Computer Organization And Architecture Themes And Variations 1st Edition Alan Clements - Solutions
Discover comprehensive solutions for "Computer Organization And Architecture Themes And Variations 1st Edition" by Alan Clements. Our platform offers an extensive collection of questions and answers, including an online answers key and detailed step-by-step solutions. Access the solution manual, solved problems, and chapter solutions in convenient PDF format for free download. Whether you're looking for a test bank or an instructor manual, our textbook resources provide everything you need to succeed. Enhance your understanding with our expertly crafted answers and ensure your academic success with these invaluable tools.
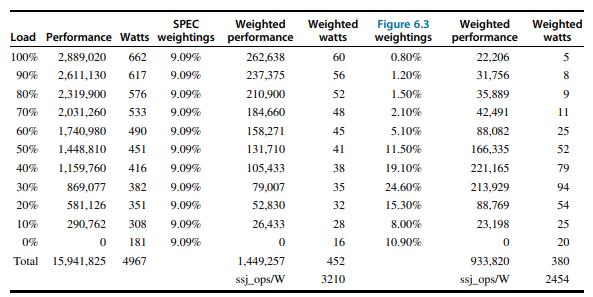
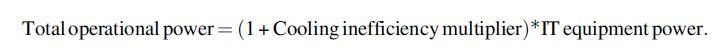
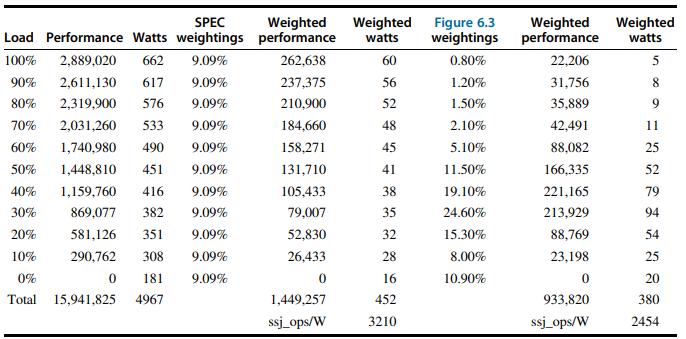




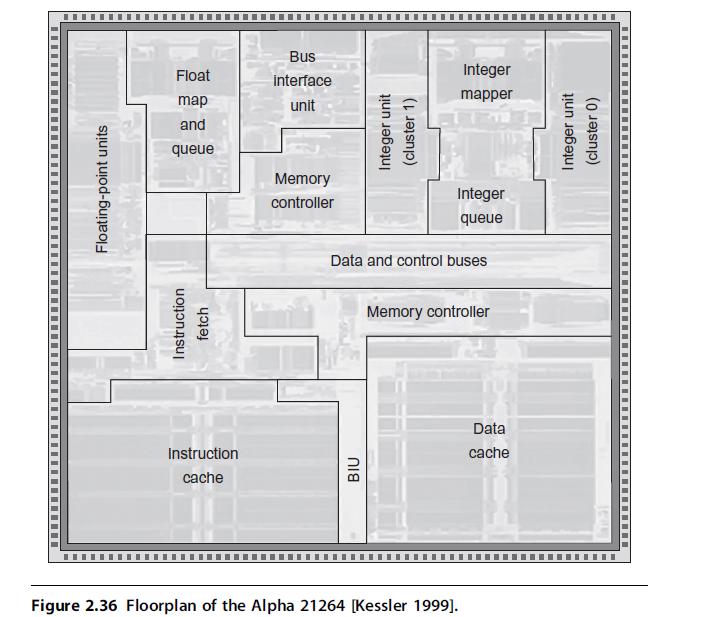


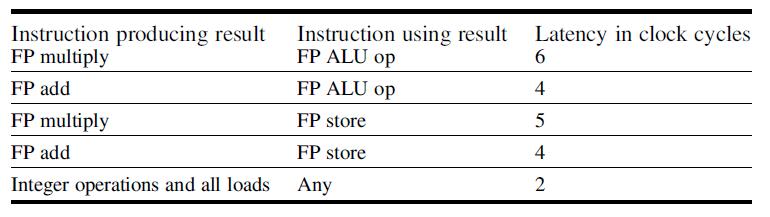
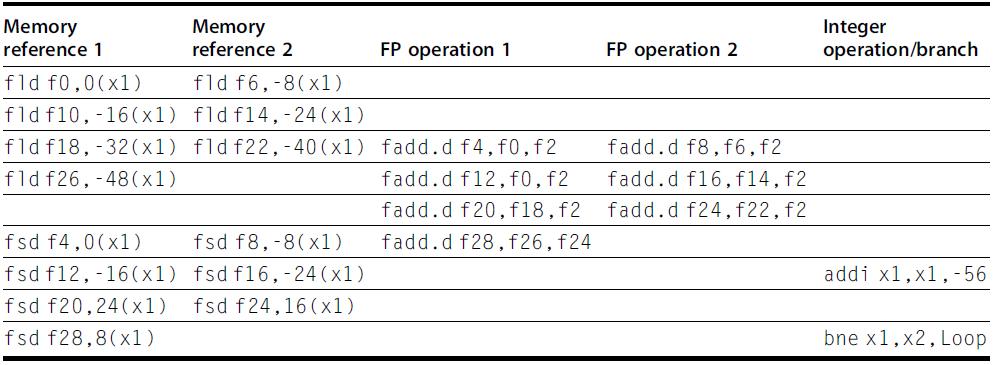

