New Semester
Started
Get
50% OFF
Study Help!
--h --m --s
Claim Now
Question Answers
Textbooks
Find textbooks, questions and answers
Oops, something went wrong!
Change your search query and then try again
S
Books
FREE
Study Help
Expert Questions
Accounting
General Management
Mathematics
Finance
Organizational Behaviour
Law
Physics
Operating System
Management Leadership
Sociology
Programming
Marketing
Database
Computer Network
Economics
Textbooks Solutions
Accounting
Managerial Accounting
Management Leadership
Cost Accounting
Statistics
Business Law
Corporate Finance
Finance
Economics
Auditing
Tutors
Online Tutors
Find a Tutor
Hire a Tutor
Become a Tutor
AI Tutor
AI Study Planner
NEW
Sell Books
Search
Search
Sign In
Register
study help
computer science
computer architecture
Computer Organization And Architecture Themes And Variations 1st Edition Alan Clements - Solutions
A 10" X 8" color picture is to be compressed using a lossy compression algorithm with a compression ratio of 20:1. If the image has a resolution of 72 dpi and each dot is made up of a trio of color pixels ( each pixel has 4,096 leve ls), what is the size of the image in bits?
Why does converting 64 pixels to 64 DCT functions help to compress a JPEG image?
Why are SIMD operations so common in multimedia applications?
You are building a hotel with 100 rooms. Each room is to have a video-on-demand television that displays movies in HDTV resolution of 1920 X 1080 pixels at 30 frames/s. If each pixel is 24 bits and you can compress video data by a factor of 100, determine the following. a. What is the maximum bit
Why did Intel initially take the decision to implement its multimedia extensions without modifying the processor's state architecture (i.e., by not implementing new registers, condition codes, or changes in exception processing)?
What is saturating arithmetic and what are its advantages and disadvantages in typical multimedia applications?
What is the effect of PCMPEQB MMO 'MMl ?
What is the effect of PCMPGTW MMO ' MM l ?
ARM processors perform predicated operations; for example ADDEQ performs an addition only if the Z-bit is set. Multimedia instructions that operate with multiple independent words don't set the condition code bits. For example, Intel's comparisons are used to set subwords to all Os or all ls that
If MMX registe rMMOcontains0012ABFF34807F6A16 and MMl contains F20361111888890A 16, what is the effect of executing each of the following instructions? a. PADDusb b. PADDub PADDsb PSUBSb e. PSUBub f. C. c. d. PADDusw MMO, MM1 MMO, MM1 MMO, MM1 MMO, MM1 MMO, MM1 MMO, MM1
What is the effect of each of the following instructions? Assume that MMO contains 0012ABFF34807F6A16 and MMl contains F20361111888890A16 at the start of each operation. a. PAND b. PACKuswb c. PCMGTb d. PCMGTW e. PSRAW f. PSRAb MMO, MM1 MMO, MM1 MMO, MM1 MMO, MM1 MMO, 5 MMO, 5
If MMO contains OxOOOl 0002 0003 0004 and MMl contains Ox0005 0006 0007 0008, what is the effect of PMADDWD MMO,MMl? .
The MMX architecture does not include conditional branch instructions. How then are conditional operations implemented by MMX?
Investigate the special-purpose multimedia facilities provided by some of today's computer manufacturers.
What is clipping and how can the MMX architecture be used to facilitate clipping operations?
The Intel Pentium has a CPUID (processor identification) instruction. Investigate this instruction and suggest ways in which it may be used.
Consider the following loop that adds a constant to a vector (we discussed this earlier). There's quite a lot of overhead associated with the solitary SIMD instruction. Suppose you were designing a new ISA that implemented operations like paddb. How would you make the code more efficient? movq mov
What is the effect of the PACKssdw MM0, MMl instruction if initially MMO contains OxE000001200000611 and MMl contains Ox00102222FFFFFFFF?
You decide to add a new architectural feature to a processor by creating some new instructions; that is, you are extending its ISA. What consequences could these additions have for the existing ISA?
