

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
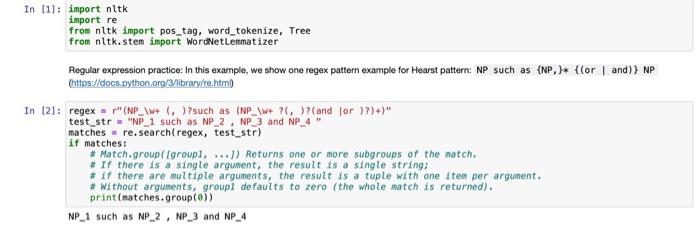
please implement step 2 In [1] : import nltk import re from nitk import pos_tag, word_tokenize, Tree from nitk.stem import WordNetLenmatizer Regular expression practice: In
please implement step 2
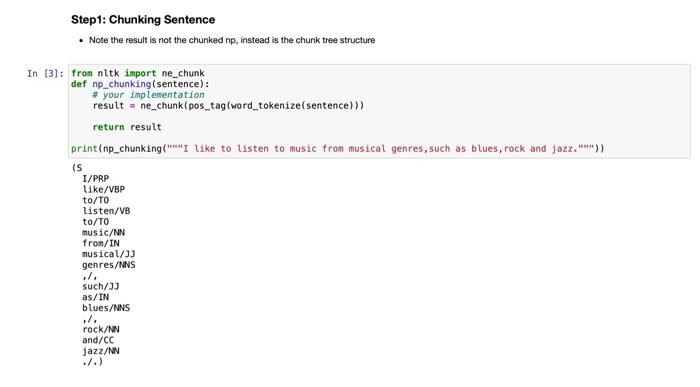
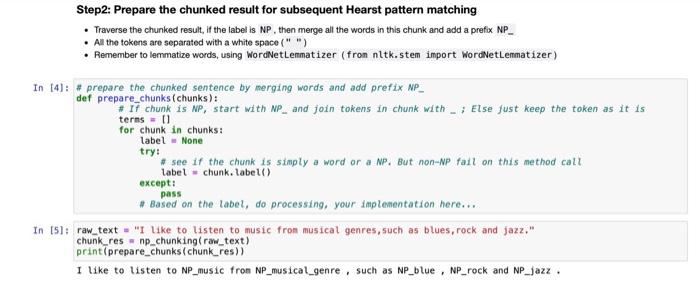
In [1] : import nltk import re from nitk import pos_tag, word_tokenize, Tree from nitk.stem import WordNetLenmatizer Regular expression practice: In this example, we show one regex pattern example for Hearst pattern: NP such as {NP,)* {lor | and}} NP (https://docs.python.org/3/library/re.htm) In [2): regex = "(NP_\W+ (,)?such as (NP_\W+ ?(,)? (and lor )?)+)" test_str = "NP_1 such as NP_2, NP_3 and NP_4 matches = re.search(regex, test_str) if matches: # Match.groupIgroupl, ...) Returns one or more subgroups of the match. # If there is a single argument, the result is a single string; # If there are multiple arguments, the result is a tuple with one item per argument. # Without arguments, groupl defaults to zero (the whole match is returned). print(matches.group()) NP_1 such as NP_2, NP_3 and NP_4 Step1: Chunking Sentence . Note the result is not the chunked np, instead is the chunk tree structure In [3]: fron nitk import ne_chunk def np_chunking(sentence): # your implementation result = ne_chunkipos_tag(word_tokenize sentence))) return result print(np_chunking like to listen to music from musical genres, such as blues, rock and jazz. )) (s I/PRP like/VBP to/TO listen/VB to/TO music/NN from/IN musical/J) genres/NNS .l. such/J) as/IN blues/NNS .l. rock/NN and/CC jazz/NN ./.) Step2: Prepare the chunked result for subsequent Hearst pattern matching Traverse the chunked result, if the label is NP, then merge all the words in this chunk and add a prefix NP_ . All the tokens are separated with a white space(" ") Remember to lemmatize words, using WordNetLenmatizer (fron nitk.stem import WordNetLenmatizer) In (4): prepare the chunked sentence by merging words and add prefix NP_ def prepare_chunks (chunks): # 17 chunk is NP, start with NP_ and join tokens in chunk with - Else just keep the token as it is terms=0 for chunk in chunks: label - None try: see if the chunk is simply a word or a NP. But non-NP fail on this method call label chunk. label() except: pass * Based on the label, do processing, your implementation here.... In ts: raw_text= "I like to listen to music from musical genres, such as blues, rock and jazz." chunk_res np_chunking(row_text) print(prepare_chunks (chunk_res)) I like to listen to NP_music from NP_musical_genre, such as NP_blue, NP_rock and NP_jazz Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Applications Of Databases First International Conference Adb 94 Vadstena Sweden June 21 23 1994 Proceedings Lncs 819
Authors: Witold Litwin ,Tore Risch
1st Edition
3540581839, 978-3540581833