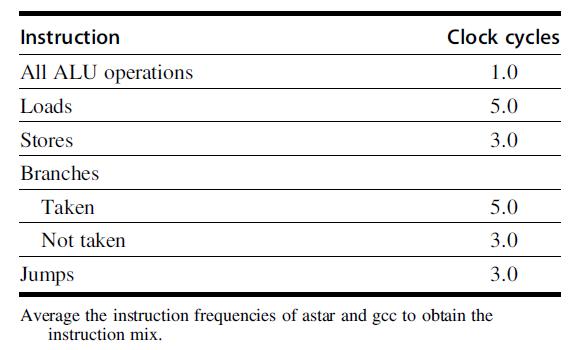
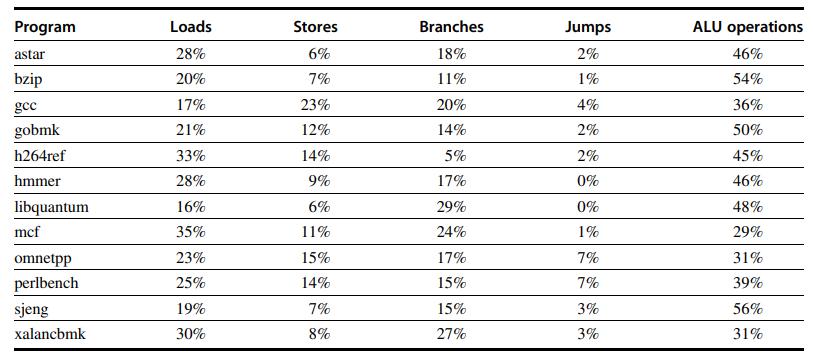
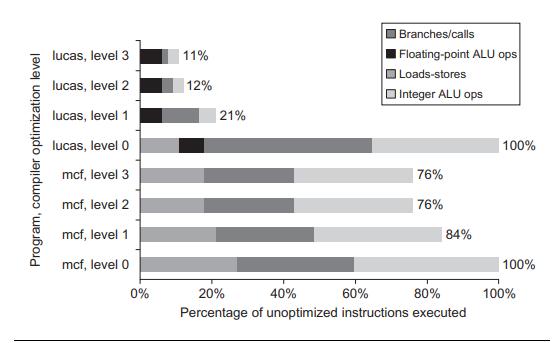
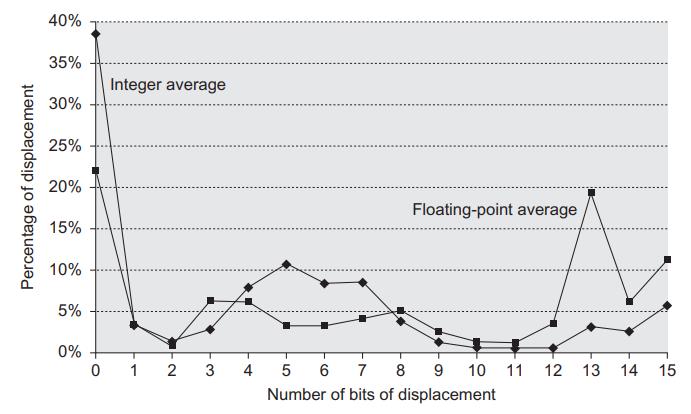
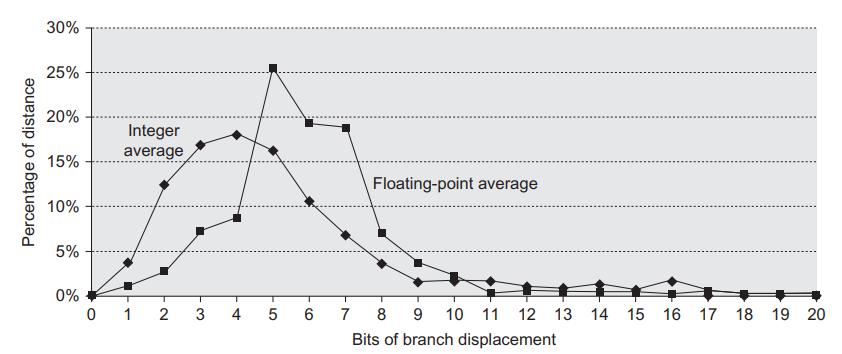
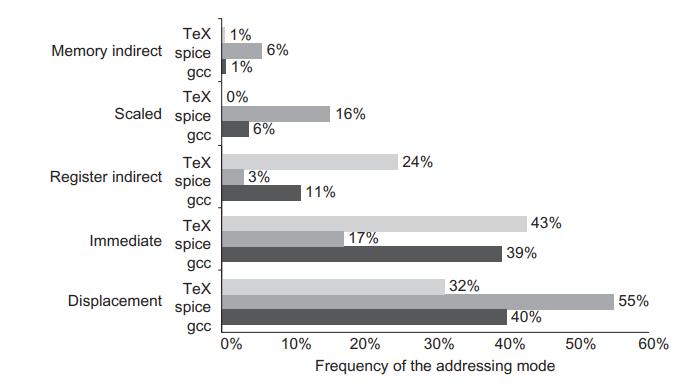
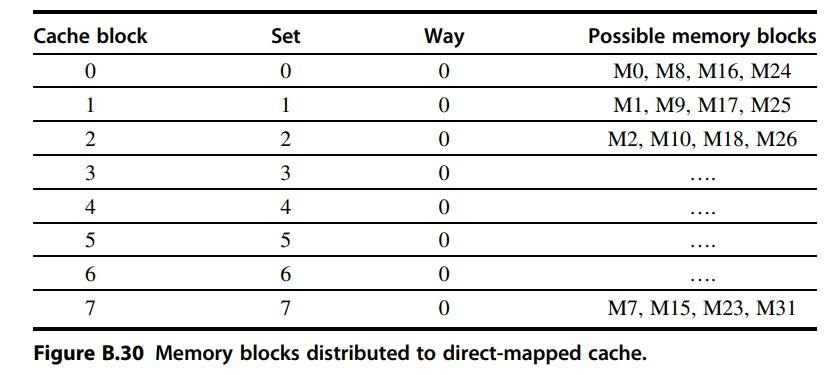
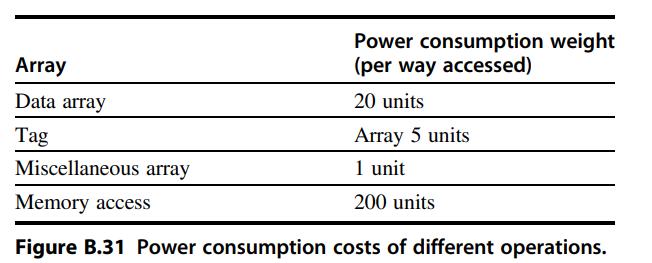
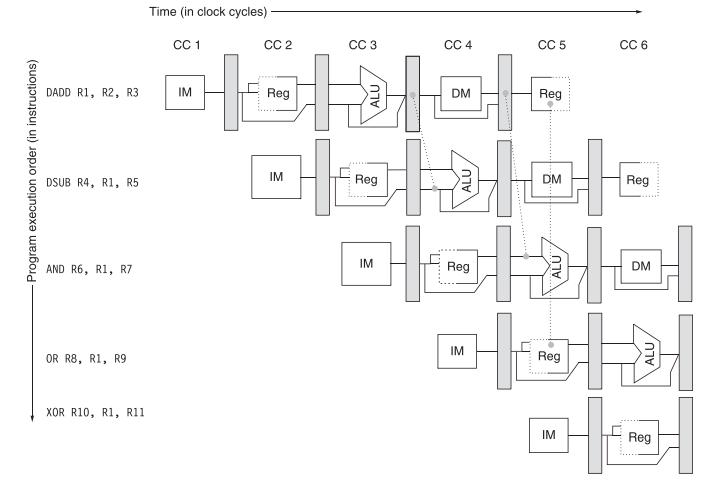
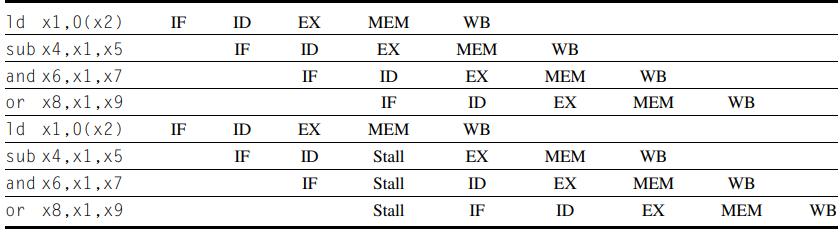
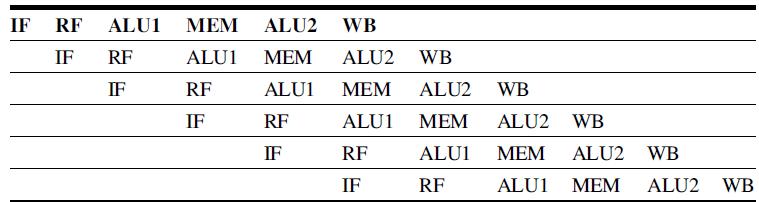