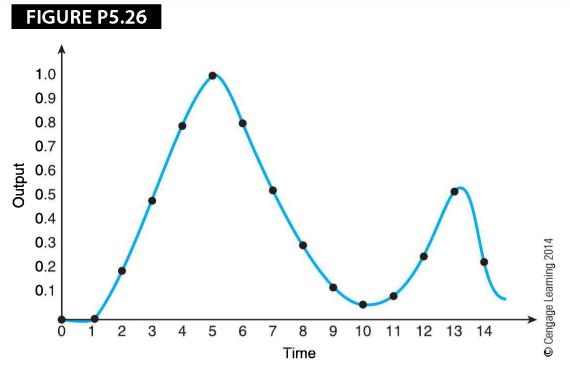
Consider the waveform in Figure P.5.26. If it were applied to a simple DSP with the transfer function y; = 0.7x; + 0.3x;_1, what would the output look like? Assume the data is 0.0, 0.0, 0.20, 0.5, 0.8, 1.0, 0.85, 0.55, 0.3, 0.15, 0.05, 0.1, 0.25, 0.50, and 0.24. FIGURE P5.26 Output 1.0 0.9 0.8 0.7
What lessons did Intel's MMX and AMD's 3DNow! extensions teach us about ISAs?
You are asked to design a new processor with a 64-bit word. Taking advantage of advances in technology, you decide that you can allocate an extra 5 bits to each word. That is, data words in registers and memory will occupy 69 bits. The additional 5 bits will be used to describe the data. How might
Explain what the following fragment of code achieves. the data is signed and that the packed shift right arithmetic instruction operates on word (16-bit) operands. MOVQ MMO, MM1 PSRAW MMO, 15 PXOR MMO, MM1
Consider the following block of operations that might be found inside a loop. Explain what the instructions do and what operation is being performed on the data. MOVQ MOVQ MM1, A MM2, B MOVO MM3, MM1 PSUBSB MM1, MM2 PSUBSB MM2, MM3 POR MM1, MM2 ;move 8 pixels of image A ;move 8 pixels of image B
What is performance in the context of computer systems and why is it so difficult to define?
A system consists of a CPU, cache memory, main store, and hard disk drive. Where are time and effort best spent improving the system's performance? What factors affect your answer?
Should metrics for computer performance be linear or non-linear? For example, if a linear metric has a value X, the metric 2X would imply twice the performance , whereas if the metric were logarithmic, the metric 2X would imply a ten-fold increase in performance.
Should metrics for computer performance be linear or non-linear? For example, if a linear metric has a value X, the metric 2X would imply twice the performance , whereas if the metric were logarithmic, the metric 2X would imply a ten-fold increase in performance. The master frame itself contains a
The time taken by machines A, B, and C to execute a given task is What is the performance of each of these machines relative to machine A? A B C 16 m, 9 s 14 m, 12 s 12 m, 47 s
Why is clock rate a poor metric of computer performance? What are the relative strengths and weaknesses of clock speed as a performance metric?
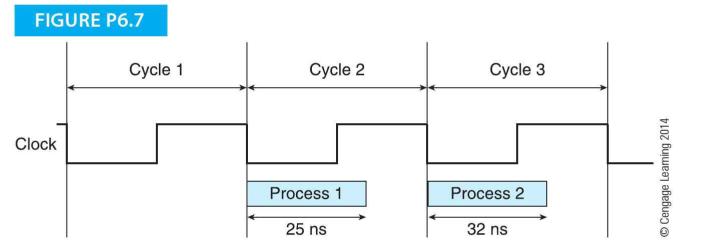
The timing diagram in Figure P6.7 illustrates a system in which ope rations occur as three consecutive clock cycles. Actions taking place in clock cycle 1 are scalable; that is, if the clock cycle time changes, the actions can be speeded up or slowed down correspondingly. In cycle 2, the action
What are the relative strengths and weaknesses of the MIPS as a metric of computer performance?
Can you think of a better metric than MIPS or clock speeds that gives a good impression of the power of a processor (without having to use benchmarks).