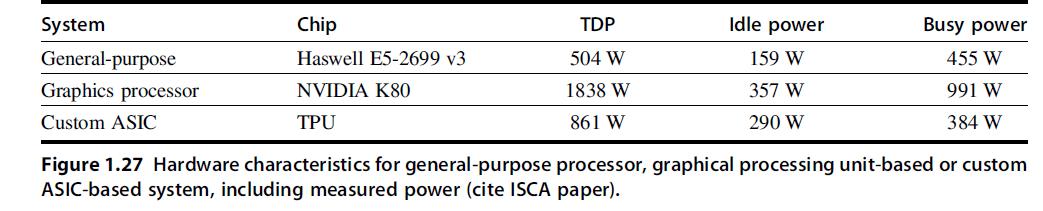
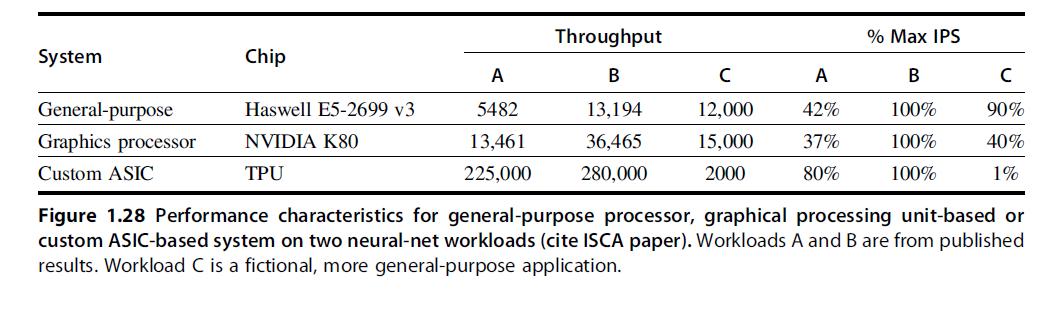
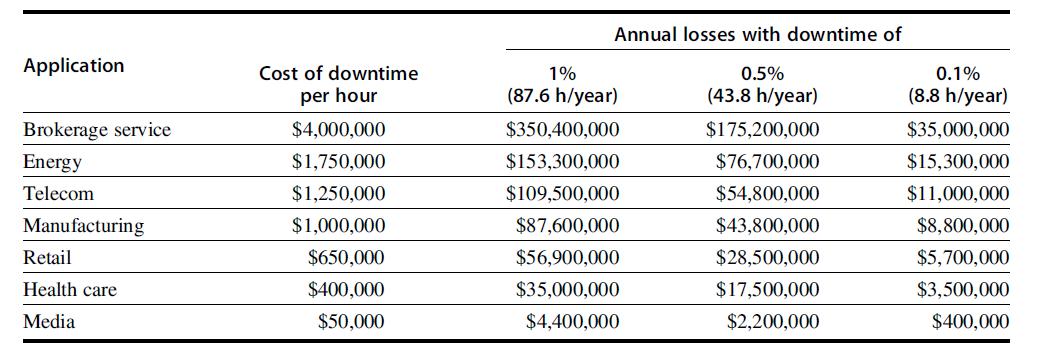
![LDR LDR ADD SUB MUL STR r1, [12] r3, [14] r6, rl, r3 r7, rl, r3 r3, 16, 17 [x2], r3](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/9/0/8/42465ae18c8802101705908419743.jpg)
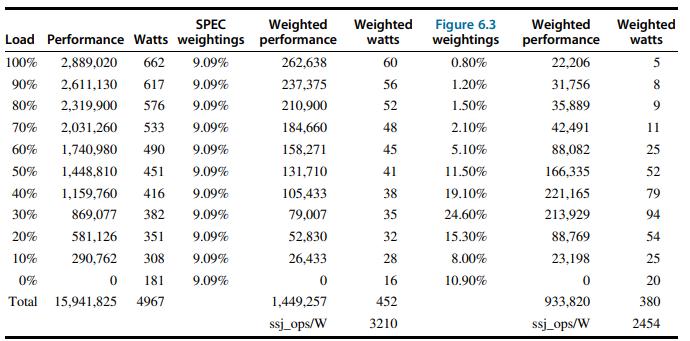
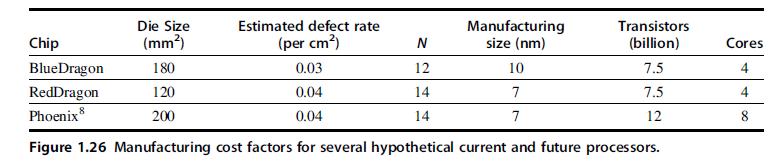
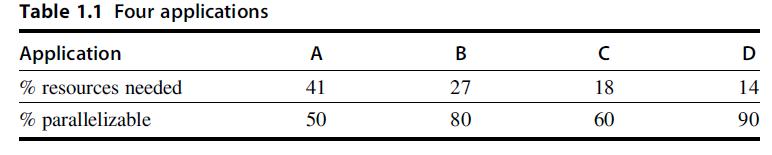
![for (i = 0; i < 100: i++) { if (X [i] = Y[i]) } Y[i] else X [i] = Y [i] + X [i] 1; 1;](https://dsd5zvtm8ll6.cloudfront.net/images/question_images/1705/9/0/8/69465ae19d6dbf841705908694998.jpg)