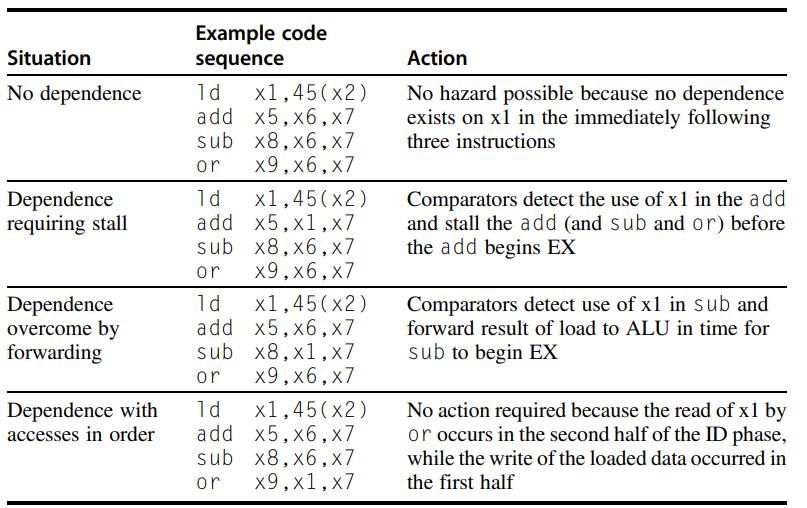
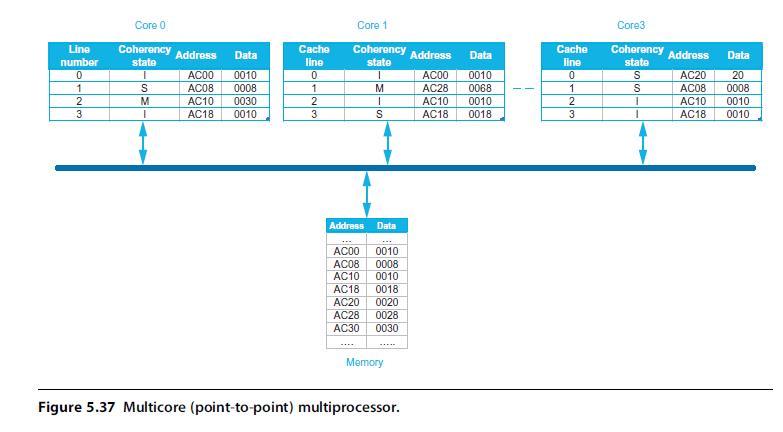
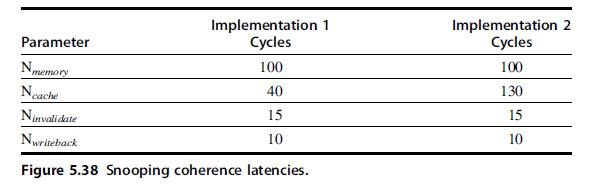
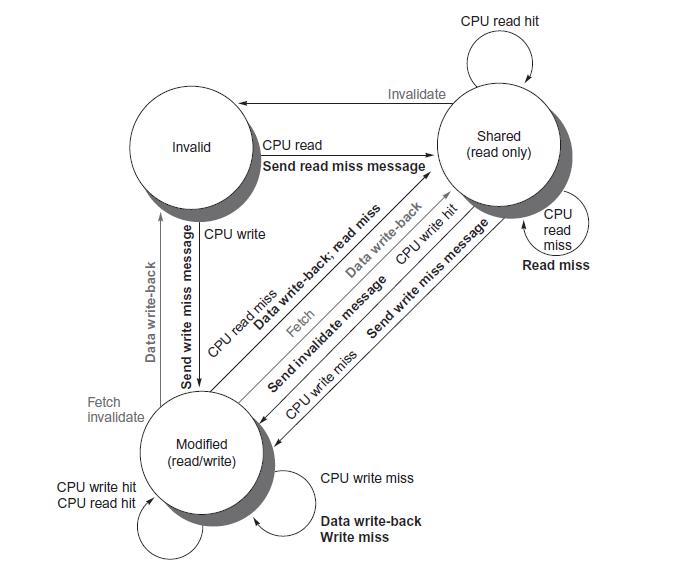
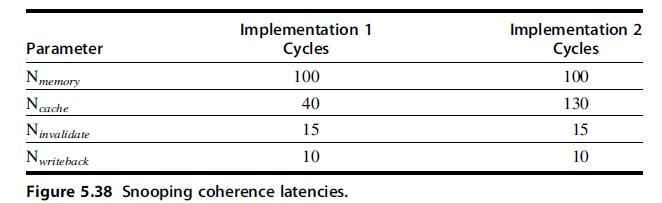
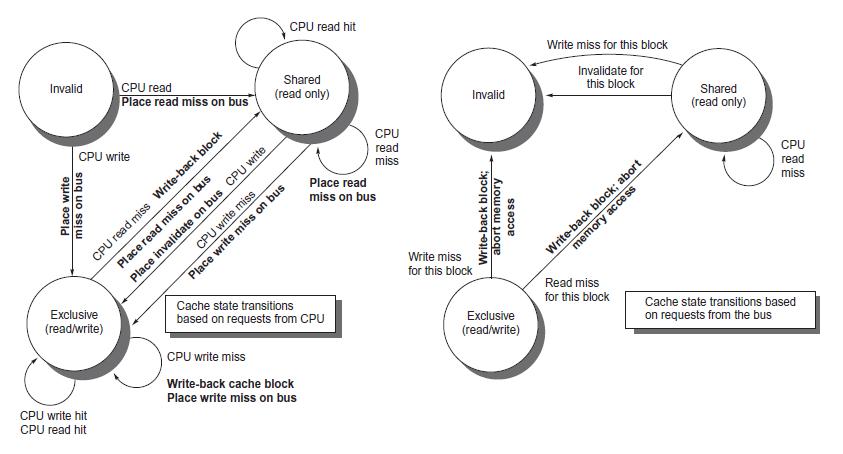
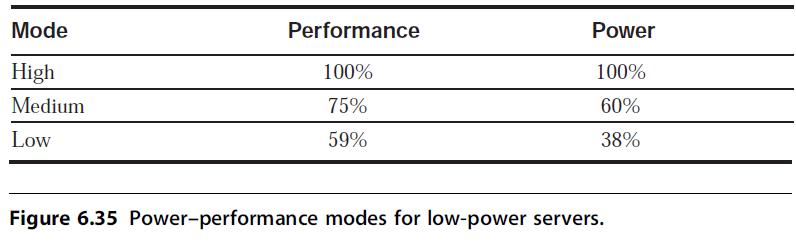
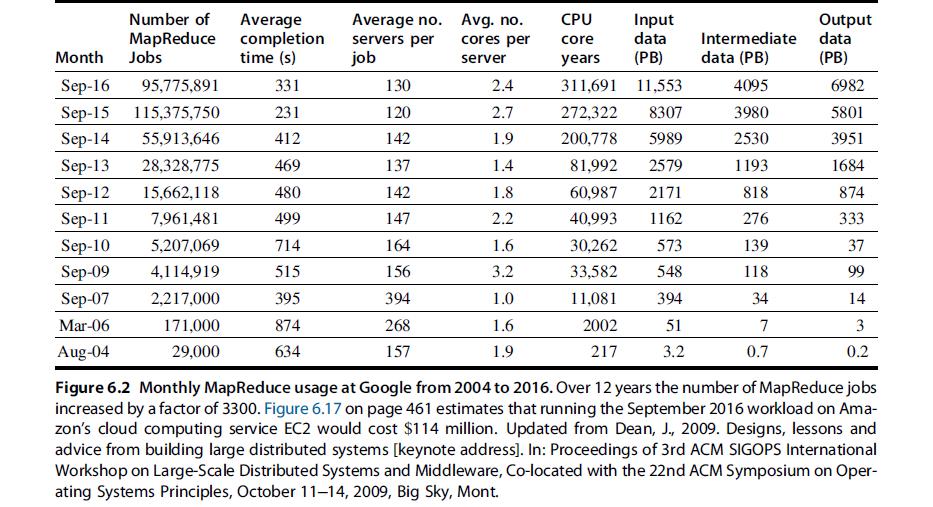
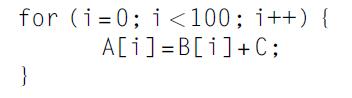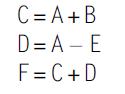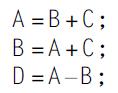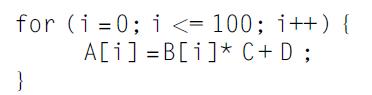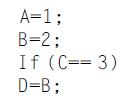Computer Architecture A Quantitative Approach 6th Edition John L. Hennessy, David A. Patterson - Solutions
Discover the ultimate resource for mastering "Computer Architecture: A Quantitative Approach, 6th Edition" by John L. Hennessy and David A. Patterson. Our platform offers an extensive collection of solved problems and step-by-step answers, ensuring you grasp every concept. Access a comprehensive solution manual and answers key to enhance your understanding. Whether you're looking for chapter solutions or test bank questions and answers, our instructor manual has you covered. Delve into the textbook with ease, and enjoy the convenience of solutions available in a free download PDF format. Perfect for students needing online guidance.