How is it possible for one computer with a low MIPS rating to have a better performance in practice than a computer with a high MIPS rating?
Overclocking a computer means operating it at a higher clock rate th an that specified by its manufacture r; for example, a 2 GHz chip might be clocked at 2.1 G Hz to squeeze more performance out of it.Does overclocking disprove the famous aphorism "There's no such thing as a free lunch," or is the
The following figures define the typical operating parameters of a processor. If the clock rate could be reduced by 15% , it would require only 2 cycles to perform a registe r load. Would that be a good idea? Operation Arithmetic/logical instructions Register load operations. Register store
A computer has the following parameters. If the average performance of the computer (in terms of its CPI) is to be increased by 20% while executing the same instruction mix, what target must be achieved for the cycles per conditional branch instruction? Operation Arithmetic/logical instructions
A program is run on a computer with the following parameters. What is the MIPS rating of this computer? Clock cycle time Instructions with 1 cycle Instructions with 2 cycles Instructions with 3 cycles 10 ns 70% 20% 10%
For the following data, what is the average number of cycles per instruction? Operation Arithmetic/logical instructions Register load operations Register store operations Unconditional branch instructions Conditional branch instructions Frequency Cycles 45% 1 18% 5 10% 2 7% 1 20% 6 Cengage
In a particular system, a CPU is used for 78% of the time and a disk drive for 22 % of the time. A designer has two options: a. improve the disc performance by 40% and the CPU performance by 20%. b. improve the disc performance by 10% and the CPU performance by 80%.Which is the better option, and
For the following systems that have both serial and parallel activities, calculate the speedup ratio. a. 10 processors b. 100 processors c. 5 processors d. 100 processors fs = 0.1 f, = 0.1 f = 0.4 f, = 0.01
A computer employed in arithmetic processing uses a software division routine. A program runs for two minutes on this machine with division taking 60% of the total time. If we wish to add a dedicated division unit in order to increase the performance of the computer by a factor of two, how much
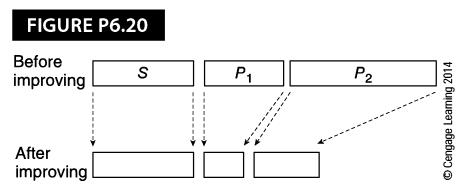
A system containing several operational units may have multiple enhancements. In Figure P6.20, a system consists of a process S followed by processes P1 and P2• Both processes P1 and P2 can be enhanced. If process P1 is enhanced by factor / 1 and process P2Is enhanced by factor f2, what is the
A program is executed in 200 ms during which 250 million instructions are executed. What is the average MIPS for this program?
A coprocessor is added to a computer to speed the execution time of string-processing instructions by a factor of 3.5. What fraction of the execution time must use these string-processing instructions in order to achieve an average speedup of 1.5?
Consider the current high-performance desktop computer and the laptop ( or notebook). Suppose you wish to increase the performance of both machines. Do you think that the same elements of the system (in both desktop and notebook forms) need improving equally, or do you think that the task of
Amdahl or Gustafson? Consider the following example. A physical process involving a flat area 100 units by 100 units is being simulated. Processing of the units can take place in parallel. However, there is a border region 10 units wide that goes round the square where parallel processing cannot
Someone decided to use the following C code as part of a benchmark to determine the performance of a computer including its memory. It has two potential faults. What are they? for (i = 0; i < 100; i++) { * s+12345 } P = q x = 0.0; for (j = 0; j < 60000; j++) { X = x + A[j] * B[j]; }
You are redesigning a system. You can replace the existing single processor by two P processors or by four Q processors. However, the P processors are able to run 80% of the code in parallel, whereas the Q processors are able to run 50% of the code in parallel. Which is the better option?
An operation can be speeded up by applying two different optimizations, 01 and 02• These optimizations operate on different parts of the process and there is no overlap. If 01 speeds up fraction f1 of the program by S1 and 02 speeds up fraction f2 of the program by S2, what is the overall speedup?
