Submit the file on Canvas by the deadline.
- Only the last submission on Canvas will be graded
- A series of automated tests will be used to grade your code's functionality (Items 2, 3, 6, and 7 from the rubric above). Here are the menu selectors that the grading test harness will use when it automatically runs and tests your code:
- A single compressed .zip file folder containing the source code files and data files only.
-
-
- F Read File: data_v1.csv
- I Specify the Input file name (requires a second input (string))
- N Phone Number List
- D Data Quality Report
- Y Your Custom Report
- C Employee Cluster Report
- P Employee Pay Raise Report
- R Regional Raises Report
- S Sequence of All Reports (order: N, D, Y, C, P, R)
- 1 Test01
- 2 Test02
- T All Tests (order: 1, 2)
- A All Reports and All Tests (order: S, T)
- Q Quit
- Don't be overwhelmed by this list. Start small and add functionality as you go. This is the hallmark of good software engineering.
-
-
- Remember, only your last Canvas submission will be graded, so you can submit your project to Canvas multiple times if you would like. You might consider these submissions to be check-ins when you get certain parts to work. Again, only the last submission will be graded.
-
In school, and in life, be sure to understand the task in front of you fully, and then prioritize your efforts to maximize your results (in this case your grade).
Remember to do your own work and to cite everything appropriately. If you talk to anyone about the project, be sure to document it. Discussing design alternatives is fine (if documented); copying or sharing code is not ok; except that using the supplied readCSV.cpp is allowed. Remember, the "double zero" penalty (as described in the syllabus) is in effect.
Resources:
- Data file: data_v1.csv
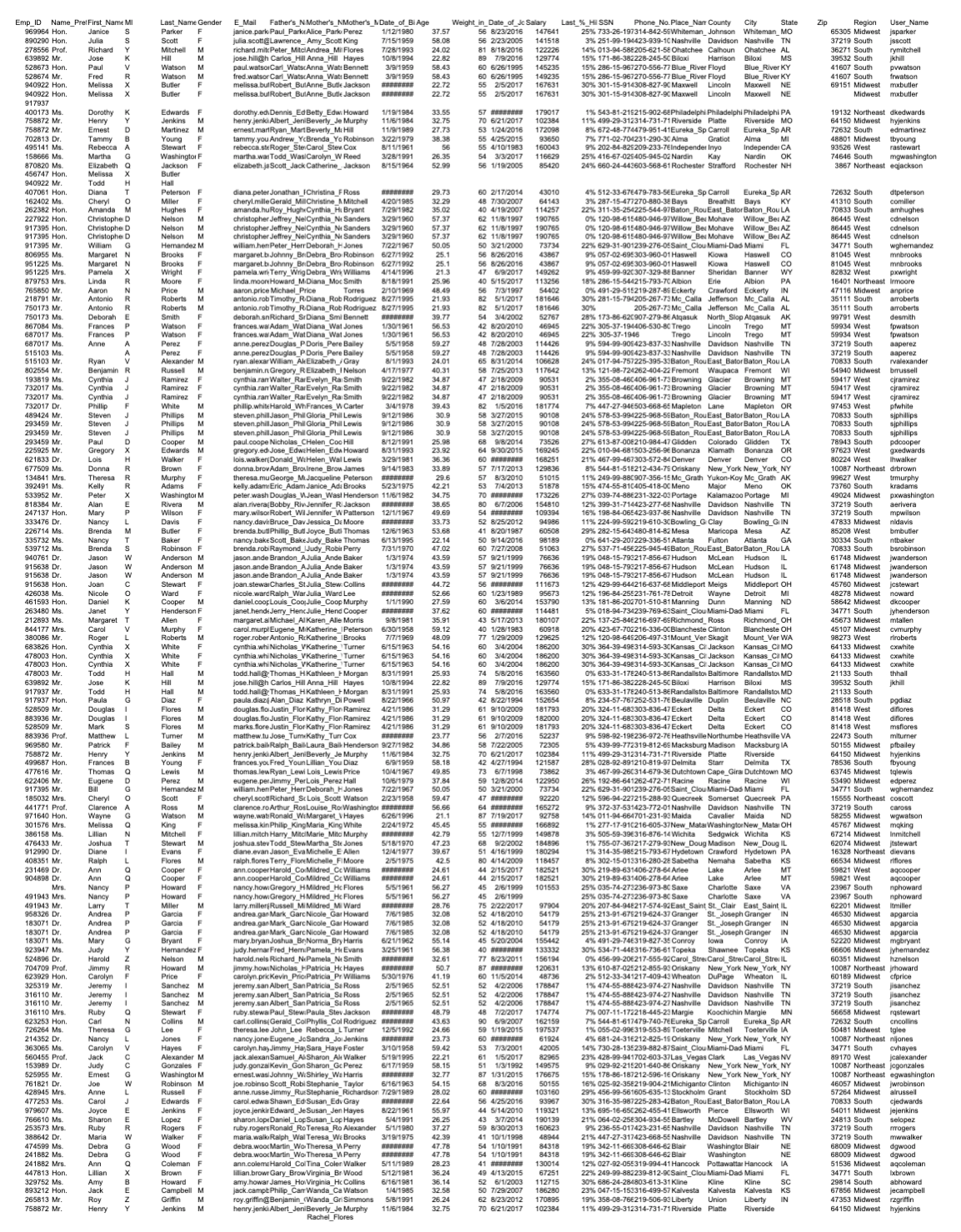
- Sample code: readCSV.cpp



-
Removing CLion's 120 character output limit:
- CLion has an (unexpected) character output limit that defaults to 120 characters. To remove it, so your reports look correct, do the following:
- Go to: Help -> Find Action -> Registry
- Unclick the box next to: run.processes.with.pty
- Click: Close
- See https://stackoverflow.com/questions/52268686/how-can-i-expand-the-max-width-of-the-run-tool-window-in-clion-intellij (Links to an external site.) for more information.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Processing
Authors: David J. Auer David M. Kroenke
13th Edition
B01366W6DS, 978-0133058352