You manufacture a computer that executes a program in 50 minutes whereas your competitor's takes 45 minutes. How are you going to sell (advertise) your processor?
What are the relative advantages and disadvantages of arithmetic, geometric, and harmonic means as methods of averaging benchmarks?
For two benchmarks, x and y, show that their arithmetic mean is always higher than, or the same as, the geometric mean.
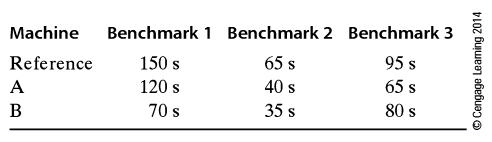
The SPEC benchmarks present results with respect to a standard machine by normalizing the benchmarks. That is, a set of benchmarks is run on a reference machine and the times obtained for each of the benchmarks. When a test machine is benchmarked, its times are divided by the results on the
Two computers and a reference machine produce the following results. Present the results in a normalized form and provide benchmarks for machines A and B. Machine Reference A B Benchmark 1 Benchmark 2 Benchmark 3 65 s 150 s 95 s 65 s 40 s 120 s 80 s 70 s 35 s Cengage Leaming 2014
In 2013, a woman with a small business at home is going to buy a desktop computer to handle her correspondence and diary/calendar, to allow her to email colleagues and to deal with her tax. Being a sensible person, she decides to get the best computer she can afford and Google's 'computer
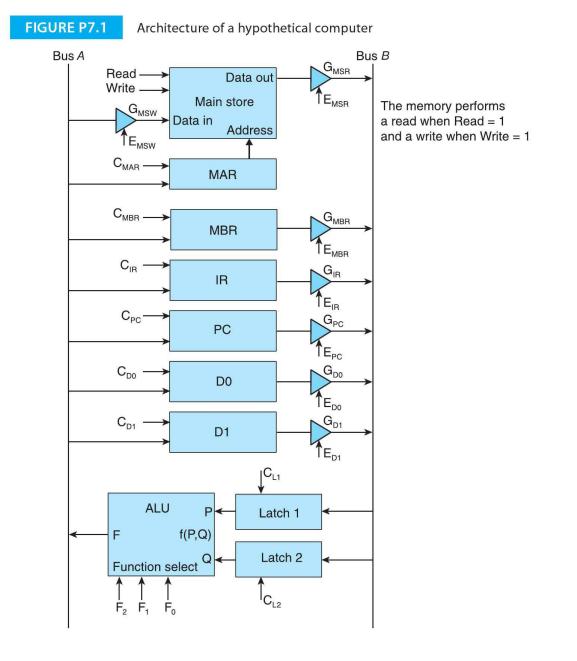
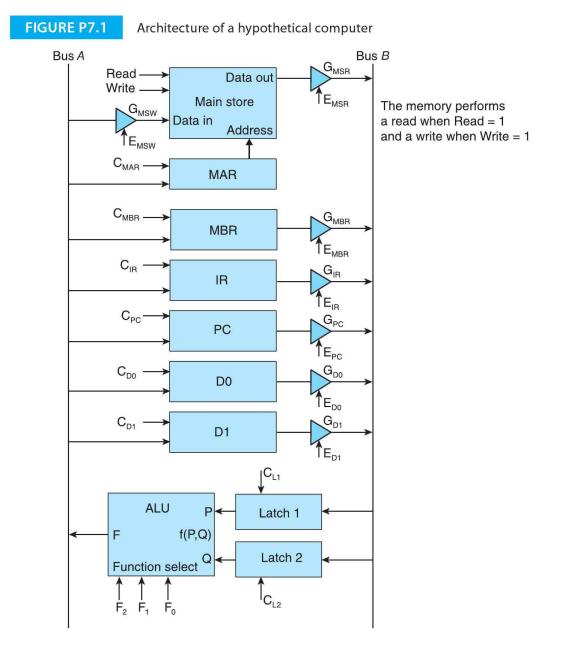
This question asks you to implement register indirect addressing. For the architecture of Figure P7.1 , write the sequence of signals and control actions necessary to execute the instruction ADD (Dl), DO that adds the contents of the memory location pointed at by the contents of register Dl to
This question asks you to implement memory indirect addressing. For the architecture of Figure P7.1, write the sequence of signals and control actions necessary to execute the instruction ADD [M] , DO that adds the contents of the memory location pointed at by the contents memory location M to
For the microprogrammed architecture of Figure P7.l, define the sequence of actions (i.e., microoperations) necessary to implement the instruction TXPl (DO)+' Dl that is defined as:Explain the actions in plain English and as a sequence of enables, ALU controls, memory controls and clocks. This is
Why was microprogramming such a popular means of implementing control units in the 1980s?
Why is microprogramming so unpopular today?
Figure P7.12 from the text demonstrates the execution of a conditional branch instruction in a flow-through computer. The grayed out sections of the computer are not required by a conditional branch instruction. Can you think of any way in which these unused elements of the computer could be used
What modifications would have to be made to the architecture of the computer in Figure P7.12 to implement predicated execution like the ARM? FIGURE P7.12 PC_MPLX 00 014 10 11 BRA Target where the target address is [PC]+4+4 L MPLX BRA Target PC 0 Z PC_MPLX control PC Branch Jump Architecture of a
What modifications would have to be made to the architecture of the computer in Figure P7.12 to implement operand shifting ( as part of a normal instruction) like the ARM? FIGURE P7.12 PC_MPLX 00 01 BRA Target where the target address is [PC]+4+4*L MPLX 10 11 PC Jump 0 Z PC_MPLX control BRA
Derive an expression for the speedup ratio (i.e., the ratio of the execution time without pipelining to the execution time with pipelining) of a pipelined processor in terms of the number of stages in the pipeline m and the number of instructions to be executed N.
A processor executes an instruction in the following six stages. The time required by each stage in picoseconds (1,000 ps = 1 ns) is given for each stage. a. What is the time to execute an instruction if the processor is not pipelined? b. What is the time taken to fully execute an instruction
Both RISC and CISC processors have registers. Answer the following questions about registers. a. Is it true that a larger number of registers in any architecture is always better than a smaller number? b. What limits the number of registers that can be implemented by any ISA? c. What are the
Someone once said, "RISC is to hardware what UNIX is to software'? What do you think this statement means and is it true?
What are the characteristics of a RISC processor that distinguish it from a CISC processor? Does it matter whether this question is asked in 2015 or 1990?
What, in the context of pipelined processors, is a bubble and why is it detrimental to the performance of a pipelined processor?
To say that the RISC philosophy was all about reducing the size of instruction sets would be wrong and entirely miss the point. What enduring trends or insights did the so-called RISC revolution bring to computer architecture including both RISC and CISC design?
There are RAW, WAR, and WAW data hazards. What about RAR (read-after-read)? Can a RAR operation cause problems in a pipelined machine?
Consider the instruction sequence in a five-stage pipeline IF, OF, E, M, OS: Instructions 1 and 2 will create a RAW hazard. What about instructions 3 and 4? Will they also create a hazard? 1. ADD r0, r1, r2 2. ADD r3, r0, r5 3. STR r6, [x7] 4. LDR r8, [17]
A RISC processor has a three-address instruction format and typical arithmetic instructions (i.e., ADD, SUB, MUL, DIV etc). Write a suitable sequence of instructions to evaluate the following expression in the minimum time:Assume that all variables are in registers and that the RISC does not
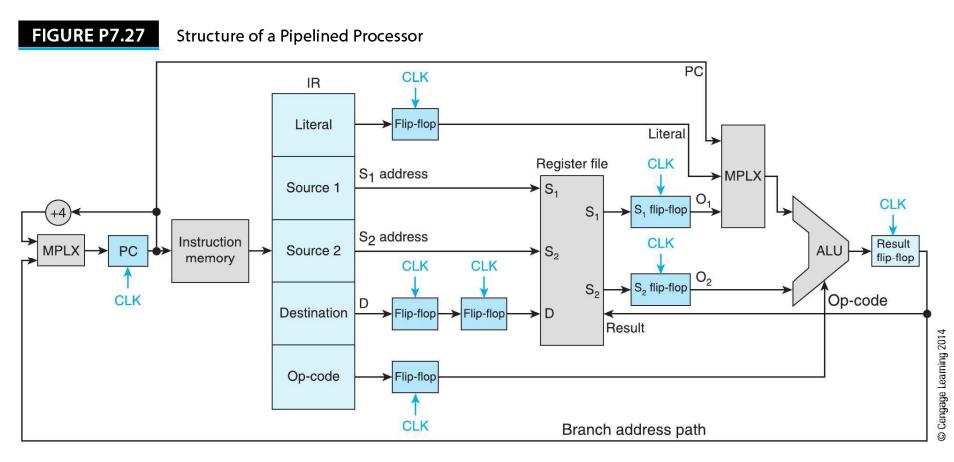
Figure P7.27 gives a partial skeleton diagram of a pipelined processor. What is the purpose of the flipflops (registers) in the information paths? FIGURE P7.27 +4 MPLX PC CLK Structure of a Pipelined Processor Instruction memory IR Literal Source 1 Source 2 Destination Op-code CLK Flip-flop S
Explain why branch operations reduce the efficiency of a pipelined architecture. Describe how branch prediction improves the performance of a RISC processor and minimizes the effect of branches?
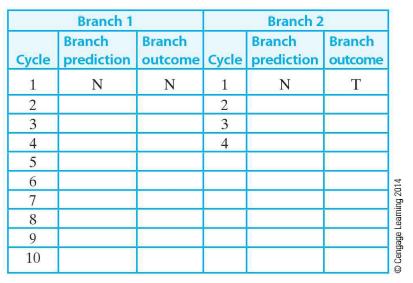
Assume that a RISC processor uses branch prediction to improve its performance. The following table gives the number of cycles taken for predicted and actual branch outcomes. These figures include both the cycles taken by the branch itself and the branch penalty associated with branch
RISC processors rely (to some extent) on on-chip registers for their performance increase. A cache memory can provide a similar level of performance increase without restricting the programmer to a fixed set of registers. Discuss the validity of this statement.
RISC processors best illustrate the difference between architecture and implementation. To what extent is this statement true ( or not true) ?
Consider the following code:The processor has a five-stage pipeline F O E M S; that is, instruction fetch, operand fetch, operand execute, memory, and operand write back to register file. a. How many cycles does this code take to execute assuming internal forwarding is not used? b. How many
Why do conditional branches have a greater effect on a pipelined processor than unconditional branches?
Describe the various types of change of flow-ofcontrol operations that modify the normal sequence in which a processor executes instructions. How frequently do these operations occur in typical programs?
What is branchless computing?
What is a delayed branch and how does it contribute to minimizing the effect of pipeline bubbles? Why are delayed branch mechanisms less popular then they were?
A pipelined processor has the following characteristics: Estimate the average cycles per instruction for this processor. Loads Load stall (load penalty) Branches Probability a branch is taken Branch penalty on taken RAW dependencies RAW penalty 18% 1 cycle 22% 80% 3 cycles 20% of all
What is the difference between static and dynamic branch prediction?
A processor uses a 2-bit saturation-counter dynamic branch predictor with the states strongly taken, weakly taken, weakly not taken, and strongly not taken. The symbol T indicates a branch that is taken and an N indicates a branch that is not taken. Suppose that the following predicted sequence of
The following sequence of branch outcomes is applied to a saturating counter branch predictor TTTNTTNNNTNNNTTTTTNTTTNNTTTTNT. If the branch penalty is two cycles for an incorrectly predicted branch, how many additional cycles does the system incur for the above sequence of 30 branches? Assume that
Consider the 4-bit saturating counter as a branch predictor with 16 states from 1111 to 0000? Describe in words the circumstances where such a counter might be effective.
Draw the state diagram of a branch predictor using a 3-bit saturating counter? Under what circumstances do you think such a predictor might prove effective?
The following code is executed by an ARM processor: Assume that a 1-bit branch predictor is used for both branch 1 and branch 2 and that both predictors are initially set to N. Complete the following table by running through this code. Repeat the same exercise with the same initial conditions but
A processor executes all non-branch instructions in one cycle. This processor implements branch prediction, which incurs an additional penalty of 2 cycles if the prediction is correct and 4 cycles if the prediction is incorrect. a. If conditional branch instructions occupy 15% of the instruction
A computer has a branch target buffer, BTB. Derive an expression for the average branch penalty if the following apply. • A branch not in the BTB that is not taken incurs a penalty of O cycles. • A branch not in the BTB that is taken incurs a penalty of 6 cycles. • A branch in the BTB that
A RISC processor implements a subroutine call using a link register (i.e., the return address is saved in the link register).The cost of a call is 2 cycles and the return costs 1 cycle. If a subroutine is called from another subroutine (i.e., the subroutine is nested), the contents of the link
Why is the literal in the op-code sign-extended 9 before use (in most computer architectures)?
Why is the address offset shifted two places left in branch/jump operations in 32-bit RISC-like processors?
Assume a five-stage pipeline (instruction fetch, operand fetch, execute, memory, write-back). For the following code show any stalls and indicate where operand forwarding would be needed. ADD R9, R9, R8 MUL R1, R2, R3 LDR R5, (4, R1) SUB R5, R5, R1 ADD R7, R8, R9 MUL R7, R1, R5
Superscalar processing could be added to any existing processor without having to recompile source code. Why?
The performance of a computer can be expressed as the time taken to execute a task. That time can is given by Many factors affect the design of a processor; for example, technology, ISA, the compiler, pipelining, superscalar technology. Discuss how these factors affect the above equation. Time
If a VLIW form of an existing processor were to be produced, why would the source code have to be recompiled?
Showing 500 - 600
of 1390
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Step by Step Answers


![movq mov mov Next: movq mm1, c cx, 3 esi, 0 mm0, x [esi] paddb mm0, mm 1 movq x[esi), mm0 add loop Next esi,](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/3/4/43865ab7126a93911705734434459.jpg)





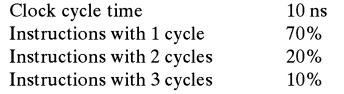


![for (i = 0; i < 100; i++) { * s+12345 } P = q x = 0.0; for (j = 0; j < 60000; j++) { X = x + A[j] * B [j]; }](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/0/74465ab89c80d2111705740743573.jpg)
![[D1] [DO] 2 [M [DO]] + 1 [DO] + 1](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/4/77865ab998a05be41705744777732.jpg)
![FIGURE P7.12 PC_MPLX BRA Target where the target address is [PC]+4+4*L MPLX BRA Target PC 00 PC 01 Branch 10](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/4/99965ab9a67031ce1705744997420.jpg)
![FIGURE P7.12 PC_MPLX 00 014 10 11 BRA Target where the target address is [PC]+4+4 L MPLX BRA Target PC 0 Z](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/5/07165ab9aaf6f2111705745069343.jpg)
![FIGURE P7.12 PC_MPLX 00 01 BRA Target where the target address is [PC]+4+4*L MPLX 10 11 PC Jump 0 Z PC_MPLX](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/5/16365ab9b0bde8761705745162808.jpg)

![1. ADD r0, r1, r2 2. ADD r3, r0, r5 3. STR r6, [x7] 4. LDR r8, [17]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/5/86765ab9dcb848891705745867066.jpg)
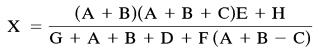

![LDR r1, [16] ADD r1, r1, #1 LDR ADD ADD r2, [r6, #4] r2, r2, #1 r3, rl, r2 ADD r8, r8 , #4 STR r2, [r6, #8]](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/7/4/8/25765aba721eea321705748257628.jpg)